I think @madbitz meant to make a data backup to split the array.
Looks like it’s tricky with storage spaces as it doesn’t allow you to remove a drive from a mirrored array if you only have 2. I found someone suggesting you could attach on of the HDD’s to another windows system, remove the array that will show up on that system and then add the drive back into the old system and initialize it as a separate drive. Copy the data over from the now degraded array and then remove the original pool and setup a second node on that first HDD.
Unfortunately not the cleanest process and it would require access to a different system where you can remove the HDD from the pool. Can’t think of anything better if you want to avoid buying another HDD though. Though, with time I do think you’ll be able to fill that 15TB. And with 3 nodes you have even more spreading of load going on. It’s up to you I guess.
Doesn’t mirror mean they share 1:1 so they should have the same files. So it should be simple to just remove the mirror right, or is it cause windows don’t allow it…
As I mentioned I’m not that familiar with storage spaces. But from my basic googling it looks like windows stores some metadata on those HDD’s to show they are part of a storage pool. It won’t allow you to do anything with the individual disk if it is. Perhaps you can try removing partitions in disk management and force breaking it. But it wouldn’t surprise me if windows blocks you from doing that.
Within storage spaces itself you can only remove mirrors if you have more than 2 HDD’s in the array.
Hmm makes me curious I might have to test that on my vm to see what happens if you just remove it, if possible. I also have never used this before…
EDIT: ok So I ran a test I created a pool

I then proceeded to just remove the drive from the system.
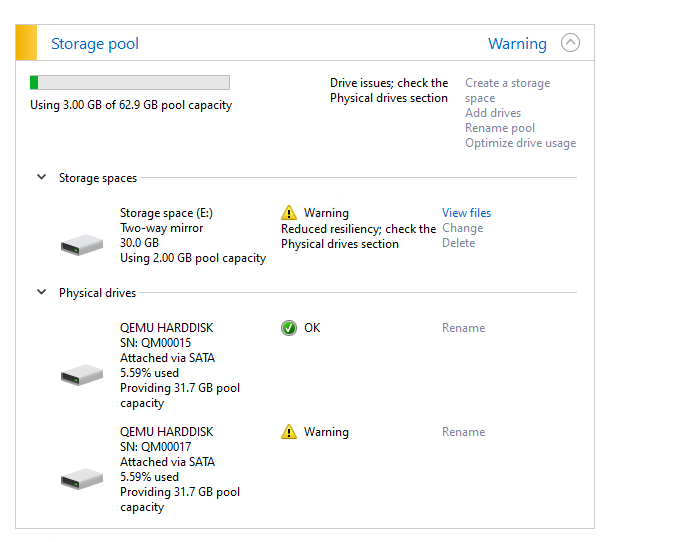
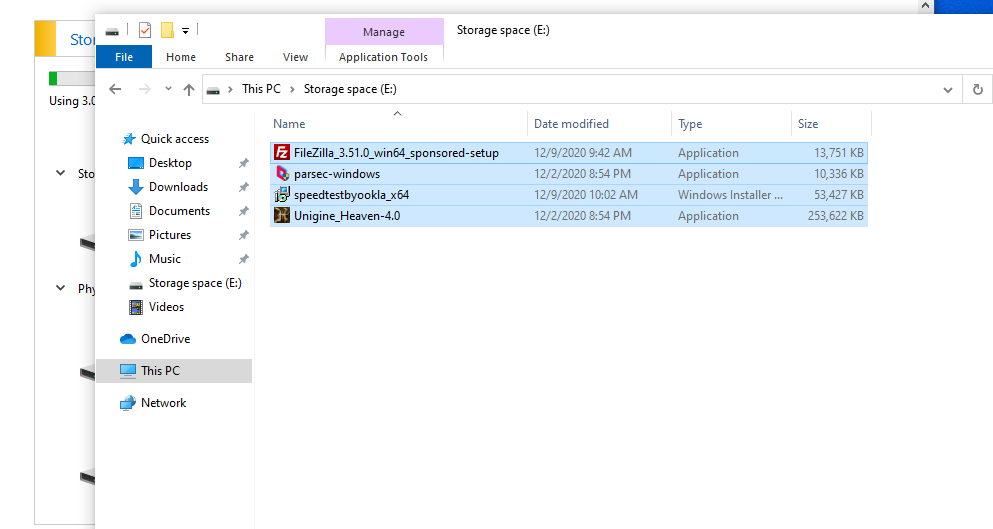
You still have access to the files even with the other hard drive not connected.
But if you delete the pool it deletes everything, so guess if you were to format the other drive on another system you could infact keep going on with using the pool as is, With the second drive hosting another node.
Other option is buy another hard drive, copy all the files to new hard drive. Delete pool then proceed in creating 3 nodes. No mirror no backups.
I’m guessing windows will keep nagging you about a degraded pool though. Doesn’t really feel right to keep using it in that state. But you could copy the data over to the now formatted drive. Still requires a different system to do the format though.
Yeah for sure not a good place to be in…I think I would just buy an extra hard drive copy files and delete the pool I will never use windows software to handle my drives…
How many time have your node?
It feels almost impossible to keep it above 95%, given:
- Standard downtime that many homes have with internet (routers restarting, power outages, internet resetting, competing devices, so much more)
- The fact that the system requires maintenance
- Zero notifications provided about downtime, so unless you happen to have time to check it regularly, that 95% is out the window.
IMHO, the downtime allowance should never be higher than a 90% requirement, otherwise, you’re just being unreasonable/unfair to many nodes who are actually working hard to keep their online % high. 90% should be allotted from a technical perspective too, so that files can be available for end-users 100% of the time regardless of the node availability.
I’m no expert in file management, but I can share my experience hosting a node - NOT easy to keep above 95%, and I will probably remove my 13TB from the network eventually if the requirement becomes too high, which would be unfortunate.
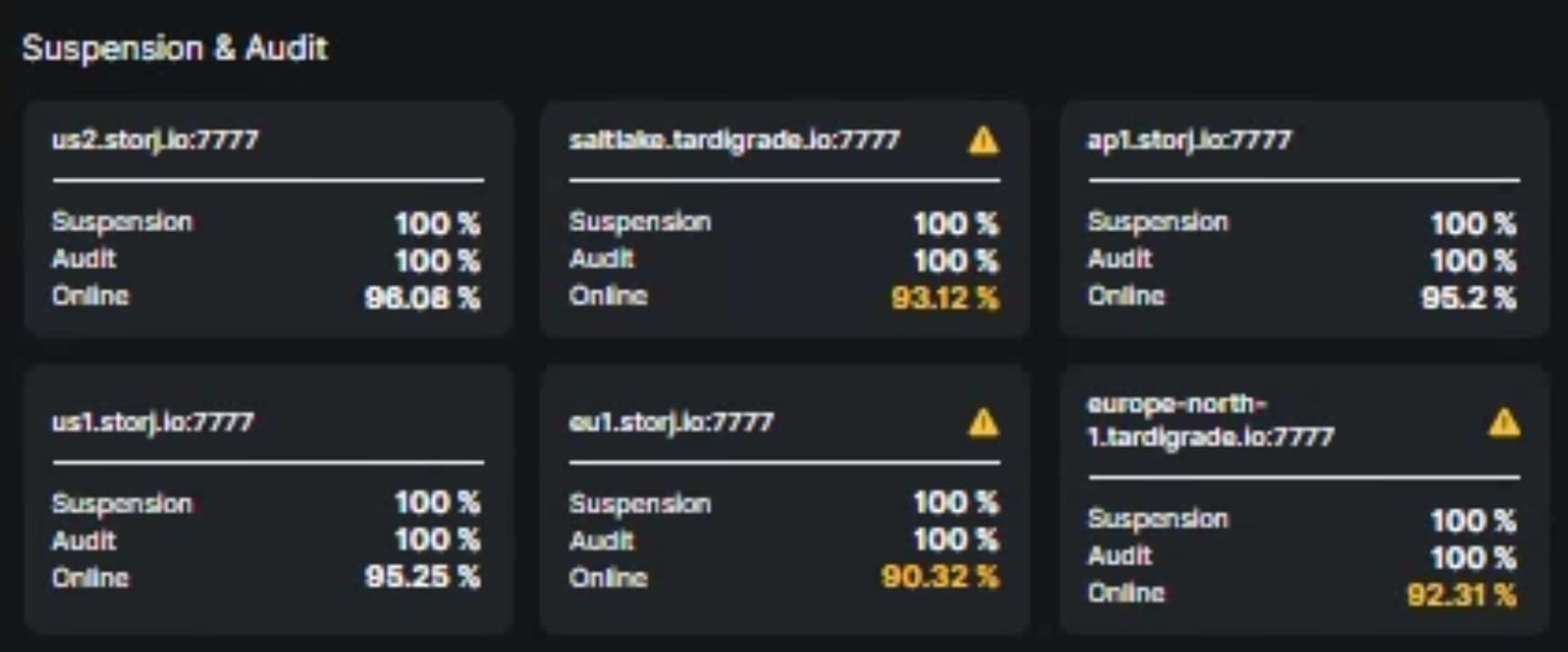
You’ve revived a really old topic and responded to an outdated comment. The suspension system is now live, but it’s set at 60%. That said, the only reason that’s possible is because most nodes actually keep their uptime well above the warning threshold of 95%. Which I will maintain is the right level to start warning people at. I’ve also been running my node at home for more than 2.5 years now and I’ve never dropped below 99% uptime. 95% allows for 36 hours per month. No amount of router resets is going to get you anywhere close to that. Nobody is saying your node should be disqualified or even suspended when it drops below 95% for a short time. But a node that is consistently below it is mismanaged in some way and it is definitely reasonable to warn the operator about that.
You don’t have to worry about data availability on the network as a result from this. And the reason for that is again that most nodes easily stay above the 95% warning threshold. But that warning sets an expectation. If Storj was more lax about that and allowed more down time they would have to eventually increase redundancy and inevitably lower payout to compensate, which really wouldn’t be fair to the more reliable node operators. Who at the moment, you have to thank for the uptime suspension not being a lot more strict.