This feedback really belongs in this thread, so I’m answering here.
As a special treat for you I ran that simulation on the original settings.
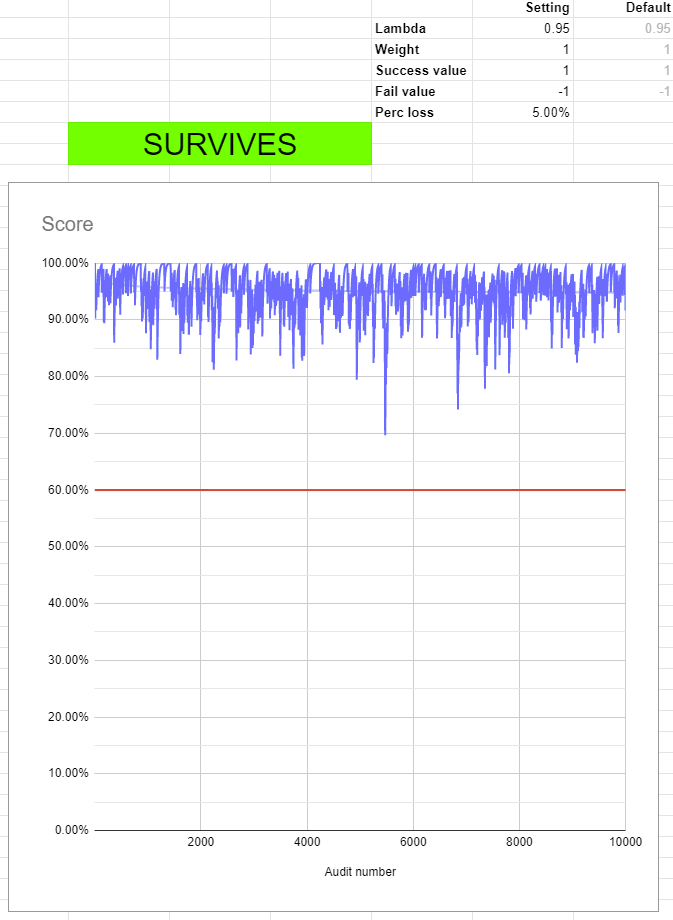
So yeah, that fits. The erratic nature of these settings causes fairly deep peaks from time to time. But it’s infrequent and your node would indeed survive as you’ve seen.
To verify that I also ran 100 million simulated audits in python.
Score = 0.9678485255896826 after 100000000 audits
No argument there. In fact the new publicly available stats show that none of the satellites have ever lost a single segment. But being more strict, yet fair with nodes gives more room to for example reduce the expansion factor, which with the new pricing might help lower the negative impact on payouts. It’s best to finely tune all aspects to get the most out of the entire system. Additionally, my primary goal was to get rid of the erratic and unpredictable nature of this score as it really doesn’t tell the node operator how well the node is doing at all right now.