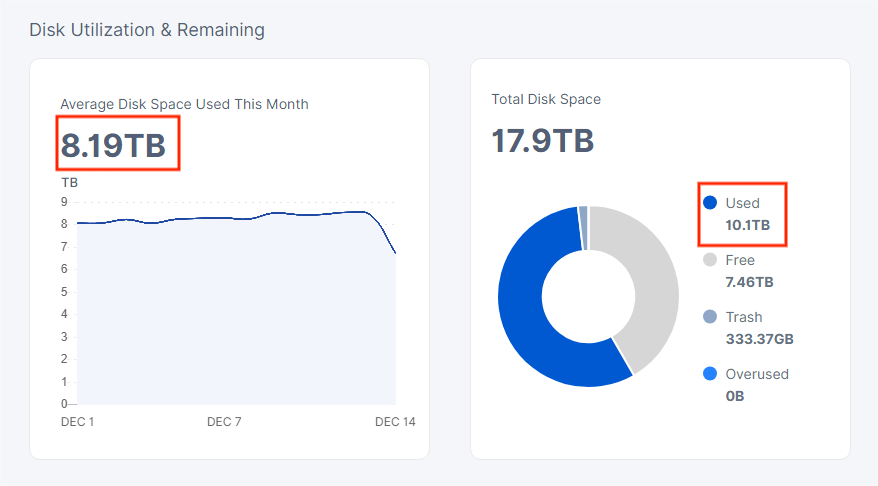
Please check the image below and help me understand when the average will be the same as the used space. This node has been full for 10 days, but I haven’t noticed any increase in the average in current month.
Will the average be the same as the used space on January 1, 2024, or am I missing some details?
Wich filesystem and clustersize are on the drive?
How big and what type number?
in the blobs folder, are there 4 or 6 folders?
Fatal errors in the log?
Log to big to open?
defragmentation ?
Temp folder not empty when node stopped?
in gerneral provide hardware, internet and software info.
yes. You need to enable it, since your accounted disk usage is differ from the actual disk usage.
Please also search for errors, related to gc-filewalker, lazyfilewalker and retain in your logs.
As soon as your node would start to finish a filewalker and retain, the latter will move the garbage to the trash. After 7 days it will be permanently removed.
I have multiple nodes with this issue, all of which are old nodes. The newly created nodes do not have this issue. I wonder if it could be due to incorrect filter parameters
I moved your report here, because the previous one is talking about trash discrepancy, not between average used space and the actual used space.
Your issue 100% related to not working Garbage Collector/Retain.
Please search for errors related to gc-filewalker, lazyfilewalker and retain in your logs.
Until the filewalker will not finished successfully, the reatain process will not move the deleted data to the trash to match usage reported to the satellites (the left graph).