What does Storj do to increase revenue for higher yields? (Proposals are price increase and extra charges for gateway usage)
What does Storj do to boost customers usage of native integration vs. use of costly gateway?
What extra use cases is Storj currently developing that could justify higher prices see pricing for Wasabis “Surveillance Cloud” ?
Where are we regarding compliance and technical certification ( ISO, DIN, TÜV, GDPR, HIPAA, CJIS, FERPA, MPA etc.)?
Additional topics:
The multinode dashboard is terribly broken (Here and here), yet I cannot see much if any effort put into fixing or even adding features. So I take this chance to bring my dissatisfaction with it to the upper management hoping that this app gets some more attention. Because the idea of the app is great but lacking so much in its current state.
Please hint more customer prospects or name actual customer besides what we already know. We always hear this might be confidential, but it is hard to buy when we look at what Amazon publishes about their customers. So please ask more customer and potential customers for permission if required and show more on what Storj business development is working on resp. has achieved. It might help to rebuild trust.
I think it would be interesting to have occasionally additional Storj members as participants in the Twitter Spaces. I name Rosie Pongracz as one example. I am pretty sure it would be interesting to learn more on what other members of the Storj team are working on.
I also won’t be attending both because I also don’t have a twitter account but the timezone just doesn’t work for me.
I have the following questions:
Since the proposed changes have huge economic impact on SNO’s will Storj also review or remove the /24 rule currently in place to allow SNO’s to scale where the economics make sense.
With the proposed changes plus the current withheld system Nodes will not only not make a profit in the first year - they will be significantly in the hole. Will this also be revisited at the same time?
Have any changes to vetting been implemented yet? This was mooted by Storj previously but nothing was announced.
Since places with high electricity costs are likely to see the greatest node loss what modelling has done on how this might impact your geo-location agreements with clients?
Storj likes to use vague wording - and often says they hope being a Node Operator is a “rewarding” experience. What do you actually mean by this? Please explain in some substantive detail?
What is average node life now. Previously it was 10 months but it should be higher than this now.
Given the economic changes - do you think it fair for SNO’s to run test nodes for the company benefit FOR FREE? Why is this still reasonable?
I’ll add any others I can think of if time permits.
Did you have plans to eventually have semi-/pro Node Operators who would run a couple 50+ TB nodes each? If not, do you have such now?
If you plan to have them, how do you want to execute it?
If you totally don’t plan it, how do you see a “regular Joe” running a <4 TB node that’s profitable while maintaining high accessibility and overall good health? How do you plan to achieve Exabyte with such approach?
Support response with numbers and charts, so we know plans and expectations with least amount of blanks and guesswork.
Yeah here’s one.
Has Storj been or expect to be in any way impacted by the ongoing collapse of the banking system? Is anything being done to plan for such an occurance? Does Storj have multiple avenues to convert tokens to cash in order to pay the bills if their exchanges and/or banks are effected? And if so, does Storj have enough cash reserves and/or lines of credit spread out among multiple banking institutions in case any of them become inaccessable for any period of time if not permenantly?
Storj has access to 100% of our deposits. Like other companies, we are further diversifying our deposit accounts at different banks, and we are well positioned to operate without any disruption to employees, customers, vendors, storage node operators, or community members.
I don’t see questions about the proposal and I understand that is still under discusion and nothing is set, but for this tweeter space and next ones, here are some:
What is the time frame for implementing the payout reduction?
What gradual implementation means exactly?
Will the payouts be reduced little by little each month? Or there will be like 2 or 3 reductions etc?
If the network looses to many nodes by these cuts, will the payouts be increased in the future to stop the loss?
Are there any plans to increase the prices for customers?
Are there secret payout negociations with the biggest SNOs, the so-called “whales”, to keep them onboard, no matter what others will do, because they have proffesional setups and big percentage of the storage space available?
Provide an update on native integration backup applications (windows, macos, linux, docker (technically linux), etc)? I suspect that a large number of S3 connections are due to backup use cases and the ability of existing backup applications to connect to S3.
Not just repair costs. This could lower the expansion factor and create significant savings on storage costs.
Based on public stats about 42% of available capacity is used by customer data and usage is growing exponentially. This doesn’t really sound like massive oversupply to me. Have you considered what happens when space runs out or too many nodes leave?
With a recent bump in ingress, we’re seeing some nodes having trouble keeping up with traffic again. This was also shown during load testing in early 2020. Have you considered the impact on performance for these nodes when supply is reduced and traffic is concentrated on fewer nodes?
How much time is reserved for this twitter space? Given the amount of questions, more time may be required than normal to respond to all of it.
Yeah, at the end, to be honest, We need You more to listen to us in full now. Than, to listen to you guys talk. Make a promise publicly, You will read all the answers under “Update Proposal for Storage Node Operators” in Announcements. Thank You, that’s all from me.
Hi,
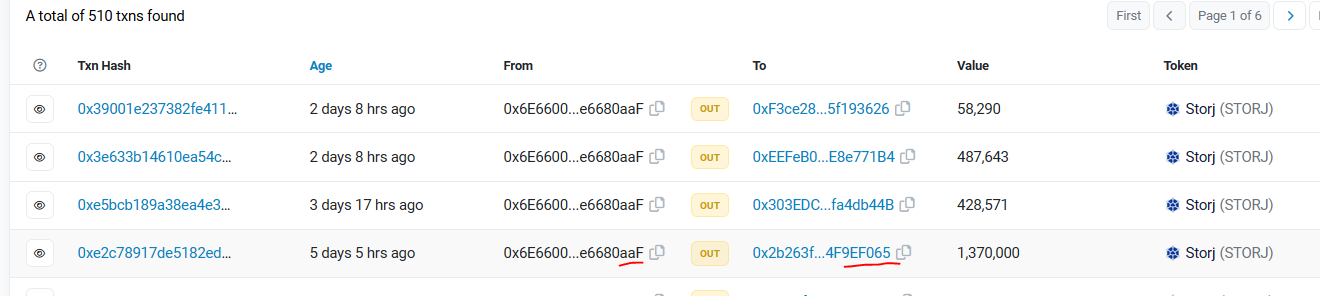
i would love to know why 20M STORJ tokens sent from Storj MultiSig 1 ended in Binance in the last 2 months. Are they sold directly to obtain liquidity?
We’ll start 30 minutes early to accommodate more questions. Unfortunately, editing a twitter space start time cancels any reminders previously set, so to avoid doing that, I’m letting you all know it is starting early here.
Keep in mind it is recorded and you don’t need a twitter account to listen
Results of experiment: Seems it only persists the reminder when it’s the original time. I thought it reminded me for the one that was rescheduled, but I can no longer find any proof that’s the case. So I’ll keep the original time and I confirmed it notifies when the twitter space starts early.
Edit ran another experiment: It notifies regardless of rescheduling and it persists the notification for the one that starts around the time of the twitter space, so I’ve updated the twitter space time to reflect that.
Why do you DQ a node at 96% failed audit, instead of ring fencing it to block all inbound traffic, while allowing the repair workers to harvest any good data on the nodes to see if it can be recovered. To be clear, I’m not talking about having the node scanned by the Audit worker. Just given the costs you are incurring, evicting these nodes when they “might” have good data, and then making a loss on the repair has never been sustainable due to the current mechanism on the held amount.
Why do you not follow best practice on the Github when it comes to keeping the release version tag, aligned with the code running on production ? The last few months, there have been multiple occasions when pre-release tagged builds on Github, have been the current version on production, with the release tag being 3 versions behind
What do the customers think ? is there any appetite for a more dynamic payment structure for the service (aka nodes), based on quality and service offered instead of the current one size fits all approach ? I think this information will really help the SNO payment discussion.
Are you able to elaborate on the contingency measures already put in place by Storj to cover the exodus of nodes following the new price announcement - have additional nodes been spun up in hosting provider datacentres to cover this already ?
This one’s pretty easy. A repair worker needs a whole stripe (i.e. 29 good pieces) to repair data. It doesn’t matter whether it is taken from healthy or failing nodes. Now, if you assumed it is possible to just take piece from the failing node and move it without changing to another, it’s not possible either—you can’t trust that the piece is actually correct without downloading at least 28 other pieces. I had exactly this case when my node started failing audits because of a RAM error, my pieces were being sent corrupted.