zgrep -v INFO /mnt/storagenode7/node/node.log-2024-07.gz
2024-07-07T05:13:59Z WARN piecestore:monitor Used more space than allocated. Allocated space is {"Process": "storagenode", "bytes": 1000000000000}
2024-07-07T05:18:55Z WARN reputation:service node scores worsened {"Process": "storagenode", "Satellite ID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE", "Total Audits": 8427, "Successful Audits": 7978, "Audit Score": 1, "Online Score": 0.9642857142857143, "Suspension Score": 1, "Audit Score Delta": 0, "Online Score Delta": -0.0357142857142857, "Suspension Score Delta": 0}
2024-07-07T05:18:55Z WARN reputation:service node scores worsened {"Process": "storagenode", "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "Total Audits": 51257, "Successful Audits": 48134, "Audit Score": 1, "Online Score": 0.9758301376230556, "Suspension Score": 1, "Audit Score Delta": 0, "Online Score Delta": -0.02271477663230237, "Suspension Score Delta": 0}
2024-07-07T05:18:56Z WARN reputation:service node scores worsened {"Process": "storagenode", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Total Audits": 66217, "Successful Audits": 61677, "Audit Score": 1, "Online Score": 0.9743768693918246, "Suspension Score": 1, "Audit Score Delta": 0, "Online Score Delta": -0.024731069948050632, "Suspension Score Delta": 0}
2024-07-07T05:18:56Z WARN reputation:service node scores worsened {"Process": "storagenode", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Total Audits": 95577, "Successful Audits": 88848, "Audit Score": 1, "Online Score": 0.9746806732775776, "Suspension Score": 1, "Audit Score Delta": 0, "Online Score Delta": -0.023725981620718484, "Suspension Score Delta": 0}
2024-07-07T08:39:31Z FATAL Unrecoverable error {"Process": "storagenode", "error": "context canceled"}
2024-07-07T18:11:49Z WARN piecestore:monitor Used more space than allocated. Allocated space is {"Process": "storagenode", "bytes": 1000000000000}
2024-07-07T18:12:08Z WARN reputation:service node scores worsened {"Process": "storagenode", "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "Total Audits": 51762, "Successful Audits": 48274, "Audit Score": 1, "Online Score": 0.9640551550933559, "Suspension Score": 1, "Audit Score Delta": 0, "Online Score Delta": -0.011774982529699662, "Suspension Score Delta": 0}
2024-07-07T18:12:09Z WARN reputation:service node scores worsened {"Process": "storagenode", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Total Audits": 66427, "Successful Audits": 61731, "Audit Score": 1, "Online Score": 0.962890876634392, "Suspension Score": 1, "Audit Score Delta": 0, "Online Score Delta": -0.011485992757432562, "Suspension Score Delta": 0}
2024-07-07T18:12:09Z WARN reputation:service node scores worsened {"Process": "storagenode", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Total Audits": 96094, "Successful Audits": 89022, "Audit Score": 1, "Online Score": 0.9638140066109109, "Suspension Score": 1, "Audit Score Delta": 0, "Online Score Delta": -0.010866666666666691, "Suspension Score Delta": 0}
2024-07-08T02:13:33Z WARN reputation:service node scores worsened {"Process": "storagenode", "Satellite ID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE", "Total Audits": 8441, "Successful Audits": 7989, "Audit Score": 1, "Online Score": 0.9571428571428572, "Suspension Score": 1, "Audit Score Delta": 0, "Online Score Delta": -0.0071428571428571175, "Suspension Score Delta": 0}
2024-07-08T02:13:33Z WARN reputation:service node scores worsened {"Process": "storagenode", "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "Total Audits": 51996, "Successful Audits": 48492, "Audit Score": 1, "Online Score": 0.9545372831066561, "Suspension Score": 1, "Audit Score Delta": 0, "Online Score Delta": -0.009517871986699844, "Suspension Score Delta": 0}
2024-07-08T02:13:34Z WARN reputation:service node scores worsened {"Process": "storagenode", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Total Audits": 66509, "Successful Audits": 61806, "Audit Score": 1, "Online Score": 0.9528468361439015, "Suspension Score": 1, "Audit Score Delta": 0, "Online Score Delta": -0.010044040490490458, "Suspension Score Delta": 0}
2024-07-08T02:13:34Z WARN reputation:service node scores worsened {"Process": "storagenode", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Total Audits": 96304, "Successful Audits": 89224, "Audit Score": 1, "Online Score": 0.9542578471906211, "Suspension Score": 1, "Audit Score Delta": 0, "Online Score Delta": -0.009556159420289756, "Suspension Score Delta": 0}
2024-07-08T04:33:23Z FATAL Unrecoverable error {"Process": "storagenode", "error": "context canceled"}
2024-07-12T12:38:13Z WARN reputation:service node scores worsened {"Process": "storagenode", "Satellite ID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE", "Total Audits": 8544, "Successful Audits": 8092, "Audit Score": 1, "Online Score": 0.9571428571428572, "Suspension Score": 1, "Audit Score Delta": 0, "Online Score Delta": -0.000765306122448961, "Suspension Score Delta": 0}
2024-07-13T16:08:07Z WARN contact:service Your node is still considered to be online but encountered an error. {"Process": "storagenode", "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "Error": "contact: failed to ping storage node using QUIC, your node indicated error code: 0, rpc: quic: lookup london.thomas-boehm.net on 10.91.0.10:53: read udp 10.85.10.2:47684->10.91.0.10:53: i/o timeout"}
2024-07-14T00:35:19Z WARN reputation:service node scores worsened {"Process": "storagenode", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Total Audits": 99911, "Successful Audits": 92831, "Audit Score": 1, "Online Score": 0.9557548531786448, "Suspension Score": 1, "Audit Score Delta": 0, "Online Score Delta": -0.00000000000000011102230246251565, "Suspension Score Delta": 0}
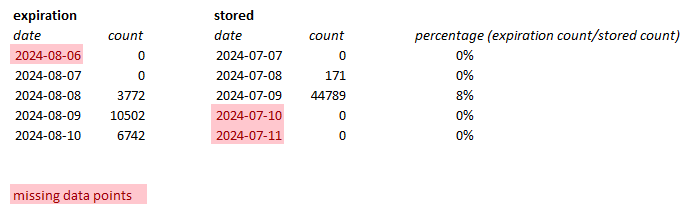
That’s all I have around these days without the INFO lines from this node. Nothing about databases.
I’m running the node with these custom loglevels
--log.custom-level=piecestore=FATAL,collector=FATAL,orders=WARN,reputation=WARN,bandwith=WARN
I did fill the form already for my biggest node. Will do it for this node too.