My 16 - 17 month old node failed an audit.
i don’t believe i lost a file, however it is an old node and has been migrated a fair number of times … maybe 7 … so it’s not totally impossible that i could have lost a file… and have like most other long term SNO’s ofc had various issues over my time running the node… so i suppose that could have cause a snag along the way.
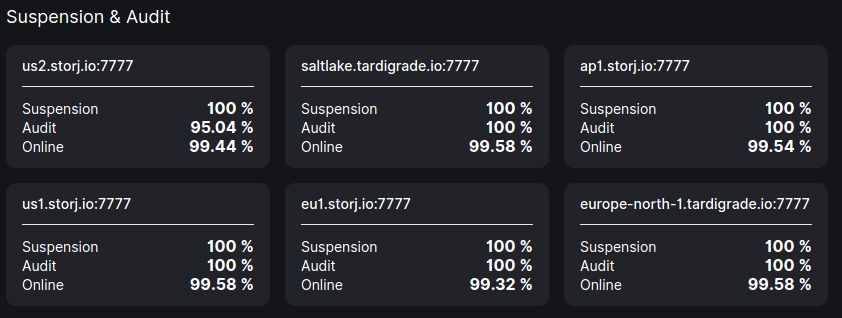
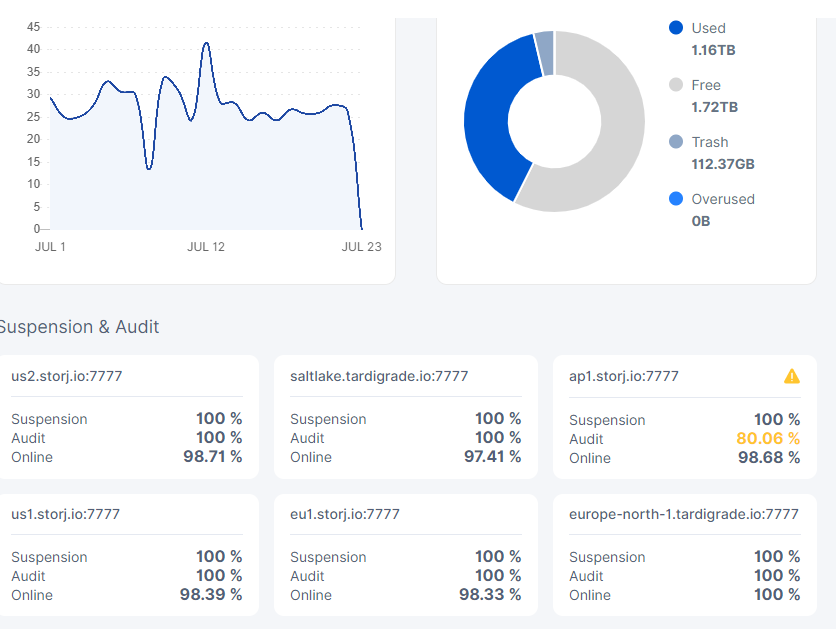
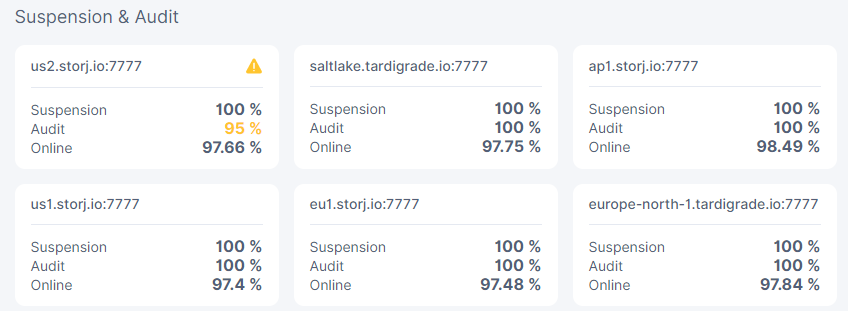
that being said… the numbers i’m seeing in the storagenode dashboard doesn’t quite corollate to my logs… i’m seeing a 95% audit failure on the dashboard.
however when i run a ./successrate.sh over the last 3 days, i’m getting a 1 audit failed of 7000+
even if this was over a 1 day period 95% is many multiples above what happened…
splitting the audits over 30 days it would be 200 audits per day and thus failing 1 would still only be like 0.5%
I started a scrub to check my data integrity of my pool, which are running on a zfs with a raidz1 with redundancy and atleast on the 12th this month didn’t show any signs of data corruption.
so should know sometime tomorrow if the pool is fine… but i’m pretty sure it is… if there was a file missing zfs should have complained about it corruption…
i doubt this will escalate, most likely i assume this to vanish and recover…
but with brightsilence’s new audit system possibly being introduced, and it supposely failing nodes in short order for more than 2% audit failures… my dashboard showing a 5% failure rate is unacceptable as i’m very sure i haven’t lost files nor are any corruption or such involved.
anyone else seeing anything like this… seems very weird to me… also i just updated to the new version less than 24 hours ago… so i really hope it’s not an issue with the new version…
since i did feel jumping onboard only 12 hours in was a bit rash.
there is ofc the off chance that its just my old node actually missing a file… but its not that likely either… pretty sure all my migrations have been flawless.
hope this is not a network issue, because then it could be rather serious.
5% failure in audits on the dashboard for 1 failed audit in the logs over 3 days
seems excessive…
and this hasn’t show up before… this if the first time i see the audits successes drop below 100% ever… last checked it like 24-48 hours ago.