I know these “best practices”. However, i have been working the same way for years, more than 20. And i have never had issues. For example, both of my nodes have been running like that for years, without any issues. I started out with a single 1TB disk. Pretty much i am using old HW, that i have around me. I don’t want to invest.
I have an old workstation z800, that i plat to turn into a storjnode. Making it around 20TB. There i might consider some of these so called “best practices”. But i would never spare 2TB . Maybe 200GB, but we will see. It will take me years to fill in 15+TB anyway
how can it use more space, than it is allowed? And if does so … then what is the difference ? If i had 10% free space, then it would just eat them for more time, but that bug would eventually eat all of them, no matter how much free space you have
You may notice it before it’s too late and we likely will be able to fix a bug, it’s would buy some time.
But as I said, it’s still a recommendation, however I feel like 1% is too small for a normal operation.
I am running the defrag tool for almost 4 days and it is still below 14% done. Why is it so slow ? At this rate i am not sure if it will complete by the end of the year.
And as i stated previously in this thread, the % Fragmentation increases, instead of decreasing. This is also something i can not understand. When I tried it few days ago, like i wrote above, it was less than 16% and now as you can see it is above 30 %. Can anyone explain why and how exactly this tool works ?
But those files are relatively small. Around 2MB each, right ? I have almost 130GB free space. That’s about 130 000MB free space. That is a lot of space for such small files. Isn’t the purpose of defragmentation to collect all the pieces of one file and to combine them together somewhere on the free space area. Or I am missing valuable knowledge on this topic ?
No, some kb are the most files. The recommendation is 10% free space. For some Reasons, as stated before.
I suggest you set he node to free some space, through the yaml, and set it to 2.4TB, overused will appear and ingress will be stopped. that speeds things up also.
can take verry long under this circumstances. let it run, or make free space while running.
or stop it , reach 10%free and start then again.
also take care of the E drive, its pretty full.
Compare it with a open bucket of acid, you have to carry it by hand, do you fill it to the brim or maybe 10% less?
If bucket stands still, you can fill to the brim, but if you have to move it, then what do you do?
Since i use these two together, here i found an article about Primocache(30day test possible) and Ultradefrag (free use possible).
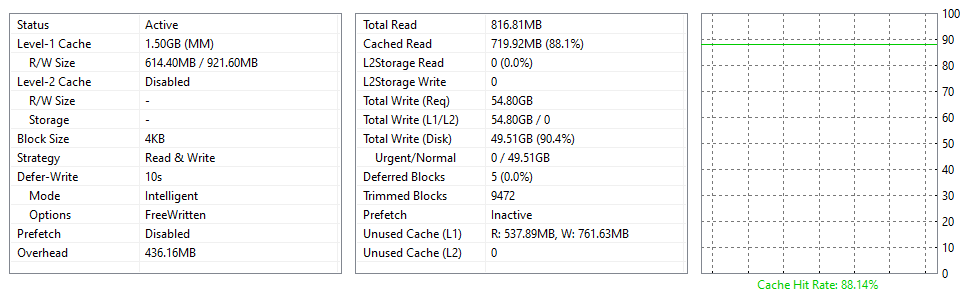
I bought both, the performance is unbeleavable, even the M2 nvme with the db and orders has ram cache now. The complete node, including all DBs, works now in RAM first, and after 10s data is writen to the drives. Reading of Node data is cached by NVME (500gb for a 20TB drive), Write by RAM.
NVME is cached by RAM (1-3GB is enough)
(As a bonus i cached my “slow” System SATA ssd with 12GB RAM )
This helps alot to win races, but also reduces wear leveling on the SSD, and prevents fragmentation on the HDD.
Verry usefull for SNO with native windows node and already some SSD space left over (50 to 500GB.) will be ok.
i estimated 25GB read-cache for 1 TB node data.
Notice that for write caching regardles of medium (ram or ssd or nvme) an UPS is recommendet to prevent data loss.
Read cache alone can be done without UPS.
I installed more RAM, (32 upgraded to 64GB /19GB free atm.) and despite it runs at a lower frequency now, its fast as f**k.
Newest Stats of my nodes:
1.node DB on USB,
2.node 1GB RAM Writecache(Primocache)
all nicely defragmanted
the 2. node gets around 80-100GB / Month more ingress than 1. (No Neighbors)
Also i made a crappy jpg to visualise the cache structure on the 2. node
Its an nvme pcie gen.3 so everything i have is slower exept ram aka L1.
I use L2 for the read cache of the hdd.
Its just another statistic wich i not posted as picture so far.
It counts as written for the os as soon data is in L1. So an additional L2 layer is pointless. In my case, i think.
Node writes are not that important to cache all of them for a long time.
As long an ups ensures the writes in case of power failure.
Readings from hdd will land in the L2 (500GB nvme)wich is located on the same nvme.(different hidden partition)
OMG why so much?
i have like 25GB of SSD space for a whole VM node instance, (windows 10 is installed and storj on that C:\ and has just enough space for logs, to rotate) so if i have 150TB total in 13 disks, i need 3,75TB of SSD to cache all that filewalkers?
can it be much less some how?
i just want to cache used-space-filewalker, and gc-filewalker
im interested with cache but not 25GB per 1TB “God, no, please, No”
EDIT: MFT for a 14,5TB storj’s disk, Ultradefrag shows me its 67,90GB of MFT
So i guess eventual cache should at least be able to deal with that?
Tho i don’t know if cacheing a disk’s MFT, will give the filewalker a files, it wants during the walk!
Hot node data also gets cached. (Actual it uses 325GB for 5TB node data, this may vary with node performance)
Small cache for MFT is not configurable in primocache. You select only drives letters.