This year I migrated all my nodes to ZFS to gain performance (special device etc.), which I gained. Now after reading (a bit lately) the Hashstore features with like 1GB blocks for almost only sequential reads etc. I’m asking myself, was it worth it to run nodes via ZFS? I learned a lot of stuff about ZFS, so in this case it wasn’t completely worthless. Now I’m thinking, when the mirgration is done, and features like Special Devices, caching etc. aren’t needed any more, which are special to ZFS, is it still worth to run it like that? What do you think about it?
It’s up on you. It should work good on any filesystem, that’s was one of the reasons for migration.
ZFS might be useful from a resiliency standpoint.
(conversely, I don’t know if a copy on write filesystem will play nice with compacting the 1GB files over a long time).
I can imagine aggressive caching might help with performance, since some folks have reported lower success rates with hashstore.
Probably, almost every file system will be “just fine”. So ZFS won’t be bad, it just won’t be superior. And a special vdev for metadata may not show a performance difference.
…but migration to hashstore did free up 80-100GB / node on my special, so it can be used for other purposes. This could still include DB + logs + orders for nodes.
Performance wise, I’ve seen far lower IO cost on ZFS with hashstore vs piecestore - so it’s still a good setup. I have not tested other filesystems, as my genuine opinion still is that ZFS is one of the few truely configurable and versatile filesystems for mixed workloads.
But, I did change from 1M recordsize to 128k after migration.
Why did you change from 1M to 128k? The hashstore files are large, so bigger recordsize should be useful.
Are you still using a special device for metadata or moved metadata back to hdd? Less metadata meaning less i/o and they will definitly fit in arc…
Updates are still small. 1MB did not matter because if the file was smaller it would have occupied the min of its size and record size. But these files are huge. So I had to reduce record size.
I did not install special device for storj – I installed it for myself. Storj just benefitted from it. So special device remains. BTW, you can’t remove special device if there is top level raidz.
Because the avg size of pieces on my nodes are ~220k
True, but I have different usecases for special - I still have orders, logs and DB on special.
I’m just setting my small blocks high enough that all goes to special. This causes it to function as if it was on a separate pool on SSD. Some would call it abuse of special, I do it to optimize the use of various performance tiers. Special is - despite what some think - a vdev like any other in the pool - just far more configurable ![]()
Additionally, my setup is not dedicated to Storj - so it’s main / heavy use is other workloads, and I just happened to have a few TB of free special vdev space in my pool.
This is the histogram from the 1.5 year old node
(script not mine, stole from truenas forum I think):
# find . -type f -print0 | xargs -0 ls -l | awk '{ n=int(log($5)/log(2)); if (n<10) { n=10; } size[n]++ } END { for (i in size) printf("%d %d\n", 2^i, size[i]) }' | sort -n | awk 'function human(x) { x[1]/=1024; if (x[1]>=1024) { x[2]++; human(x) } } { a[1]=$1; a[2]=0; human(a); printf("%3d%s: %6d\n", a[1],substr("kMGTEPYZ",a[2]+1,1),$2) }'
1k: 1825814
2k: 1263422
4k: 1680767
8k: 1619281
16k: 1687736
32k: 1877409
64k: 973935
128k: 2528393
256k: 782954
512k: 448908
1M: 266789
2M: 855837
So, 64-128k sizes represent local peak, at 2.5M pieces. Cummulative size of sub-32kb pieces is 8M. So perhaps 32k record size would have been more appropriate?
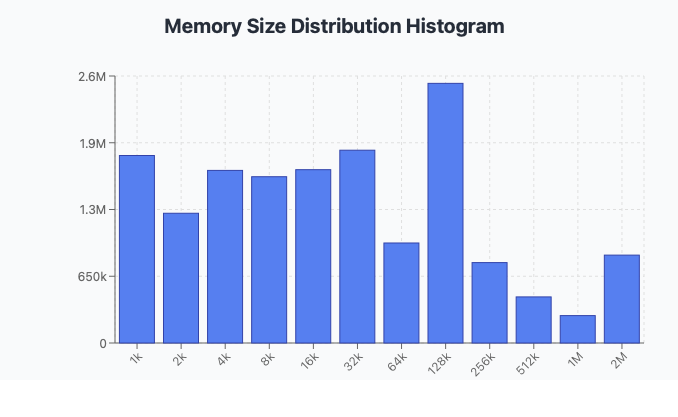
These sub-32kb pieces I used to send to special device. Now it will be impossible to do.
+1. Databases are on the separate dataset that is configured to send all to special device.
Who thinks special device is not a vdev?
And some call it taking advantage of its full potential.
I mayh be biased, my special device is a pair of 2TB P3600 for historical reasons.
Thinking about it, I’m settign record size to 32k, migration still in progress.
Yes, quite possibly. I’ll add it to my list of to-do’s when time permits.
Let us know what your findings are, might save me a rainy sunday ![]()
Unfortunately, many. Seems some apparently just interpret the “special” name and make up their own understanding of it.
I’ve run into this perception many times that special is so “special” is can only be used for metadata and a tiering offloading of sub-recordsize data.
Had conversation with peers about such “creative” uses of special in the past.
Nice devices - i wanted to use the PCIe versions, but don’t have the available slots. So mostly I use Samsung PM893 or similar in 2 or 4TB editions, very durable and performant.
Deeper into the rabbit hole:
1.5 yo node:
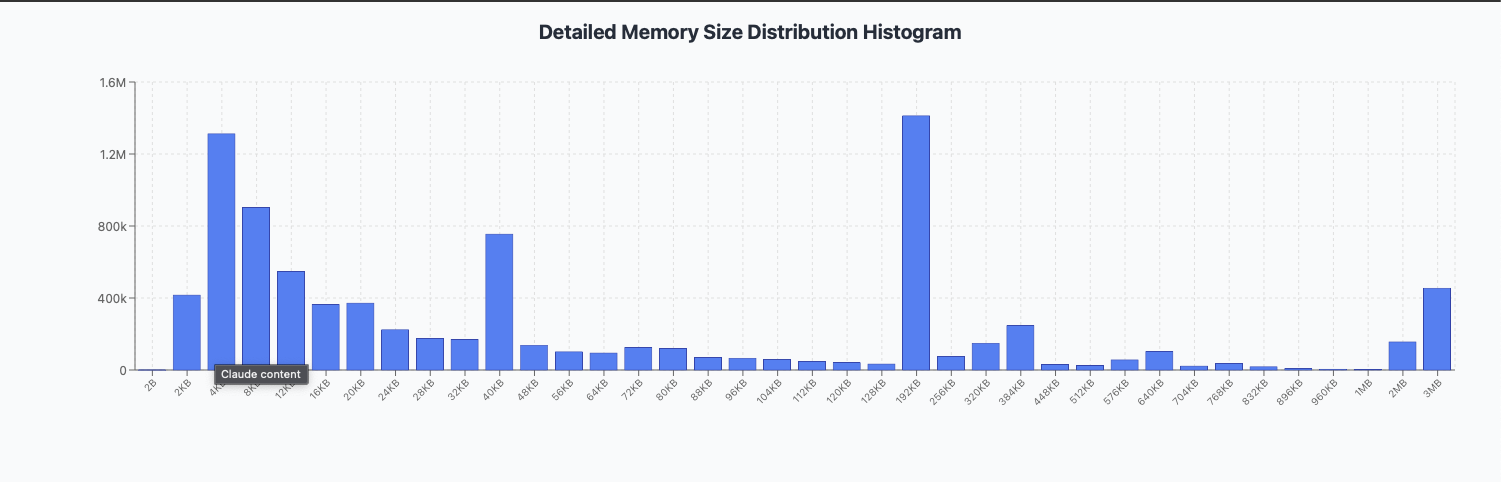
3 yo node
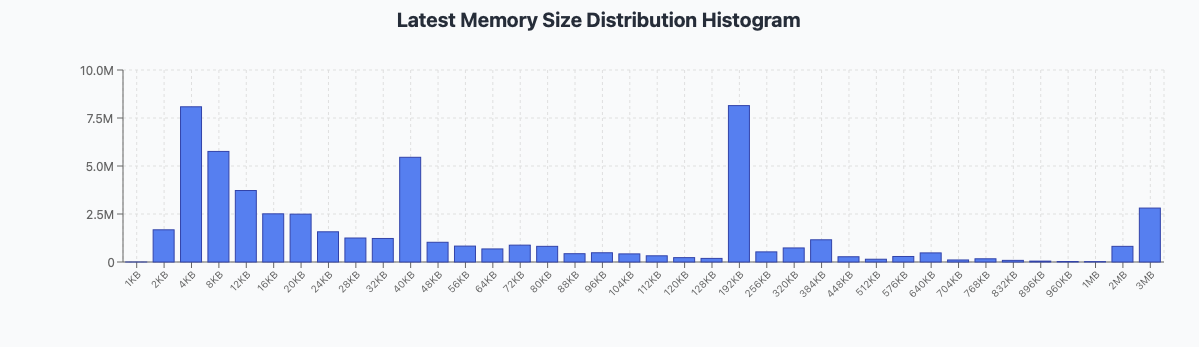
Still looks like 32k is the way to go.
Curiously, combining all sizes up to 32kb, 64k, 128k into the same bucket, and showing the rest as equivalent of 32k, 64k, adn 128k chunks:
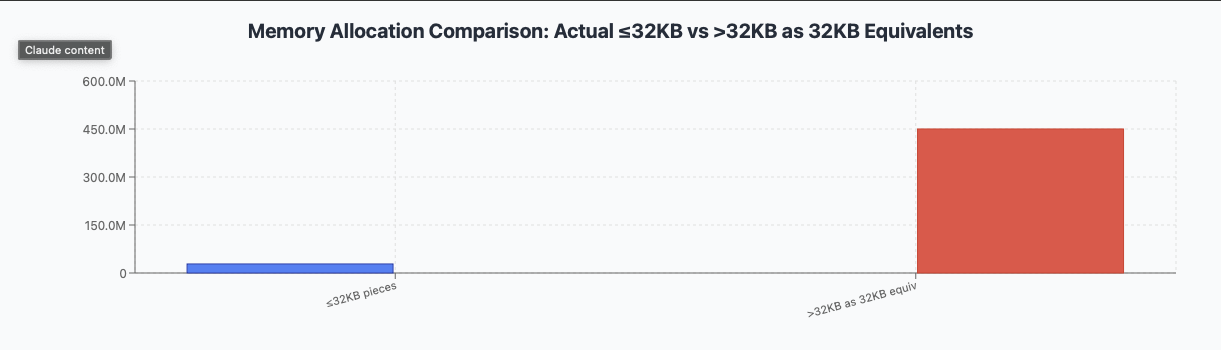
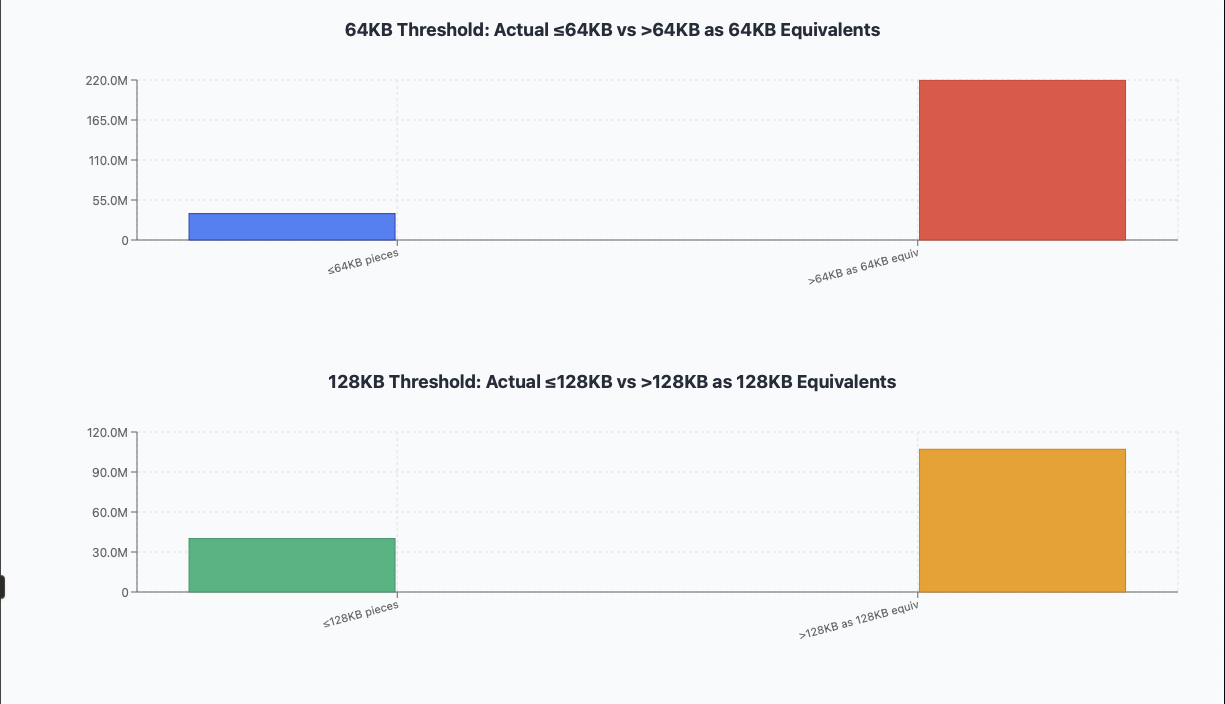
On this plot the blue bar shows number of pieces below theshold, and the right one – amount of effecitive pieces equal to threshodl that fit into the cummulative size.
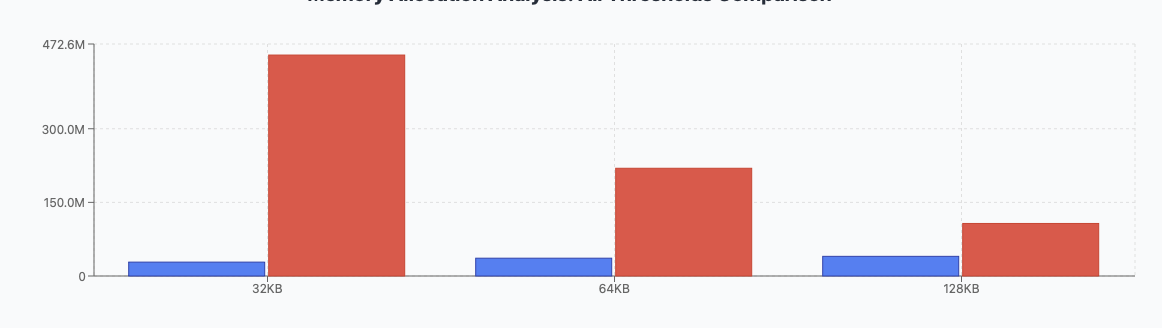
The compromize here is amount of data being rewritten VS amount of extra metatata: when reducing record size from 128k to 32k we are trading 3-4x metadata size increase for elimination of read-modify-write for about 50% of data. Seems a very worthwhile tradeoff.
If the spefcial device is too small to fit all that – then 64k would be a good point to consider
the new hashstore uses files of 1GB size. Shouldn’t it be better to use a large recordsize?
I don’t know how the hashstore handles the uploaded files and when it flushes them to disk (and what buffersizes it uses). Additionally maybe this is also depending on the used parameters/configuration (e.g. memtbl) for the hashtable.
My assumptions are:
- if using a small recordsize, the data read from the hdd has almost the data in it we are looking for → no unrelated data from the hdd
- if the size of the file we are looking for is bigger than the recordsize, then n-more-reads must be made → more iops necessary
- hashtable compaction reads the whole data from hdd and re-writes it to disk → bigger recordsize would be useful here
correct?
I wonder why would you need to optimize manually this behavior. Appending to a file should be such a common operation that ZFS certainly already optimizes for it through other means? I mean, almost no file is written in a single go.
The file size is not what dictates optimal recordsize; how data is written is. But see below…
The real reason is because I shoud have gone to sleep and not mess with crap at 2 AM, that’s why.
Writes:
So, here what was my thought process. I assumned (which, today’s me realized was a bullshit assumption) that hastore randomly writes small pieces to random logs. ZFS coalesces transactions into groupsp and writes all at once, but if a lot of files get a lot of small appends read-modify-write amplification becomes a concern. So smaller record size helps.
However, this is not what hashstore does. Hashstore (IIUC) writes data to a few actice logs (selected by TTL), and already groups and coalesces writes. So, there are no small writes at all. Large record size shall be appropriate.
Reads:
Storagenode will read pieces probably predominantly randomly, with maybe a few pieces repeated. The repeated once will get eventually cached, so they are not a factor. Random small reads (meaning no spatial locality) will experience read amplification: even if the app requests 16k block, the whole recordsize worth of data will be fetched.
How important it is - i’d argue not much. Maybe it will add a few ms of read latency. But we already have huge latency reading from HDD anyway. Quadrupling of read bandwidth from disks also won’t matter – because seek latency dominates, we’ll probably go from 10MBps to 40MBps – not a factor at all.
And yet, downsize of small record size is a lot more bookkeeping on special device.
Caching is also won’t be affected much-- there is usualy not many hot pieces.
So, it seems we shall keep recordsize at default and don’t mess with things that don’t need to be messed with.
Can you check what are actual append sizes that hasshtore sees do you obsver? (I can’t, because of in-progress migration, everythign will be super sequential)
Default (128K) or higher as default (1 or 2 MB)? Will it make a difference?
1MB write every secodn means about 400GB written per month. Since writes go to a number of logs at a time this will guarantee that all writes will result in read/modify/write.
On the reading side – same thing: to read a frequently occuring 16k piece block entire 1MB record would need to be read. Quite a lot of waste. This will also waste space in ARC.
Defaults are chosen to work in vast majority of cases. Tuning defaults makes sense when you experince a very specific bottleneck – then you tune for that specifically. But the whole point of hashstore was to have node become a good citizen – so default everythign shall work well.
Been there, done that ![]()
.. sleep well knowing you contributed valueable input!
Yes! Here’s the raw output:
Sun Sep 14 06:11:32 CEST 2025
pool1 sync_read sync_write async_read async_write scrub trim
req_size ind agg ind agg ind agg ind agg ind agg ind agg
---------- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- -----
512 0 0 0 0 0 0 0 0 0 0 0 0
1K 0 0 0 0 0 0 0 0 0 0 0 0
2K 0 0 0 0 0 0 0 0 0 0 0 0
4K 3 0 15 0 0 0 81 0 0 0 0 0
8K 0 0 0 0 0 0 29 24 0 0 0 0
16K 0 0 1 0 0 0 28 14 0 0 0 0
32K 130 0 0 0 105 0 48 15 0 0 0 0
64K 0 0 2 0 0 4 8 29 0 0 0 0
128K 0 0 0 0 0 5 0 15 0 0 0 0
256K 0 0 0 0 0 1 0 14 0 0 0 0
512K 0 0 0 0 0 0 0 6 0 0 0 0
1M 0 0 0 0 0 0 0 0 0 0 0 0
2M 0 0 0 0 0 0 0 0 0 0 0 0
4M 0 0 0 0 0 0 0 0 0 0 0 0
8M 0 0 0 0 0 0 0 0 0 0 0 0
16M 0 0 0 0 0 0 0 0 0 0 0 0
----------------------------------------------------------------------------------------------
Sun Sep 14 06:11:47 CEST 2025
pool1 sync_read sync_write async_read async_write scrub trim
req_size ind agg ind agg ind agg ind agg ind agg ind agg
---------- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- ----- -----
512 0 0 0 0 0 0 0 0 0 0 0 0
1K 0 0 0 0 0 0 0 0 0 0 0 0
2K 0 0 0 0 0 0 0 0 0 0 0 0
4K 4 0 37 0 0 0 183 0 0 0 0 0
8K 0 0 1 0 0 0 52 57 0 0 0 0
16K 0 0 1 0 0 0 53 33 0 0 0 0
32K 145 0 0 0 122 0 69 29 0 0 7 0
64K 0 0 1 0 0 5 20 39 0 0 9 0
128K 0 0 0 0 0 7 0 28 0 0 9 0
256K 0 0 0 0 0 2 0 8 0 0 7 0
512K 0 0 0 0 0 0 0 5 0 0 3 0
1M 0 0 0 0 0 0 0 0 0 0 1 0
2M 0 0 0 0 0 0 0 0 0 0 0 0
4M 0 0 0 0 0 0 0 0 0 0 0 0
8M 0 0 0 0 0 0 0 0 0 0 0 0
16M 0 0 0 0 0 0 0 0 0 0 0 0
----------------------------------------------------------------------------------------------
The 4k async-writes are primarily dominated by rrd files every minute (not related to StorJ), so should be disregarded.
I did however stop a few other IO heavy tasks while performing this.
Here’s a headmap for a few minutes, smoothed over a couple of samples for better visualisation:
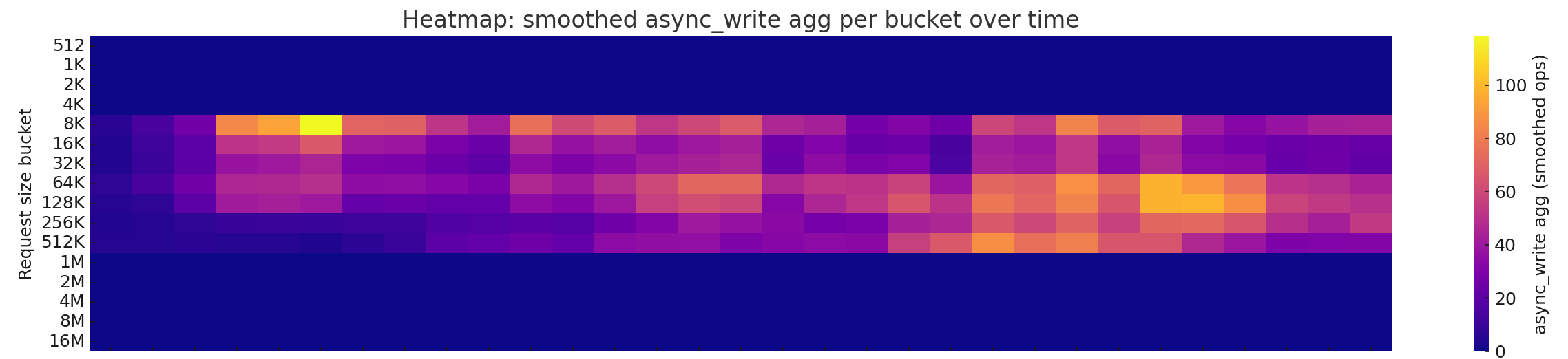
Interval between vertical lines are 15 sec with 10 sec txg timing.
That looks like decent enough data in favour of 128k record size.
There’s some 4k/8k stuff, but even if it’s the StorJ node and not external sevices running ZFS with 8k records isn’t really realistic.
The 16k and 32k ranges are less active and the majority is in the 64k - 512k range.
Maybe 64k records could be worth it, especially if people are running 5sec TXGs and really care about ARC usage, but I’d argue for 128k and 10-15sec TXGs before switching to 64k.