I see Unclean shutdown detected quite often after a regular shutdown of a node.
After restart it attempts to repair.
Docker command contains --stop-timeout 300 but still this is happening.
Are there other options?
I see Unclean shutdown detected quite often after a regular shutdown of a node.
After restart it attempts to repair.
Docker command contains --stop-timeout 300 but still this is happening.
Are there other options?
You may try to increase a timeout.
I don’t observe that on freebsd – just restarted every node just to test, and grepped a week worth of logs. But I use neither docker nor windows. I can imagine two things maybe happening:
I don’t think timeout matters.. All my nodes exit in under a second. 300 seconds is an eternity for the process to exit. There is simply nothing for it to do for five minutes.
As far as I remember, @jammerdan runs nodes on some SOC device with a small amount of RAM, so stopping nodes may be slower than on a powerful server.
Quite right. But not only on these.
What I have just observed is what @arrogantrabbit has written:
nodes exit in under a second. 300 seconds is an eternity for the process to exit. There is simply nothing for it to do for five minutes.
It is definitely not waiting 5 mins for the shutdown.
Could you please check the system journal for errors related to the disk?
Also how do you invoke this shutdown to get these errors?
I don’t see disk related errors.
docker stop and docker rm
I have just tried it again repeatedly without luck. It does not happen on every shutdown restart cycle but I have seen this several times now on different nodes.
It happened to me too, on Synology DS220+ with 18GB RAM, during hashstore migration. The system didn’t wait 300s and just killed the node, during a shutdown by UPS. 2 or 3 times. The other migrated node stopped nicely. Maybe it’s a Docker issue, not a storagenode issue.
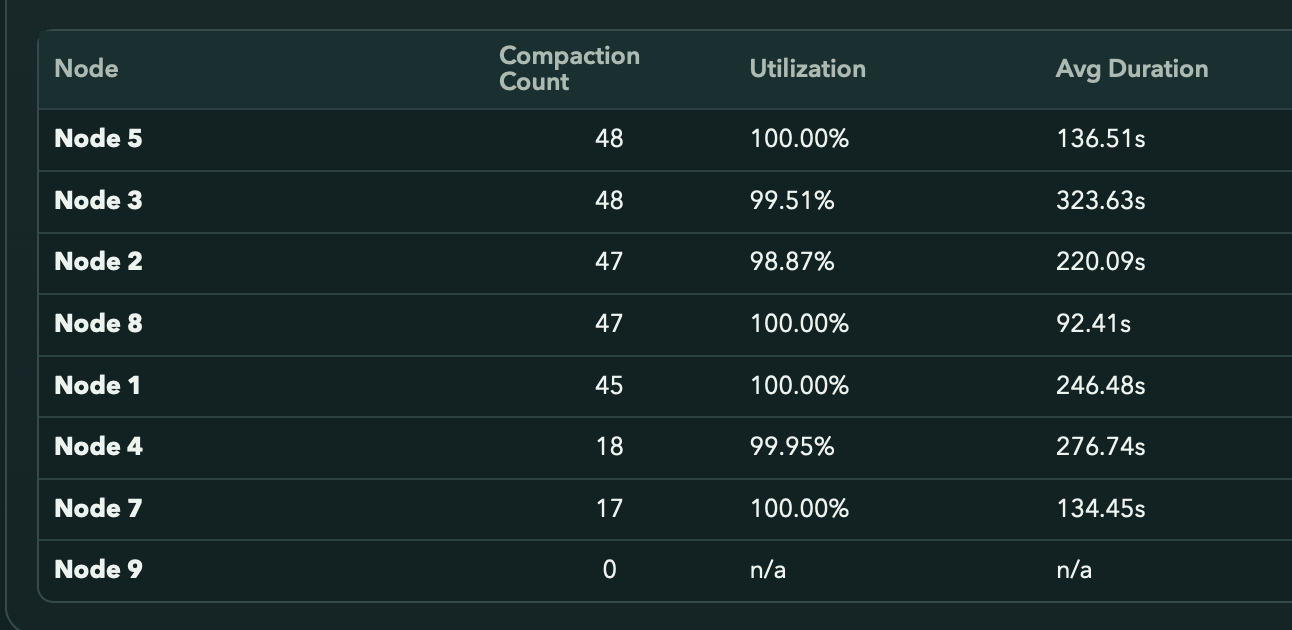
maybe hashstore related chores, like compaction process, is not cancellable gracefully? If, that could be a bug. Whoever has tokens left this week can ask codex to look at the source to check if that’s the case ![]()
Observed compaction average durations approach 300 seconds occasionally (from past week):
It just happened again on a different node for updating:
2026-04-24T08:06:54Z INFO hashstore unclean shutdown detected: reconciling logs {"process": "storagenode", "satellite": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "store": "s0"}
I am still seeing this error a lot. This can’t be correct in a way.
Occasionally I also see this output when I restart the node to change the config. I actually ran into it yesterday when the DDNS didn’t update and the node didn’t receive traffic for half an hour. The server has 32 GB of RAM. The disk is fine and the journal contain no errors.
Please submit a bug on our GitHub, I shared this issue with the team, but seems a filled bug will be better.