As far as I know, if the disk stops responding (or the kernel IO system freezes), the node will keep running, timing out all requests and, with the current system, be disqualified within 4 hours.
I think that 4 hours is way too short time for this and reducing it even more is wrong.
Unless the node CAN shut down if it gets multiple IO timeouts in a row, but then if 8 failed audits lead to DQ, then the node has to pretty much shut down after the first IO timeout (so that the node operator would have 7 attempts, though more likely 3, to restart it).
4 Likes
yeah changing these kinds of things are / can be very dangerous, if done without enough understanding of the future behavior.
you say its unlikely to affect older nodes… but i have a node on which i lost like a few minutes worth of files because i accidentally ran an rsync --delete instead of just rsync after a migration.
i know exactly how much time of ingress was lost, and still the score was all over the place.
that node’s audit score tho stable, would until recently vary by about 5%…
it’s been a while since i check how much flux it has now… but i will…
and that is a node storing millions of files, and its not like it unheard of that nodes get DQ by random chance… and that’s where my problem lies with the current audit / DQ configuration.
it jumps around, and really that is just a math thing, there is no good reason it should do that…
there is nothing wrong with a node getting DQ fast, but seeing as DQ is a hard limit and if the node hits it… having the score jump up and down is just unacceptable…
and for those of us with nodes ranging in the years old, it is downright torture to watch…
granted i don’t have that problem, but i would like to know that some day in the future my node won’t just end up being DQ because of a number that doesn’t truly reflect the state of the data.
If this is the case, it can be fixed fairly easily. There’s a regular “writability check” that the node does to make sure that its data mount point is still present and writable. If the node fails that check, it will shut down. If that doesn’t already have a timeout, we can add one.
I’m not following this- are you responding to something I said? The only thing I said about older nodes was that the grace period would not apply to them.
I should really emphasize though that the reputation score is, by absolute necessity, probabilistic, and it has to swing both above and below the true data-loss measure. If it doesn’t dip fairly quickly to negative audits, then bad nodes will affect the network for too long.
1 Like
I think I can respond to all of these by saying that I may have made the wrong assumption that alpha would be initialized at 1/(1-lambda). If that is not the case there may be some extra considerations indeed. With alpha initially at 1 you do indeed get some volatility early on. But that still stabilizes quite quickly. Here’s an example with 2% data loss.
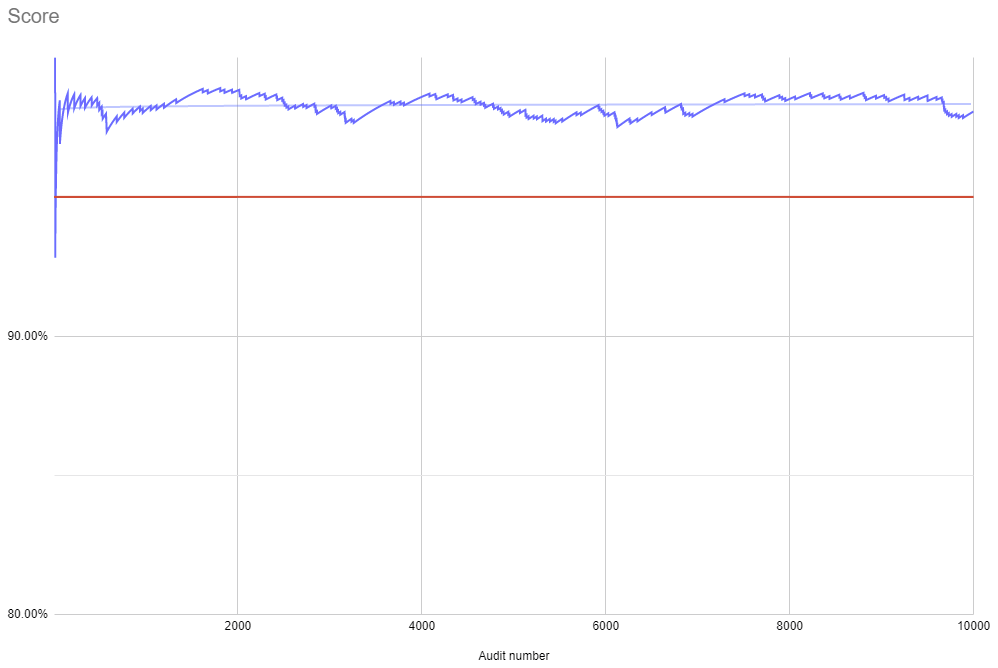
You can see that the first hundred audits or so result in quite volatile score changes. In this case leading to disqualification of a 2% loss node. However, this would happen while the node is still in vetting and perhaps some additional scrutiny is warranted during that time anyway.
However, I would argue that this initialization at 1000 isn’t essential just because it makes the first few hundred audits a little less stable. By the time nodes get vetted the score will have stabilized enough to be a reliably indicator. And fluctuations during vetting can be easily explained by just saying that the score doesn’t have enough data to stabilize yet and that’s exactly what the vetting period is for.
Any initialization of alpha is essentially giving the model a history that isn’t there yet. In this case even setting the value at 1 is akin to saying the node had 1 successful audit. Setting it to 1 is just a way of avoiding the initial division by 0 if you set it to 0.
Initializing both alpha and beta can be done with prior data if available as well. Say you know a node has had 100 successful audits an 2 failed. You could set alpha and beta to those values to seed the model with “perfect memory” over those stats. I don’t believe doing something like that breaks the model in any way.
I think this one was referring to the lambda change specifically. This change just reflects giving the model more memory. Instead of mostly counting recent reputation, you look a bit further back. Essentially what you’re doing is using a larger set of audit results going a bit further back to determine reliability. The number still represents the same estimate, but based on a longer period of time. As far as I’m aware, that is an entirely valid way to tune the beta reputation model.
Having build up a strong reputation is relative. If you look at the current model, the strongest reputation you can have is with an alpha at 20 and beta at 0. Nodes that come out of vetting after just 100 audits already have an alpha of 19.88 and beta of 0 as long as they haven’t failed any audits. So really that reputation isn’t all that meaningful. On good nodes, that would be a valid starting point to just start building an actually strong reputation with a higher lambda.
The problem comes in with nodes that are now looking pretty bad just because of nodes. Here’s an example of a worst case scenario node with 2% data loss, but due to bad luck having an alpha of 12 and a beta of 8 (so a score of the 60, the current DQ threshold).

The score still fairly quickly adjusts to where it should be considering the 2% data loss. But in this example it takes about 200 audits to get above the threshold and about 400 total to get close to where the score should be. (rough estimates)
So, you could raise lambda, wait a few months and then raise the threshold. Or raise the threshold gradually over time. Or raise both gradually over time to compensate. This would all depend on how much of a risk you would be taking when raising just the lambda and not the threshold for a period of time.
If it were up to me, I would probably choose to raise the lambda and use aggregate node stats to see when raising the threshold is reasonable and slowly raise it over time. If you would raise the threshold by 10 per month, there isn’t a vetted node that would get into trouble because of that unless they had more data loss than acceptable.
So 2 remarks on this. The volatile scores are a problem for node operators who try to figure out what is wrong with their node and use the scores to gauge whether they fixed an underlying issue. At the moment and to a lesser extent with your suggested changes, it is very well possible that they see the score increase and think everything is now all good and fixed. Only to see it plummet afterwards, or worse, to have stopped paying attention and be surprised by disqualification later.
As for the spikes downward, they aren’t because of a single audit, but because of several failed audits less spread out than they are on average. They are essentially noise because while the score should converge to the actual failure rate, the lack of memory means it’s too “distracted” by recent audits to actually settle there.
I agree that those should be solved separately, though I’m not confident all of them have been accounted for. Specifically a mount point disappearing while the node is running. I remember there is a periodic check for this, but as I previously mentioned, those 9 audits would happen in about 10 minutes on the largest satellite on my node. So unless that periodic check happens more frequently than that, it could be too late to prevent disqualification. As for suspension… if you quickly get into suspension, but you can also recover fairly quickly, I would personally be fine with that. Though I think you would also have to factor in the cost of that since it would still mark pieces as unhealthy and trigger repair.
I do think it’s vital to align how suspension and audit scores work, both to avoid abuse and to just make things simpler to understand for node operators.
Technically @thepaul’s suggestion would make it worse… but only by one audit. Currently DQ takes at least 10 failures in a row from a perfect reputation, with the changes that would be 9. The chance that your nodes survival hinges on that 10th one are pretty small. ![]() It’s just something I wanted to mention, but not necessarily a new issue with the newly suggested changes.
It’s just something I wanted to mention, but not necessarily a new issue with the newly suggested changes.
Agreed, are there any guidelines as to what would be considered too long for this though?
Ps. I feel like I should point out values between 0.987 and 0.999 exist. It’s not an either or situation. Compromise is possible to find the best of both worlds. I’m just using 0.999 as an example. And I quite like it because it seems with that setting you don’t see random swings larger than 1%. Which gives us a clear number to point at when trying to improve your node. Any improvement larger than 1% probably means you did something right. That would be slightly harder to explain if you have to say 1.5% for example.
1 Like
I want to clarify something before this discussion details because of confusing things.
There are currently 3 different reputation related scores
Audit score
Drops when known failures happen
Examples: Node responds to audit with: “I don’t have that piece”. Node responds to audit with corrupt or wrong data.
When below threshold: Permanent disqualification
Suspension score
Drops when unknown failures happen
Examples: Node responds with connection error or other unexpected error. Basically any error that isn’t missing or corrupt data.
When below threshold: Temporary suspension
Online score
Drops when nodes is offline
Examples: Offline node doesn’t respond to the audit at all.
When below threshold: Temporary suspension
So far we’ve mostly been talking about the first one, but @CutieePie, your concerns would almost all lead to the second and third.
While the suspension score mechanism should probably be updated as well, the fact that that would only cause temporary suspension means you can easily recover from that. When problems are solved.
From what I can tell, most of the temporary issues that could lead to audit scores dropping or disqualification are now being detected and I rarely see people complaining about disqualification without data loss. It doesn’t help that some people say they’ve been disqualified when they have actually been suspended.
So while I share your concern to some extent, I don’t want @thepaul’s suggestions to be misrepresented as worse, just because it doesn’t fix a pre-existing concern that really wouldn’t change much if these suggestions are implemented.
As for whether this is important now. Well I brought it up, so clearly I think it is. Inconsistent punishment of nodes based on random scores is demoralizing band discouraging. Especially if those same inconsistencies let other nodes with much worse situations slip through the cracks. Further more, a more reliable base of nodes leads to less overhead, less costs and perhaps to us reliable node operators being able to get a bigger slice of the pie. Making the whole system more reliable and efficient is good for everyone involved.
3 Likes
I don’t think this is quite accurate. It isn’t as straightforward as “alpha = number of successes, beta = number of failures”. A failure changes both alpha and beta, and so does a success. You are correct that giving a higher initial alpha is seeding a positive history, but within the model as we’ve been using it, (alpha+beta) converges up toward 1/(1-lambda) as time goes on. The closer alpha is to 1/(1-lambda), the stronger the reputation history. But when alpha or beta is already equal to or greater than 1/(1-lambda), I don’t know if it can still converge toward that point anymore. I should really just find all the numbers and graph it somewhere, but I’m out of time tonight. Maybe I can do that tomorrow.
I’m not sure that follows. 19.88 looks close to 20 on a linear scale, but that doesn’t mean there’s no relevance to the difference. The difference between 19.9 and 19.99 is somewhat like the difference between “2 nines” and “3 nines” of availability, because alpha should constantly get closer to (but never actually reach) 20 as the history grows. (In practice, it probably can reach 20, because floating point values can only handle so much precision ![]() )
)
Good idea! It wouldn’t have to be raised all at once.
The writability check happens every 5 minutes by default, and the readability check (making sure the directory has been correctly initialized as a storj data directory) happens every 1 minute. The readability check is the one that would help in that situation, so that’s good.
A really good point. I haven’t looked at the model assumptions for how long bad nodes can remain online in too long. I’ll try to find that. (The person who would normally know all of that, and who wrote the beta reputation model adaptation for Storj, left recently, so we’re trying to keep up without them.)
Certainly true. And 0.999 is fine with me, as long as we make sure bad actors are DQ’d quickly enough (for whatever that means).
It isn’t exactly, but it’s quite close. The only difference is that they also “forget” history. Let’s deal with current settings of lambda at 0.95 and a perfect long term node, so alpha at 20 and beta at 0.
What essentially happens when updating both alpha and beta is that the formula “forgets” 1-alpha (5%) of the historic count dropping it to 19 and adds on the new value of 1. The only reason it stays at 20 is because at that level alpha * (1 - lambda) = 1. So you basically forget 1 and add 1 at that point.
The same operation happens for beta, but with beta being 0 it ends up being 0 * lambda + 0. Which isn’t all that interesting.
So you could see alpha as the number of successes it remembers and beta as the number of failures it remembers. And both are always updated because every new signal makes it forget part of the older signals.
It will. Going by the same numbers used above. Say alpha somehow got to be 100 and beta 0. Because it still forgets 5%, the next successful audit would drop alpha to 95 because of that forgetting factor and add 1 for the new success, dropping it to 96 in total. It would again converge around 20 after enough audits.
I used just alpha as an example for these because it is easier to see, but this would also apply to the total of alpha + beta if there is a mix of signals. Because it loses 5% of the total preexisting values and always adds 1 to one or the other.
While you could technically say a node at 19.99 is a lot more reliable than a node at 19.88, it doesn’t really help you at all. This is because using the current numbers, that total will drop by 5% on a failure, which is essentially a drop of about 1 either way. Since that difference is so minute, the much more reliable node would probably still be disqualified after exactly as many failed audits as the less reliable one. Being close to 20 makes it a lot harder to go up even higher, but barely has an impact on how fast it will go down. (On the other end of the scale, when you’re near 0 it’s very hard to go further down, but easy to go back up)
Awesome, well that should cover it for now as long as I don’t get 10x as much data. But since this node already holds 16TB, that would be a great problem to have actually. ![]()
Oof yeah, I know how that feels. Seems like you’re managing quite well though.
I remember reading about someone getting disqualified in 4 hours because the system froze and the node would initiate a transfer, but then time out.
Returning corrupt data or returning “file not found” with a separate check if the drive is still plugged in usually means the node actually lost data. However, a time out does not really mean that. Then ode could be overloaded or frozen.
That would be nice, though I do not know it it would work in that particular instance. AFAIK, part of the kernel froze and anything trying to access the disk would just sit in D state forever. I don’t know if a timeout for that would work. If it would, tat would be great, since IIRC that particular node was disqualified in a few hours for failing audits (4 audit timeouts → 1 failure and in 4 hours the node got enough failures to be disqualified).
I am taking about this incident:
Yeah I do remember that. I actually ended up writing a blueprint after workshopping a possible solution for that with @Alexey in one of the topics where that happened. There’s also a suggestion for that here: Refining Audit Containment to Prevent Node Disqualification for Being Temporarily Unresponsive
I don’t think that can really be fixed by tuning the scoring alone though and the suggested changes shouldn’t really impact this (@thepaul’s numbers just drop the number of audits from 10 to 9, my suggested numbers would increase it, but not enough to actually fix it).
The suggestion I posted above could help fix that.
Alternatively, you could set a lambda value per node based on how much data it has. So that lambda = 1-(1/(number of audits for the node in past 48 hours)) with a minimum of 0.999 or one of the other suggested numbers. This would essentially translate it into a time based memory. But I don’t know if this data is easily available to the process that updates the scores.
This is correct as long as the repair service doesn’t step in. The audit job is doing random checks. The repair service is not. A storage node could get disqualified for losing 2% of the data. It just needs to be the oldest data that get repaired first. The satellite will see a high number of failed repairs and assume that the storage node has lost much more than 2% across its dataset.
One additional risk with the repair service is that multiple repair jobs can start at the same time. Let’s say 100 repair jobs start at the same time. It is unlikely that they all hit your node but it is possible. Now the 2% data loss will fail at the beginning and the 98% success is not completed yet. Successful repair jobs will take several minutes. I am concerned that this offset will get the storage nodes disqualified. The audit job doesn’t have this problem. Anyway, that might be a different topic for a different day. I just want to mention it here. The repair job will affect your calculations and most likely not in a positive way because the repair job doesn’t come with the great behavior the audit job has.
The timeout is still missing. Storage Nodes will get disqualified if the hard drive is just freezing. I had that situation on my system as well. The writability check will not notice it. The hard drive is still there. You can try to write a file on it. That operation will start but never finish and so the writability check starts but never fails.
We have written some unit tests here to simulate that situation: storagenode/monitor: add test verify readable & writable by nadimhq · Pull Request #4183 · storj/storj · GitHub
Note: The PR description is maybe not the best. The idea was that we have been waiting for someone to fix the code and to make that easier we provided some unit tests upfront. So far we didn’t find someone fixing the code.
1 Like
So this would be a problem if the node disproportionately lost older data vs newer data. Which isn’t that unlikely as the node has had more time to lose it. This would probably warrant adding some extra slack into the threshold. I don’t think it’s necessarily a major problem.
That’s a good point. Though I would say this is an already existing risk. And raising the lambda value will actually smooth out those temporary bumps more and mitigate some of that risk.
I think both issues you raise warrant being careful about when to actually raise the threshold and to what level. Would you consider them blocking for the proposed changes?
Not at all. As you said that problem is in production already and the current proposal doesn’t make it worse so we can move forward. It was more a reminder about possible issues we can look into up next.
1 Like
We don’t need to reset the scores as long as we bump the lambda.
I would suggest to use initial value alpha of 1/(1-lambda) and beta 0. It’s a safe choice any time as this is the convergence value of alpha + beta.
This would make the full calculation more predictable. The current mode (1 and 0) makes the initial failures slightly more serious.
For example: one failure after initial values (1,0) would cause 1->0.487 reputation drop while for a long time running node (and with 20,0 initial vales) it would be the desired 1->0.95
1 Like
One more note: Assuming the node is a long-running node (therefore alpha + beta already close to the convergence number) the calculation can be simplified as:
- multiply score (not alpha) with lambda in case of failure
- multiply with the difference between the score and 1 with lambda in case of success
This is exactly the same what we do (small differences apply until the alpha + beta is converge enough).
So there are two big consequences:
Increasing lambda will decrease the speed of healing the reputation score. As the gap between score and 1 is decreasing with lambda, lower reputation score heals faster. Reputation score closer to 1 heals slower (and we will restrict the playing area to there with increase the DQ)
The other interesting consequences of the current math is the following: the acceptable percentage of data loss doesn’t depend on lambda. It depends on from the reputation score. Lower reputation score can tolerate higher data loss. Again: the proposed solution is restricting the playing area with using only a small interval from 0-1.
For example: try to calculate the reputation from 0.65 with one failure and two success repeating.
Overall: I strongly agree that we should adjust the overall approach, not only the numbers. I think we should differentiate betwee the two hard DQ cases: wrong data and not-found data. While wrong data poisons the network and very dangerous, not-found is something which may be recoverable.
I had to read that second line a few times to get it, but I think you mean this?
- When failure: score = score * lambda
- When success: score = 1 - ( (1 - score) * lambda )
Which indeed would do exactly the same thing as the current beta reputation formula IF alpha is initialized at 1 / ( 1 - lambda). I don’t have any real objection to doing that, but that is like giving new nodes essentially a perfect long term reputation and adjusting from there.
I think I’m missing the point of this part, partially because the sentence in bold seems to be missing words or having too many.
The drop in score on a failure is smaller for lower scores. But that doesn’t mean that higher scores lead to disqualification quicker, since the drop is always relative to the score. With current settings you lose 5% of your score on every failure. So a drop from 1 drops by 0.05 and a drop from 90 drops by 0.045.
However, if I understand correctly, this sentence:
Implies that higher scores require fewer failed audits to get disqualified. But this isn’t the case as for any score x there is no higher score y that leads to x * 0.95 > y * 0.95 .
The formula as used now and also your version of it would simply converge around the actual data loss percentage. (ignoring other effects like temporary issues or the other issues @littleskunk outlined)
Did that here. It starts hopping around 66.66% as expected with that pattern. But I’m not sure what you intended to point out with this example.

That may be an option, but I think you need to start to be very careful about not giving a wrong incentive that it’s better to delete data if you’re not sure whether it’s corrupt or not. I tend to look to @littleskunk’s advise when it comes to chances for abuse and I think differentiation between those two scenarios might just open up a few.
From a customer perspective, there is no difference. Uplink and repair job will identify the corrupted pieces and use only the remaining healthy pieces for their operations.
For the audit job, it makes a difference. Wrong data can still pass an audit because we just take a small stripe out of the file and if that small part of the file is still correct the node would pass the audit even though the piece has been corrupted just in a different location. Does that matter? I would say no because in the first place it is very unlikly that the file gets audited. That means the consequences are the same as for a missing piece that is also unlikely to get audited. The repair job will automatically replace corrupted or missing pieces.
In this situation, I would argue that we only have to look at the biggest loophole that has the lowest chance to get you disqualified. That loophole might get abused. We can add as many smaller loopholes as we want. They will only get abused if they have an even lower chance to get disqualified. And that one loophole we have is so big and has such a low chance to get you disqualified that it will be almost impossible to beat that.
Sure if we think about closing all loopholes long term it would still be better to not add more and more loopholes. That only means more work to fix all of them later on. The point I am trying to make is that at some point the benefit you get from a loophole is too small to avoid disqualification. I would call it a small advantage but not a loophole anymore. The big question is where do we draw the line. I am unable to see that line because there is that giant loophole that forces me to orbit early on ![]()
Ominous ![]()
But if you are referring to what I think you are referring to, I think you could do a lot worse. That said, I take your point. That should be the first thing to be tackled for sure. I guess I was trying to lock the windows while leaving the door unlocked. ![]()
1 Like
I don’t have any data specific to SNOs, and disk hardware has advanced since I was involved closely with the hardware of massive storage operations, but I have been there, and I don’t recall file age being a particularly strong predictor of data damage. And if data loss is not strongly correlated with age, then repair traffic being correlated with age doesn’t have an effect on reputation.
But of course, I could easily be wrong about that supposition. Do we have any data indicating one way or the other?
Darn. I think I can do that when I have extra cycles. Could you @ me on the PR?
If the kernel froze, the node would appear to be offline (it wouldn’t be able to respond to any network traffic at all), so it should have been suspended, not disqualified, right? I must be missing something there.
That’s… a very good point. Ok.
If you want to fight that battle, you should really start by writing a paper like Dr. Ben’s justifying mathematically why your model is better.
Regarding wrong-data vs not-found data: I’m not sure it makes sense to penalize wrong-data more harshly than not-found data. We need data to be available, and we need node operators to be able to keep their data intact and online to a reasonable degree. Bitrot does happen, and with our file sizes we should expect it to affect file contents with a higher probability than directory contents. So if anything, we should treat not-found data more harshly than wrong-data. If there are any particular temporary situations you are worried about that would result in data not being found, let’s find a way to detect that and shut the node down until it can be fixed.
I’ll get back to you all when I have some hard numbers regarding acceptable percentage of data loss and how long we can allow bad nodes to remain online.
1 Like
In my situation, my storage node was still accepting incoming connections and even responding to them but anything that touches the hard drive will stall and never finish.
2 Likes