A bit of context first:
started the node in april. Running fine with unfortunately not that much ingress (~20Mb/s), and very low cpu load (~0.02)
Then the testdata came, BW went to 150-170Mb/s, cpu load barely moved up a little to 0.06-0.08.
During the following 6 days, about 10TB ingress. Great, although I wondered why it did not go above 160Mb as clearly my system could take it.
Then BW went back down to about 40Mb/s, and I see disk IO is about 9MB/s. So really nothing special or big.
However, now the storagenode process is eating up all CPU time, overall pegged at 1-1.2, the system is even a bit sluggish. htop shows the WCPU at about 600-1200% for the “storagenode run” process. In comparison, the “storagenode used-space-filewalker” is using up ~60% WCPU
So I really wonder what has suddenly changed, why is storagenode using so much cpu now ? is anyone seeing this too ?
almost all my nodes are ok, just 1 does 100% CPU right now. From yesterday i guess.
but its win 10, it can be F’d up instance, it has periodical problems always with CPU and storagenode, might be just some Windows Defender whimsy because storagenode.exe different behavior, which is tottaly possible, the storj’s tests are ongoing, and windows is a brat, who may do problem with its Antimalware BS even if You disable everything.
Retain is the process that checks existing pieces against a bloom filter and moves them to trash in case of mismatch. It should start to run when your node receives a bloom filter.
ok is that another process ? ( I mean not storagenode. I guess it runs internally )
currently I only have three running:
storagenode run
storagenode used-space-filewalker
storagenode gc-filewalker
update : storagenode main process (run) dropped CPU back down to a comfortable 16% WCPU and overall cpu load is 0.1 again…
very strange long cpu spike.
Meanwhile I did not notice anything special. Well for the last day or so I see more “Error piecestore upload failed, broken pipe” which to me looks like the satellite just closed the connection (i.e. I lost the race). not surprising given the high cpu load and general sluggisnesh.
and now it goes up again. weird. would think load would be more or less dependent on network traffic and/or disk io. There it just sucks cpu and barely moves data around. sounds fishy. may have to profile it and see.
Not the satellite, the client. The customers’ data is never going through the satellite.
I cannot confirm any relations between a high CPU usage and storagenode run process so far, but perhaps it’s related to a high IO Wait when it accepts data? Or do you see the real load, not IO wait?
during those times the used incoming bandwidth goes way low (makes sense, the cpu is so loaded I start getting lots of logs about failing to upload or failing to download pieces)
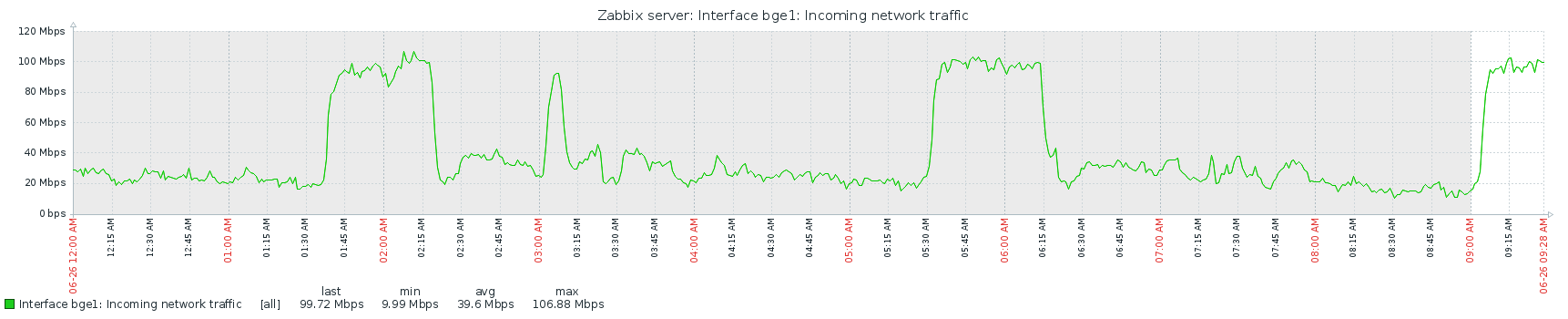
This is bandwidth exclusively going in/out of storagenode, my server has four ethernet interfaces and I bind the storj jail exclusively to one of them, and I disabled routing between interfaces, so there is no extraneous traffic.
I did not see this pattern at all during the data tests last week, it was just humming at very low CPU and 150Mb/s ingress. There is something wacky going on. Do we know if storagenode does some periodical task that takes huge cpu time ?
I do not believe the diskIO reported by htop here. This machine can do hundreds of MB/s and not break a sweat, sitting around almost idle. Also the stats reported by zfs differ a lot. And as soon as storagenode decides to not use up all cpu, network traffic and diskIO go up