I see high loads every time I restart my nodes, because I don’t use lazy file walker. As such, a full search of the node will be done upon reboot, thus giving large IOPS
I wonder if it’s something benign like, now that the badger cache is available, the startup operations are much faster and then require database updates to be much faster…
I’m not saying it’s an issue or unintended, but - on 3 of 8 nodes on this particular machine, the pieces_expire database is 10-15GB and for the remaining it’s much smaller. Those are the only large files from the nodes on the SSD, so I suspect the traffic is aimed at those files.
The files:
-rw-r--r-- 1 root root 12G Aug 21 18:01 sn251/piece_expiration.db
-rw-r--r-- 1 root root 2.0G Aug 21 17:44 sn252/piece_expiration.db
-rw-r--r-- 1 root root 2.4G Aug 21 17:56 sn253/piece_expiration.db
-rw-r--r-- 1 root root 2.4G Aug 21 17:24 sn254/piece_expiration.db
-rw-r--r-- 1 root root 13G Aug 21 17:47 sn255/piece_expiration.db
-rw-r--r-- 1 root root 12G Aug 21 18:09 sn256/piece_expiration.db
-rw-r--r-- 1 root root 2.3G Aug 21 18:14 sn257/piece_expiration.db
-rw-r--r-- 1 root root 2.5G Aug 21 18:07 sn258/piece_expiration.db
I’m sure the pieces_expire databases are this large from previous issues / slowness on the nodes / cancelled or nor complete uploads etc.
So my expectation is that the database is “as expected” though it probably has a lot of obsolete entries.
For reference - I have checked consistency and vacuumed them - all is good.
These are faily old nodes - 2-3 years, so many things could have happened to these databases in the past.
What i am concluding is:
Since v 1.110 - the load on these expire databases has been very high - i’m sure the nodes are actually doing “something” - I just do not know what it is doing or for how long it’s going to do it.
I guess it’s running through all the expire entries in the DB’s and trying to delete files, but it’s a VERY long list of files that probably already has been deleted by other functions.
In addition - this behaviour is different from previous versions (as the size of these DBs has been this large for several month).
I am wondering if it would make sense to delete these pieces_expire databases from the 3 nodes and let the GC / BF perform the cleanup instead.
Anything else I should be aware of, if I decide to go down this road?
If I decide to delete the piece_expiration DB from these nodes, it will be recreated on start and only impact is that GC / BF will have to clean pieces up that was previously in the DB?
Update on this issue.
Load has been continuing since my first post, and now I had a few hours to dig deeper into the cause of the issue.
Hardware
Intel CPU / 32GB RAM
Seagate X16 / X18 disks (1 disk = 1 node)
Samsung PM893 2TB SSD (shared for logs, DBs and other non-StorJ related workload)
LSI Megaraid controller (IT-mode)
Ubuntu 22LTS
Docker nodes
Findings
HUGE backlog on expired pieces in piece_expirations.db, example:
sqlite> SELECT DATE(piece_expiration) AS expiration_date,COUNT(*) AS piece_count FROM piece_expirations GROUP BY DATE(piece_expiration)
2024-07-19|6034937
2024-07-20|6651785
2024-07-21|5668095
2024-07-22|7423387
... and so on ...
Total entries for this node:
sqlite> SELECT count(*) FROM piece_expirations;
70610388
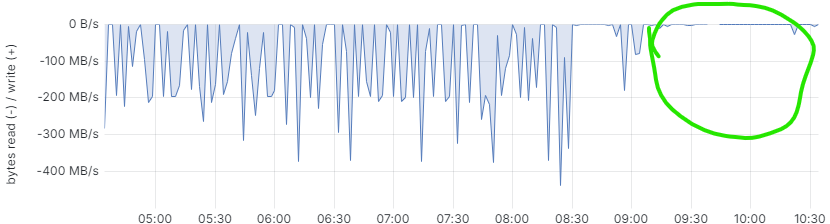
Whenever the node selects the next batch of 1000 pieces to delete, it causes SSD with DB file to read excessive amounts of data (avg 2-400MB/s for 20-30 seconds - typically most of the database dataset of 10-15GB)
Tons of “file does not exist” WARN log messages 2024-09-13T22:17:28Z WARN collector unable to delete piece {"Process": "storagenode", "Satellite ID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE", "Piece ID": "2KDVVEO7TLJDBL2UB3X7736HIITPVZ56KAVWUYCCVALTBHWW5T3Q", "error": "pieces error: filestore error: file does not exist", "errorVerbose": ...
My Thesis
During the test data “explosion”, amount of piece to expire grew too much for my nodes IOPS to keep up
When the garbage bug was fixed with release v1.110 / Bloom filters to exclude expired pieces - BF’s removed this data
Race condition between piece_expirations and BF overloading disks IOPS capacity
Quick calulation indicates 5-6 months of 100% IOPS time to complete backlog (expected 150-200 IOPS on a Seagate X16)
My Fix
Delete obsolete expired pieces from database, as it would take months and months to process backlog. And the wast majority of this data was already deleted by the BF change to explude expired pieces.
How
Delete expected obsolete pieces from expire table:
sqlite> DELETE FROM piece_expirations WHERE piece_expiration LIKE '2024-07%';
sqlite> DELETE FROM piece_expirations WHERE piece_expiration LIKE '2024-08%';
sqlite> DELETE FROM piece_expirations WHERE piece_expiration LIKE '2024-09-0%';
… and let the node process through the remaining days from 2024-09-10 to current date (as anything before that should have been already handled by BF / GC)
DISCLAIMER: This is NOT a complete guide, just my findings and how I resolved the load issues on these nodes. Please do not blindly perform anything from this post, if you do not know the implications, ie. when to stop the nodes for various tasks etc!
Just my 2 cents, in case someone else can benefit from it
Kind of expected. Everyone node has experienced this.
Since we have implemented a workaround for the expired pieces not deleted in time, we would hope that these mass deletions would not happen in the future and would be handled better.
Not necessarily, but depends on an underlying disk subsystem of course.
My nodes handled that (with enabling a badger cache for the biggest one) pretty good. After a month all nodes reported a correct used space, the correct used space in the trash and everything looks good. The total amount of 9.28TB.
They are on Windows, so NTFS. Two nodes in the Docker Desktop and one under a Windows Service.
So, the worst scenario.
I didn’t do anything manually, they handled themselves.
And also I didn’t watch them every second. Maybe it’s an Important part.
I did some maintenance, when I received a message, that my nodes goes to offline (WSL2 is not so robust, as I would expect), however, the restart of the needed services is helped.
True - it will vary, and I agree that my nodes are not anywhere near worst case hardware for this kind of setup:
Single disk per node (dedicated)
Dedicated LSI 2008 SATA controller
SSD for log + DB offloading
Badger enabled
Plenty of free CPU time
Which is probably why I’ve won many races, and maybe seen a higher intake than other low performance nodes.
Each of these had 50-70 mill pieces, and I guess that would contribute negative to the escalated impact on the race condition between BF/GC vs expire deletions.
Sure thing, overanalyzing metrics related to this kind of workload can have negative consequences However, in this case I left it for a few weeks and went back to the issue.
Anyway - it’s resolved for me, and the nodes and I are happy.
Again - I just shared this info to aid someone else that could be in the same boat