# how frequently bandwidth usage rollups are calculated
# bandwidth.interval: 1h0m0s
preflight.database-check: true
# how frequently expired pieces are collected
# collector.interval: 1h0m0s
# use color in user interface
# color: false
# server address of the api gateway and frontend app
console.address: localhost:14004
# path to static resources
# console.static-dir: " "
# the public address of the node, useful for nodes behind NAT
contact.external-address: (xxxxxxxxx).duckdns.org:28969
# how frequently the node contact chore should run
# contact.interval: 1h0m0s
# Maximum Database Connection Lifetime, -1ns means the stdlib default
# db.conn_max_lifetime: -1ns
# Maximum Amount of Idle Database connections, -1 means the stdlib default
# db.max_idle_conns: 20
# Maximum Amount of Open Database connections, -1 means the stdlib default
# db.max_open_conns: 25
# address to listen on for debug endpoints
# debug.addr: 127.0.0.1:0
# If set, a path to write a process trace SVG to
# debug.trace-out: " "
# open config in default editor
# edit-conf: false
# how often to run the chore to check for satellites for the node to exit.
# graceful-exit.chore-interval: 15m0s
# the minimum acceptable bytes that an exiting node can transfer per second to the new node
# graceful-exit.min-bytes-per-second: 128 B
# the minimum duration for downloading a piece from storage nodes before timing out
# graceful-exit.min-download-timeout: 2m0s
# number of concurrent transfers per graceful exit worker
# graceful-exit.num-concurrent-transfers: 1
# number of workers to handle satellite exits
# graceful-exit.num-workers: 3
# path to the certificate chain for this identity
identity.cert-path: C:\Users\Matao\AppData\Roaming\Storj\Identity3\storagenode\identity.cert
# path to the private key for this identity
identity.key-path: C:\Users\Matao\AppData\Roaming\Storj\Identity3\storagenode\identity.key
# if true, log function filename and line number
# log.caller: false
# if true, set logging to development mode
# log.development: false
# configures log encoding. can either be 'console' or 'json'
# log.encoding: console
# if true, log function filename and line number
# log.caller: false
# if true, set logging to development mode
# log.development: false
# configures log encoding. can either be 'console' or 'json'
# log.encoding: console
# the minimum log level to log
log.level: info
# can be stdout, stderr, or a filename
log.output: winfile:///C:\Program Files\Storj2\Storage Node\\storagenode.log
# if true, log stack traces
# log.stack: false
# address to send telemetry to
# metrics.addr: collectora.storj.io:9000
# application name for telemetry identification
# metrics.app: storagenode.exe
# application suffix
# metrics.app-suffix: -release
# instance id prefix
# metrics.instance-prefix: " "
# how frequently to send up telemetry
# metrics.interval: 1m0s
# path to log for oom notices
# monkit.hw.oomlog: /var/log/kern.log
# maximum duration to wait before requesting data
# nodestats.max-sleep: 5m0s
# how often to sync reputation
# nodestats.reputation-sync: 4h0m0s
# how often to sync storage
# nodestats.storage-sync: 12h0m0s
# operator email address
operator.email: (xxxxxx)@hotmail.com
# operator wallet address
operator.wallet: 0x71461a6f8fb56eexxxxxxxxxxxxxxxxxxxxxxxxxxxxx
# how many concurrent retain requests can be processed at the same time.
# retain.concurrency: 100
# allows for small differences in the satellite and storagenode clocks
# retain.max-time-skew: 24h0m0s
# allows configuration to enable, disable, or test retain requests from the satellite. Options: (disabled/enabled/debug)
# retain.status: enabled
# public address to listen on
server.address: :28969
# log all GRPC traffic to zap logger
server.debug-log-traffic: false
# if true, client leaves may contain the most recent certificate revocation for the current certificate
# server.extensions.revocation: true
# if true, client leaves must contain a valid signed certificate extension (NB: verified against certs in the peer ca whitelist; i.e. if true, a whitelist must be provided)
# server.extensions.whitelist-signed-leaf: false
# path to the CA cert whitelist (peer identities must be signed by one these to be verified). this will override the default peer whitelist
# server.peer-ca-whitelist-path: " "
# identity version(s) the server will be allowed to talk to
# server.peer-id-versions: latest
# private address to listen on
server.private-address: 127.0.0.1:7780
# url for revocation database (e.g. bolt://some.db OR redis://127.0.0.1:6378?db=2&password=abc123)
# server.revocation-dburl: bolt://C:\Program Files\Storj2\Storage Node/revocations.db
# if true, uses peer ca whitelist checking
# server.use-peer-ca-whitelist: true
# total allocated bandwidth in bytes
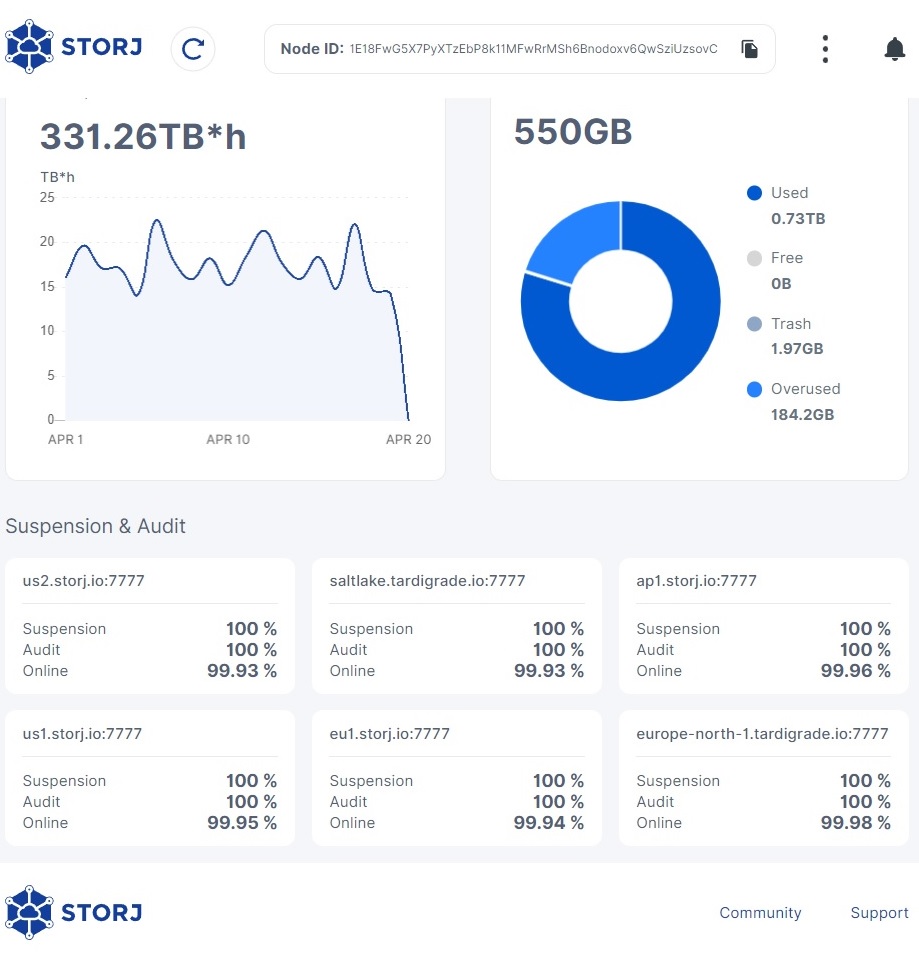
storage.allocated-bandwidth: 0TB
# total allocated disk space in bytes
storage.allocated-disk-space: 0.55 TB
# how frequently Kademlia bucket should be refreshed with node stats
# storage.k-bucket-refresh-interval: 1h0m0s
# path to store data in
storage.path: F:\
# path to databases
Storage2.Database-Dir: F:\
# a comma-separated list of approved satellite node urls
# storage.whitelisted-satellites: 12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S@mars.tardigrade.io:7777,118UWpMCHzs6CvSgWd9BfFVjw5K9pZbJjkfZJexMtSkmKxvvAW@satellite.stefan-benten.de:7777,121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6@saturn.tardigrade.io:7777,12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs@jupiter.tardigrade.io:7777
# how often the space used cache is synced to persistent storage
# storage2.cache-sync-interval: 1h0m0s
# how soon before expiration date should things be considered expired
# storage2.expiration-grace-period: 48h0m0s
# how many concurrent requests are allowed, before uploads are rejected.
#storage2.max-concurrent-requests: 40
# how frequently Kademlia bucket should be refreshed with node stats
# storage2.monitor.interval: 1h0m0s
# how much bandwidth a node at minimum has to advertise
# storage2.monitor.minimum-bandwidth: 500.0 GB
# how much disk space a node at minimum has to advertise
# storage2.monitor.minimum-disk-space: 500.0 GB
# how long after OrderLimit creation date are OrderLimits no longer accepted
# storage2.order-limit-grace-period: 1h0m0s
# length of time to archive orders before deletion
# storage2.orders.archive-ttl: 168h0m0s
# duration between archive cleanups
# storage2.orders.cleanup-interval: 24h0m0s
# timeout for dialing satellite during sending orders
# storage2.orders.sender-dial-timeout: 1m0s
# duration between sending
# storage2.orders.sender-interval: 1h0m0s
# timeout for read/write operations during sending
# storage2.orders.sender-request-timeout: 1h0m0s
# timeout for sending
# storage2.orders.sender-timeout: 1h0m0s
# allows for small differences in the satellite and storagenode clocks
# storage2.retain-time-buffer: 1h0m0s
# Interval to check the version
# version.check-interval: 15m0s
# Request timeout for version checks
# version.request-timeout: 1m0s
# server address to check its version against
# version.server-address: https://version.storj.io
this reminds me of my issues with the multinode dashboard, which i couldn’t get to accept some of my nodes… then after ages just accepting it didn’t work, i realized i had named some of my nodes wrong, so i was trying to add the same nodes multiple times… tsk tsk…
each node has a unique id, i think the odd of it being mixed up is near zero…
but i duno… just saying i think it’s most likely user error.
then i have no clue what happening, because sattelite tell the node what file is uploaded and can be deleted from its node.
Also on picture we can see that size of data is about 8TB, and in the config there is only 500 gb is size of node.
If you used the correct identity path and correct config path - it will start GE for this node.
If you messed up identity and config path - it could disqualify your node, because data will not match the identity, so all data will be missing and all data is a garbage…
What’s storagenode.exe exit-status says for both nodes?
Please also check logs for both nodes, on exiting node you should see messages related to graceful exit (pattern gracefulexit or grace).