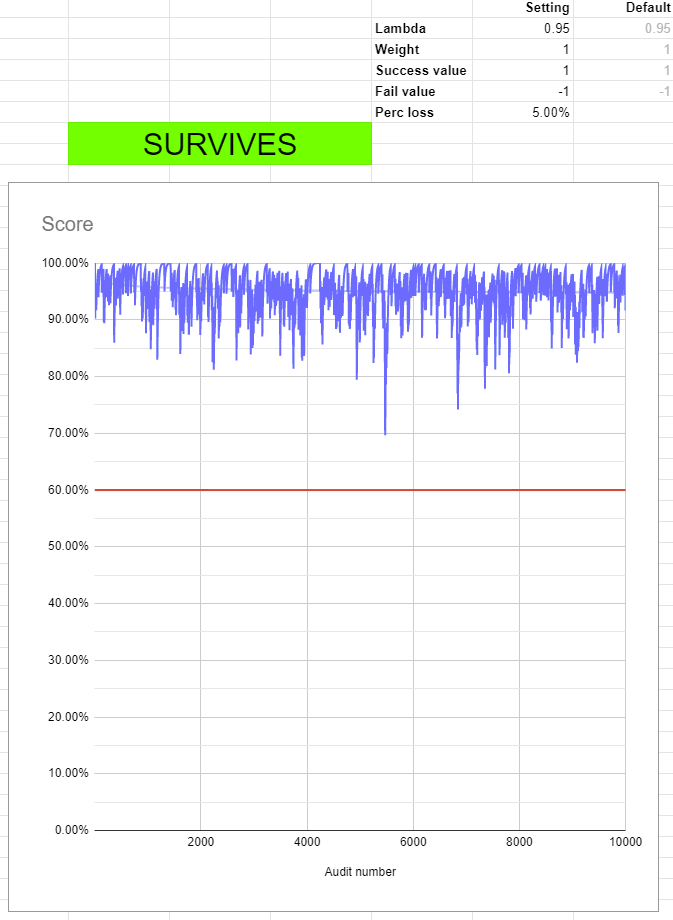
In a recent topic the subject of data loss and resulting audit scores and disqualification came up. It triggered me to do some research into how the current system works and what fluctuations in scores are to be expected.
In order to investigate I created a simulator that simulates audits and the resulting scores based on an average data loss percentage. This is what a 15% data loss looks like with the current formulas:

This approach has several issues:
- The scores are extremely volatile and unpredictable
- Disqualification is inconsistent and the timing is entirely determined by random “luck”
- A node operator might look at the score and see it increasing and assume issues are solved
- Nodes with over 10% of data lost are allowed to survive for very long periods of time (nearly indefinitely)
- After failed audits, the score recovers just as fast, so failures never really stick
Now since this system works based on random audits, some fluctuations in scores are to be expected. But the approach used with a beta distribution actually allows you to tune for this. So, I would suggest raising the lambda value (which represents the “memory” of this process or how heavily the previous score counts in the newly calculated score) significantly to 0.999.

That fixes consistency, but now the node with 15% loss will definitely survive. To fix this we can alter the change in value when you fail an audit. I suggest changing that from -1 to -20. This counts failures much more heavily than successes. It does introduce a little more fluctuation back into this value, but not nearly as much as it used to be.
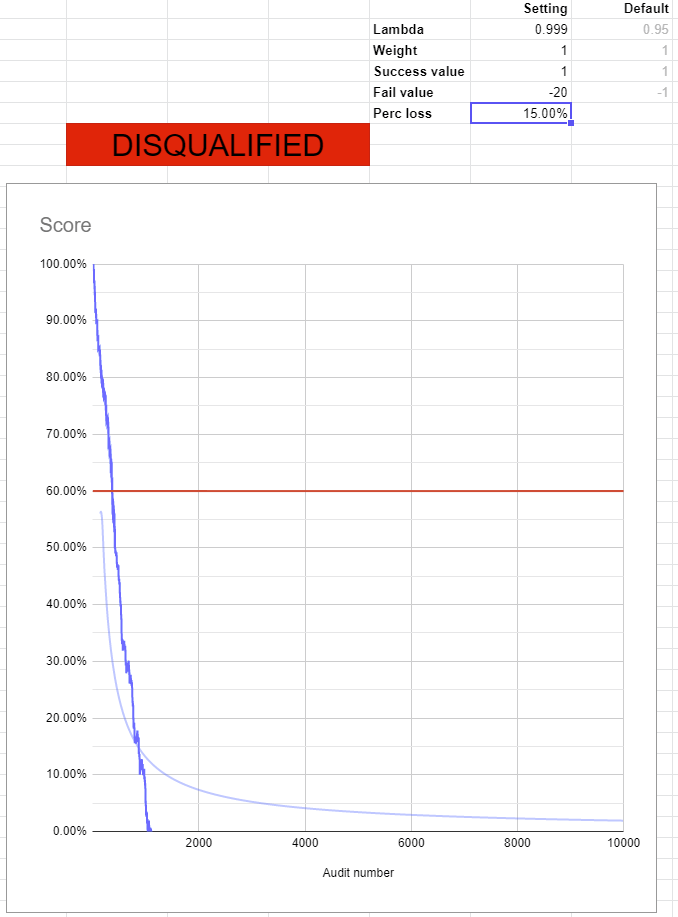
uh oh… our node with 15% data loss isn’t doing so well. But… should it do well? It lost 15% of data. It seems pretty reasonable to disqualify that node. In fact the numbers I suggest are tuned to allow for about 2% data loss maximum.

That looks more like it. There is still some randomness to it, but it is controlled. A node on the verge of getting disqualified won’t have scores jumping from 60% to 100% and back all the time, but instead the score at any time actually gives a good representation of the nodes data quality.
A public copy of the sheet I used can be found here: Storj Audit Score Simulator PUBLIC - Google Sheets
Anyone can edit, so please be respectful. Please don’t destroy the sheet. If someone is testing with tweaking the numbers, wait for them to finish or copy the sheet to your own Google account to play with it. After updating the numbers at the top it takes a while for all the values and the graph to be updated. To run a new simulation with the same numbers, just click an empty sell and press delete.
Now testing with 10000 audits is nice, but it doesn’t give the whole picture. I wanted to have a better idea about what could be expected long term. So I wrote a small python script to check with 100 million audits.
from random import random
l = 0.999
w = 1
sv = 1
fv = -20
dq = 0.6
loss = 0.02
a = 1/(1-l)
b = 0
for n in range(100000000):
if random() < loss:
v = fv
else:
v = sv
a = l*a + (w*(1+v))/2
b = l*b + (w*(1-v))/2
score = a / (a+b)
if score < dq:
break
print("Score = {} after {} audits".format(score, n+1))
With 2% data loss the node tends to survive.
Score = 0.7858662201182666 after 100000000 audits
With 2.1% it generally gets disqualified at some point
Score = 0.5999645458940869 after 12795072 audits
And of course the higher the data loss the faster the node gets disqualified.
RECAP OF SUGGESTED CHANGES
So I suggest changing Lambda to 0.999 and the audit failure value to -20.
So lets take a look at my original issues with the current formula and see how the new formula deals with it:
- The scores are extremely volatile and unpredictable
Scores are now more stable and approach actual node quality over time - Disqualification is inconsistent and the timing is entirely determined by random “luck”
Disqualification now consistently happens based on amount of data lost and the timeframes are more consistent - A node operator might look at the score and see it increasing and assume issues are solved
The score at any time gives a good indication of how the node is doing now. Momentary fluctuations will still happen, but deviations from the mean are small. - Nodes with over 10% of data lost are allowed to survive for very long periods of time (nearly indefinitely)
Nodes with 3% or more data loss will now get disqualified promptly - After failed audits, the score recovers just as fast, so failures never really stick
Recovering from a bad score now takes 20x as long as dropping the score on a failed audit does. As a result failed audits are more sticky and issues are represented for longer in the score. Therefor intermittent problems don’t go unnoticed.
Other considerations:
- Raising the lambda value causes scores to not drop as fast as they did before, this could lead to really bad nodes not being disqualified as fast
While this is true, it doesn’t take a lot longer, because this effect is largely compensated by the much higher impact of audit failures on the score. It takes about twice as long on average for nodes with 40%+ data loss to be disqualified. But the tradeoff is that nodes with 3%+ data loss do get disqualified. This should lead to a more reliable node base on aggregate. - Implementing a change like this could disqualify many nodes in a short period of time.
To compensate for this I recommend first introducing this change with an audit fail value of -5 and incrementally lower it to -20 over time while keeping an eye on repair impact.
Bonus suggestion
Now that there is a more consistent representation of node data quality, we can actually do something new. We could mark the pieces of a node with an audit score below the warning threshold (for example 95%) as unhealthy. And at the same time lower the incoming traffic for that node (they could be part of the node selection process for unvetted nodes). This will result in data for that node slowly being repaired to other nodes, potentially reducing the troublesome data and fixing it, while at the same time lower the risk of new data stored on that node getting lost. This will rebalance good and bad data on the node and will allow nodes that have resolved the underlying issue to slowly recover, while at the same time nodes that still have issues will keep dropping in score anyway and fail soon enough. This also provides an additional incentive to keep your node at higher audit scores to keep all ingress and prevent losing data to repair.