Am I doing something wrong with this node?
I allocated only 7Tb. How many Terabytes do I need to share in order to make this at least worth the effort?
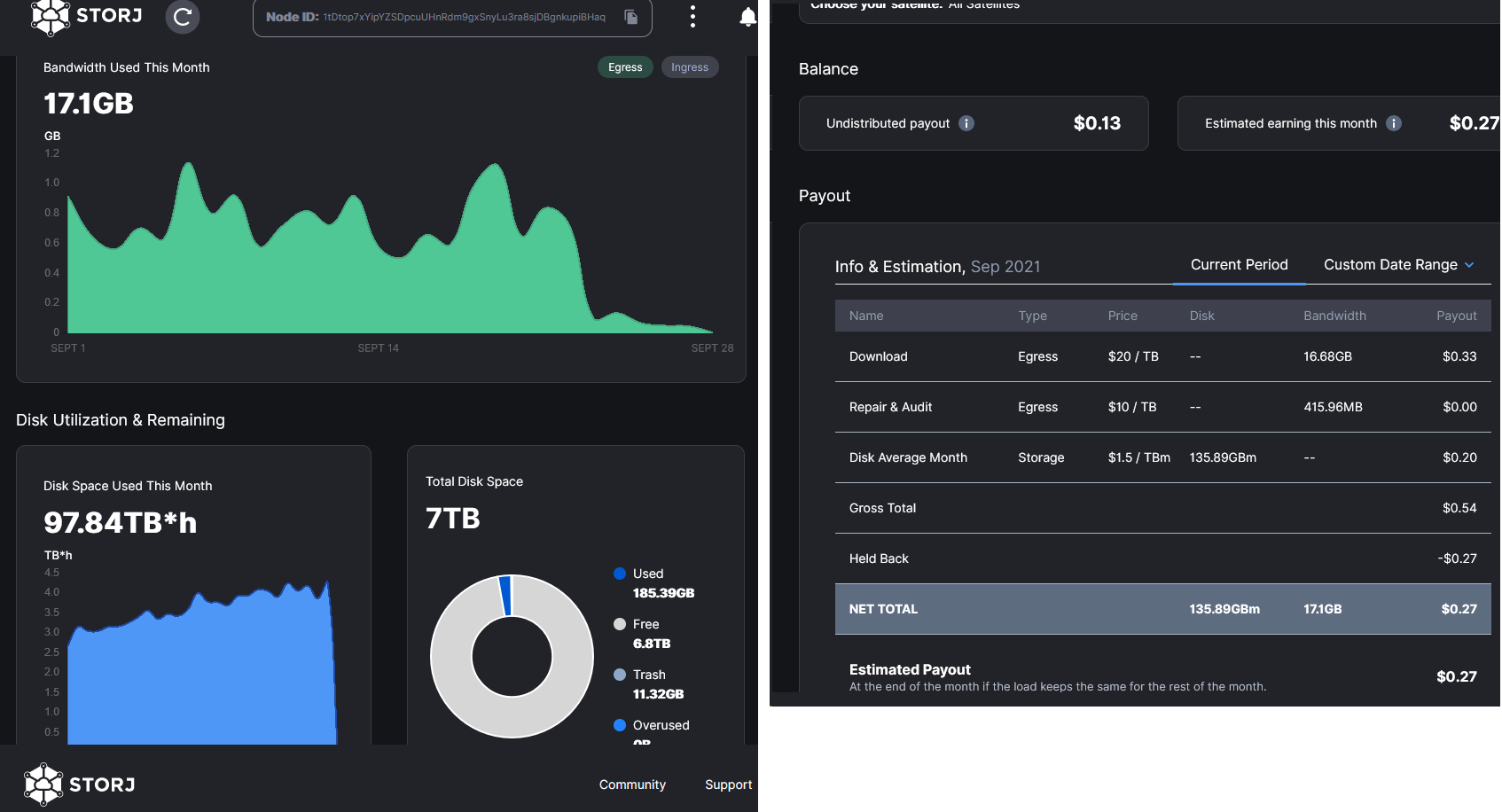
How much did you expect to earn to make it worth the effort?
May I ask when you started that node?
Hello @aer4af ,
Welcome to the forum!
This is not mining, adding hardware would not have a significant effect on usage, because it’s used by real people, not machines. There are some exceptions like using the network connected drives for storage or SMR drives or use devices with too low RAM (less than 500MB), which can significant lower income because such hardware become a bottleneck, however the minimum recommended specifications you can see there: Prerequisites - Node Operator
Each new node must be vetted. While in vetting your node can receive only 5% of customers’ uploads until got vetted. To be vetted on one satellite, the node should pass 100 audits from it. For the one node in the /24 subnet of public IPs this should take at least a month. If you would start several nodes (or you have neighbors in the same subnet of public IPs), the vetting could take longer.
You can use this Earnings calculator (Update 2021-06-11: v10.2.1 - Detailed payout information: Now includes comparison to actual payout, postponed payouts due to threshold and transaction links!) to check your vetting progress.
All nodes in the same /24 subnet of public IPs treated as a one node for uploads (ingress) and as a separate ones for downloads (egress) by the customers’, audit and uptime checks - we want to be decentralized as much as possible.
You can use this Realistic earnings estimator to have an idea how long it may take to fill-up all free space and how much you may earn.
In short - this is a long run project. It’s better to use hardware which will be online anyway - with Storj or without, thus any income would be a pure profit and nice discount to your bills.
We don’t recommend to make any investments only for Storj - you could have no ROI any time soon.







It’s from the site uptimerobot.com
It would be good for comparison if it was from the same place, e.g. uptimerobot to each SN


Thank you for your information.
@Stob @peem Ping doesn’t matter, especially to satellites - data is coming from the customers of these satellites, not from satellites. The satellite is address book, audit, repair and payment processor, it doesn’t proxy customers’ data. So it can be in Arctica and nothing would change from SNO point of view.
You need to measure ping to the customers, but it’s still not correct, because the node and the uplink exchanges by messages (high level packets). You can have a perfect ping but slow HDD and almost any upload will fail.
That’s why I suggested as above for comparative purposes ![]()
Ping must reflect some of the differences in node earnings, as the whole long tail process forces response times to matter. When you think about a request to a storagenode a ping would represent the transit time without waiting on the disk for data. Whilst I agree ping to satellites isn’t ideal, it should be a good starting point for gateway-mt and repair response times (assuming those processes run in the same location as satellites).
What do you propose to check to find out why there is such a disproportion in earnings similar in the time of the operating SN?
How else to check the number of nodes in the /24 subnet?
Checking with uptimerobot would only tell you about your ping to the uptimerobot servers and different nodes may even be checked by different servers. So you can’t really use that.
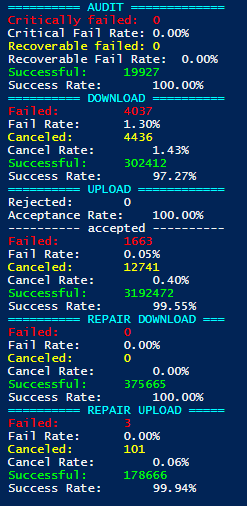
We should probably start out by checking whether latency is actually causing transfers to be cancelled in long tail cancelation. You can use the success rate scripts for that, but you would need a bit of history in logs.
If those success rates look good then it’s not latency.

That looks quite alright actually. Slightly worse than my results, but wouldn’t explain the difference. Has the node been offline at times for more than 4 hours?