Thanks for that info @Alexey.
Today I got 7 audits on one satellite, so I guess things are picking up. I forget, do nodes need:
- 100 audits per satellite to be vetted on that one satellite, or
- 100 audits on any satellite to be vetted on all satellites, or
- a total of 100 audits across all satellites to be vetted on all satellites?
I think this information would be sufficient to consider my question answered.
You need 100 on each satellite to be considered vetted on that satellite. They work independently from each other.
My node has been running for 10 more days since my last update and holding 10G on a disk now. I got 3 more audits from 118UWp and that’s a total of 4 in 20 days while 118UWp issuing wast majority of traffic. Meanwhile, I got vettet on 12EayR with 193 audits:
# api() { curl -s 127.0.0.1:14002/api/$1; }; for sat in `api "dashboard" | jq -r '.data.satellites[]'`; do printf '%-8s %-5s %-5s %-20s %-5s %-5s\n' `echo $sat | cut -c1-6 ; api "satellite/$sat"| jq -r '.data.audit[] ' | xargs -L5 ` ; done
12EayR 193 193 19.99904630518452 0 1
118UWp 4 4 4.524381249999999 0 1
121RTS 0 0 1 0 1
12L9ZF 6 6 6.033254078124999 0 1
I’ll drop another update here in 10 days.
It should take at least a month to get node vetted on one satellite
I should note that there was also a pretty big uptick in ingress traffic. My node that was sitting around 1-2GB of used storage for a week is suddenly also holding 10+GB after the two days that this traffic pattern started. I’m seeing about 4.5GB added per day.
Graph timezone is EDT (UTC-4).

Note that I operate two nodes (at different facilities), and the other was launched less than a week ago. I have this same monitoring on both of them and they both show exactly the same trend. It therefore seems that this increase in ingress traffic is not related in any way to the status or condition of my nodes but is simply an increase in internal testing and/or customer activity on the network.
@greener It would make sense that your node is seeing this increase as well, and that would explain the increase in your used storage as well.
So it seems everything is fine, we just need to wait for more audits.
Do you mean ‘online’ as in ‘reachable for uptime audits’, or ‘have a high uptime counter’ ?
If I am reachable for 100% of uptime audits, will it matter if my node-uptime isn’t high? Or, will I be penalized for only having say, 2days uptime on the node?
I can restart my SNO in 3.5secs when I tweak parameters, but I’d like to know if I should stop doing that. I haven’t had a failed uptime audit on the node, according to the satellites.
The uptime checks are what matters. Not the number shown on the dashboard.
A single failed uptime check will not have much effect on your uptime score, anyway. I’ve had a few here and there (kernel upgrades, hardware maintenance, Internet outages) and my uptime score on all satellites is at or above 0.99 (1 is perfect). IIRC the network only takes action when this falls below 0.6, and I recall hearing that this process is currently suspended.
How can be vetting on different sattelites very different.
Some are almoste done, other even not started.
{
“totalCount”: 0,
“successCount”: 0,
“alpha”: 1,
“beta”: 0,
“score”: 1
}
{
“totalCount”: 68,
“successCount”: 68,
“alpha”: 19.419290727646825,
“beta”: 0,
“score”: 1
}
{
“totalCount”: 0,
“successCount”: 0,
“alpha”: 1,
“beta”: 0,
“score”: 1
}
{
“totalCount”: 80,
“successCount”: 80,
“alpha”: 19.686207886684723,
“beta”: 0,
“score”: 1
}
Easily. They are independent of each other. They have an own customers, which are actually uploads and downloads their data. The satellite just an accounting and helping system, it is made for customers to do not bother them with all technical details such as node selection, payouts, audits and repairs. So each satellite auditing your system for its customers and their data.
If you don’t have a data from the customers of that exact satellite, there is nothing to audit
I am getting audits from all other 3, but not this one
“id”:“121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6”,“url”:“asia-east-1.tardigrade.io:7777”
@champmine18 You probably dont have any files from that sattelite yet hence no audits.
@John.A thank you, I understand that, but I am running several nodes and all of them do not get traffic with the asia satellite. I just wanted to point this out. It will be extremely difficult if not impossible to get 100 audits on the asia satellite for vetting the node.
If I am interested in running a satellite will there be a tutorial in due time?
The Asia satellite is the least used one atm. So you may not be getting vetted, but that also means you’re not missing out on much. I’m sure this will change when more Asia area customers are on boarded.
if not vetted on asia, will the node be vetted by other satellites to be able to receive full traffic?
Each satelite work independently of each other, if you veeted on satelite, then this satelit will give you all data 100%
@Vadim, great, thanks for the clarification, that was not clear from the earlier discussion in this thread, but now it is
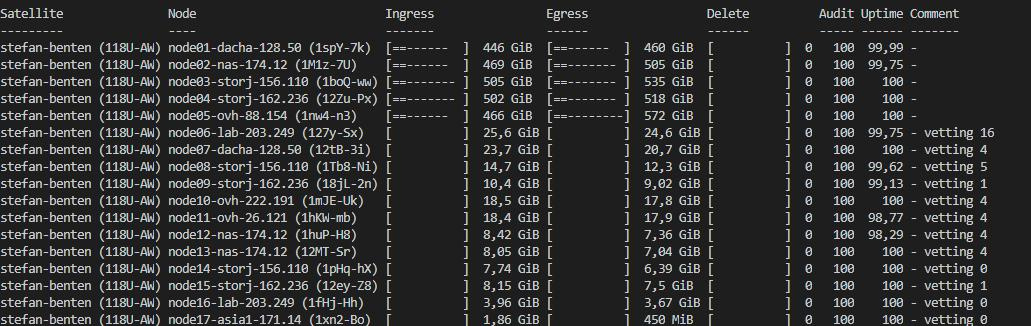
I am somewhat confused by some of the comments, for a node to be considered “vetted”, does it need 100 audits on one satellite for that satellite to be vetted, or does it need 100 audits on all satellites? The latter seems unrealistic when the networks has an increased number of satellites
Operating one node that has >100 audits on one satellite but not the other 3…
please clarify!