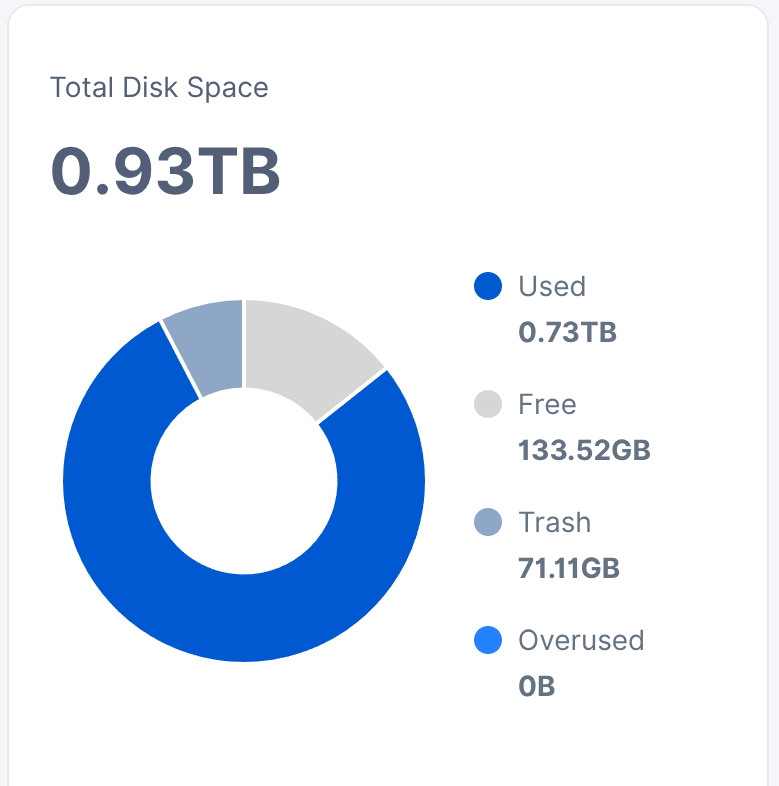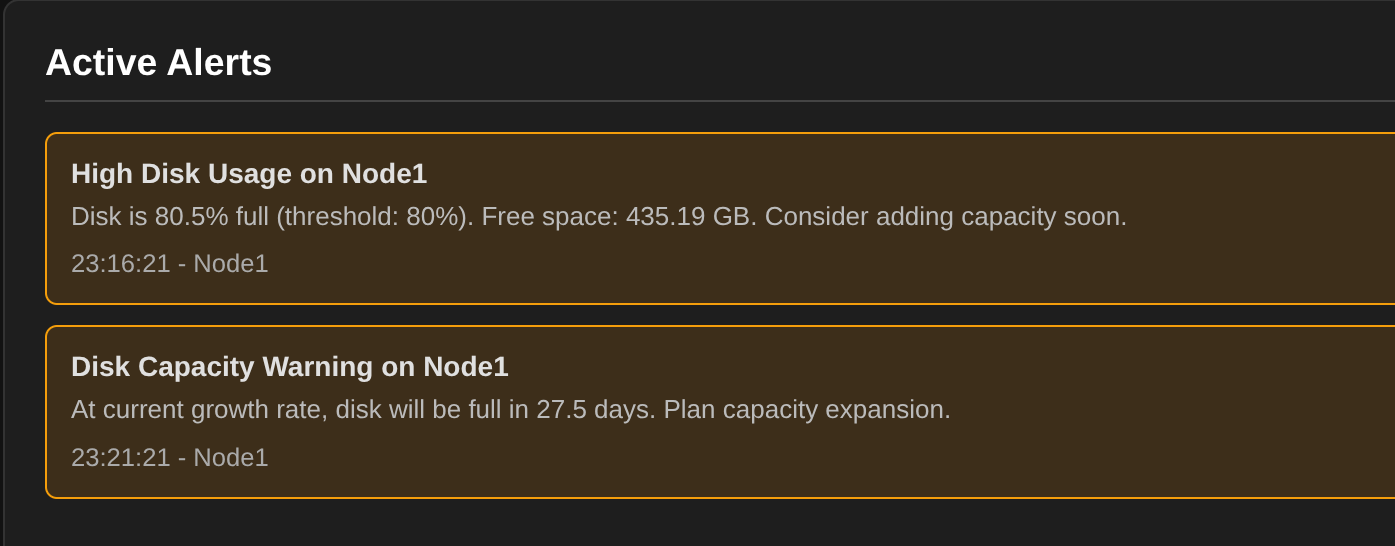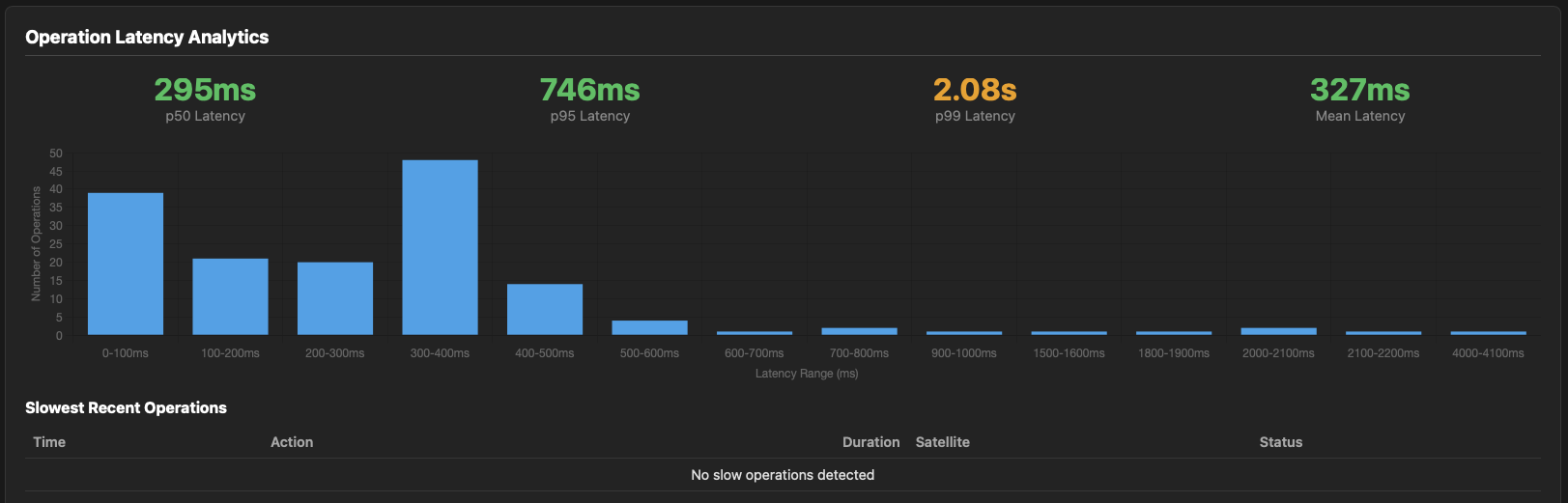
2025-10-04 21:58:07 [WARNING] [StorjMonitor.LogProcessor] [Node 1] High calculated duration: 34704ms for PUT, piece=YUCUZCIA5QETVWGC...
storj# grep YUCUZCIA5QETVW /var/log/storj.log
2025-10-04T21:57:32-07:00 DEBUG piecestore upload started {"Process": "storagenode", "Piece ID": "YUCUZCIA5QETVWGCFJPDZONQBZSWUUB6CEKDNIKBTZVTUD66VYEQ", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Action": "PUT", "Remote Address": "79.127.219.42:35642", "Available Space": 14543107381248}
2025-10-04T21:58:07-07:00 INFO piecestore uploaded {"Process": "storagenode", "Piece ID": "YUCUZCIA5QETVWGCFJPDZONQBZSWUUB6CEKDNIKBTZVTUD66VYEQ", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Action": "PUT", "Remote Address": "79.127.219.42:35642", "Size": 656640}
See what happened here? upload took 35 seconds!? Holy moly!
Or look at thsi crap:
storj# grep PU5JU5J47IS53KSVQM /var/log/storj.log
2025-10-04T22:33:14-07:00 DEBUG piecestore upload started {"Process": "storagenode", "Piece ID": "PU5JU5J47IS53KSVQMA6WYD75YLASWR4IZUSYPV3OB3B7NJDG72Q", "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "Action": "PUT", "Remote Address": "157.48.251.24:51198", "Available Space": 14541764176384}
2025-10-04T22:34:18-07:00 INFO piecestore uploaded {"Process": "storagenode", "Piece ID": "PU5JU5J47IS53KSVQMA6WYD75YLASWR4IZUSYPV3OB3B7NJDG72Q", "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "Action": "PUT", "Remote Address": "157.48.251.24:51198", "Size": 2319360}
Are you saying the client was uploading 2MB of data for 64 seconds!?
(There was a dicrepancy when DEBUG and INFO messges woudl arrive delayed by different amount, so time-of-arrival could not be used, and timestamp in the log is is rounted to 1 sec. Now it uses time of arrival if it is within 4 sec, othersiee – timestamp. Hopfeully timestamp in the log is reliable)