For some time now I have been having some problems with the stability of my nodes since they stop frequently.
At first I didn’t even look at the log but seeing that the situation keeps repeating itself over and over again I see that the pattern is repeating itself.
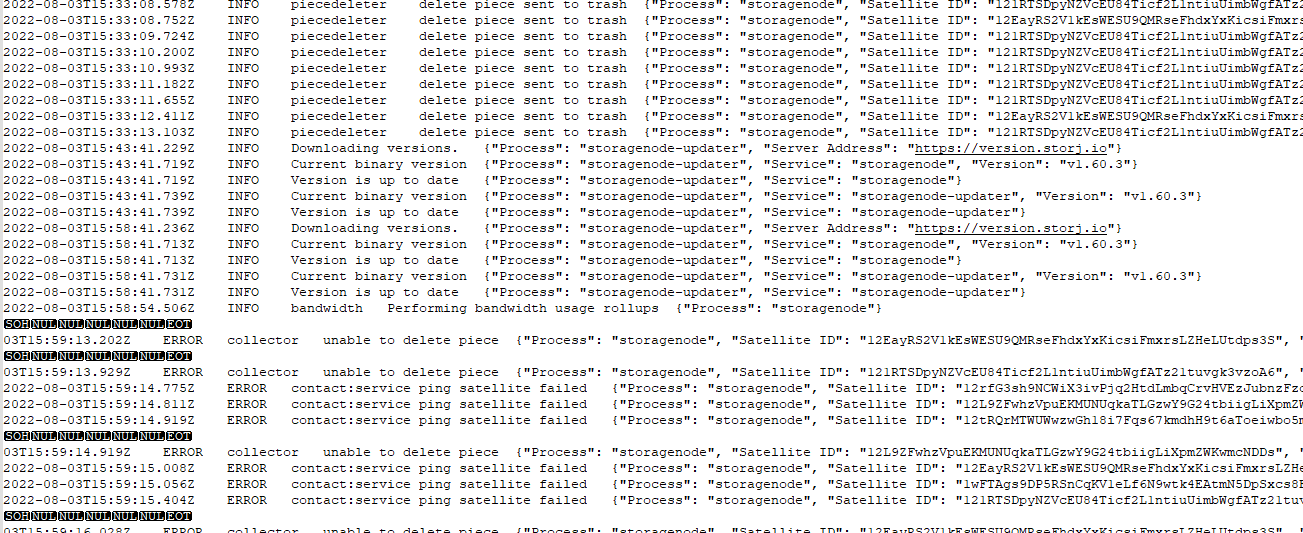
The log I get when the equipment stops responding is as follows
2022-08-02T08:33:39.211Z INFO Downloading versions. {"Process": "storagenode-updater", "Server Address": "https://version.storj.io"}
2022-08-02T08:33:39.677Z INFO Current binary version {"Process": "storagenode-updater", "Service": "storagenode", "Version": "v1.59.1"}
2022-08-02T08:33:39.677Z INFO New version is being rolled out but hasn't made it to this node yet {"Process": "storagenode-updater", "Service": "storagenode"}
2022-08-02T08:33:39.694Z INFO Current binary version {"Process": "storagenode-updater", "Service": "storagenode-updater", "Version": "v1.59.1"}
2022-08-02T08:33:39.694Z INFO New version is being rolled out but hasn't made it to this node yet {"Process": "storagenode-updater", "Service": "storagenode-updater"}
2022-08-02T08:44:32.516Z ERROR contact:service ping satellite failed {"Process": "storagenode", "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "attempts": 12, "error": "ping satellite: failed to dial storage node (ID: 12EAz4dcw7BJPmEWMvDA5gTEbSJFUu55MAbpTkrEkN5kmxH6TNP) at address my.ip:28967: rpc: tcp connector failed: rpc: dial tcp 144.24.192.165:29045: i/o timeout", "errorVerbose": "ping satellite: failed to dial storage node (ID: 12EAz4dcw7BJPmEWMvDA5gTEbSJFUu55MAbpTkrEkN5kmxH6TNP) at address my.ip:28967: rpc: tcp connector failed: rpc: dial tcp 144.24.192.165:29045: i/o timeout\n\tstorj.io/storj/storagenode/contact.(*Service).pingSatelliteOnce:139\n\tstorj.io/storj/storagenode/contact.(*Service).pingSatellite:98\n\tstorj.io/storj/storagenode/contact.(*Chore).updateCycles.func1:87\n\tstorj.io/common/sync2.(*Cycle).Run:160\n\tstorj.io/common/sync2.(*Cycle).Start.func1:77\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:57"}
2022-08-02T08:44:42.477Z ERROR contact:service ping satellite failed {"Process": "storagenode", "Satellite ID": "12tRQrMTWUWwzwGh18i7Fqs67kmdhH9t6aToeiwbo5mfS2rUmo", "attempts": 12, "error": "ping satellite: failed to dial storage node (ID: 12EAz4dcw7BJPmEWMvDA5gTEbSJFUu55MAbpTkrEkN5kmxH6TNP) at address my.ip:28967: rpc: tcp connector failed: rpc: dial tcp 144.24.192.165:29045: i/o timeout", "errorVerbose": "ping satellite: failed to dial storage node (ID: 12EAz4dcw7BJPmEWMvDA5gTEbSJFUu55MAbpTkrEkN5kmxH6TNP) at address my.ip:28967: rpc: tcp connector failed: rpc: dial tcp 144.24.192.165:29045: i/o timeout\n\tstorj.io/storj/storagenode/contact.(*Service).pingSatelliteOnce:139\n\tstorj.io/storj/storagenode/contact.(*Service).pingSatellite:98\n\tstorj.io/storj/storagenode/contact.(*Chore).updateCycles.func1:87\n\tstorj.io/common/sync2.(*Cycle).Run:160\n\tstorj.io/common/sync2.(*Cycle).Start.func1:77\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:57"}
2022-08-02T08:45:55.509Z ERROR contact:service ping satellite failed {"Process": "storagenode", "Satellite ID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE", "attempts": 12, "error": "ping satellite: failed to dial storage node (ID: 12EAz4dcw7BJPmEWMvDA5gTEbSJFUu55MAbpTkrEkN5kmxH6TNP) at address my.ip:28967: rpc: tcp connector failed: rpc: dial tcp 144.24.192.165:29045: i/o timeout", "errorVerbose": "ping satellite: failed to dial storage node (ID: 12EAz4dcw7BJPmEWMvDA5gTEbSJFUu55MAbpTkrEkN5kmxH6TNP) at address my.ip:28967: rpc: tcp connector failed: rpc: dial tcp 144.24.192.165:29045: i/o timeout\n\tstorj.io/storj/storagenode/contact.(*Service).pingSatelliteOnce:139\n\tstorj.io/storj/storagenode/contact.(*Service).pingSatellite:98\n\tstorj.io/storj/storagenode/contact.(*Chore).updateCycles.func1:87\n\tstorj.io/common/sync2.(*Cycle).Run:160\n\tstorj.io/common/sync2.(*Cycle).Start.func1:77\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:57"}
I see that right now is deploying the v1.60.3 version and it seems that the docker is not applying it correctly and stays in that state forever.
This is my docker configuration
docker run -d --restart unless-stopped --stop-timeout 300 \
-p 28967:28967/tcp \
-p 28967:28967/udp \
-p 14002:14002 \
-e WALLET="0x000000" \
-e EMAIL="my@email.com" \
-e ADDRESS="my.ip:28967" \
-e STORAGE="4TB" \
--mount type=bind,source="/mnt/disk1/storj/identity",destination=/app/ident> \
--mount type=bind,source="/mnt/disk1/storj/config",destination=/app/config> \
--name storagenode storjlabs/storagenode:latest