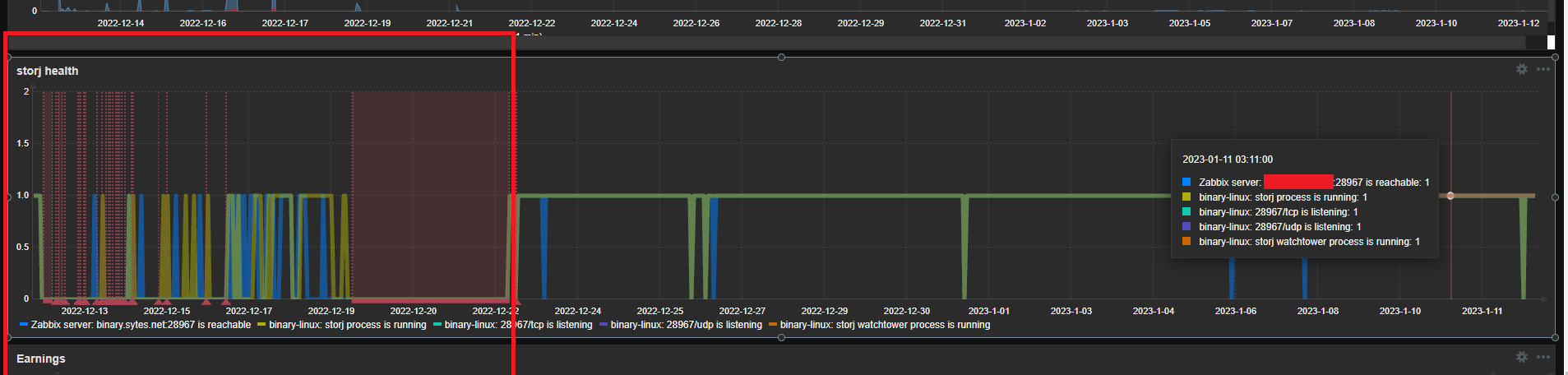
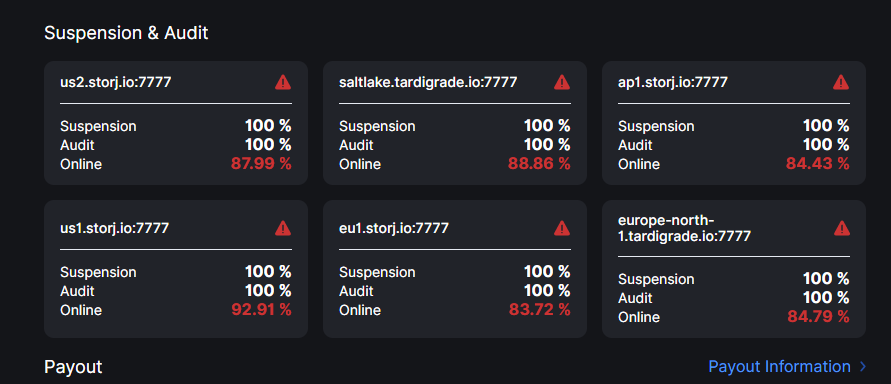
Node is not disqualified or suspended. Node is not offline.
The only thing worth to mention is that month ago I had issues with disk and had to replace it. Replication to another disk took a while, so there was a noticeable downtime (see graphs). That resulted into low “online” score, but this score should have started to grow up exactly now…
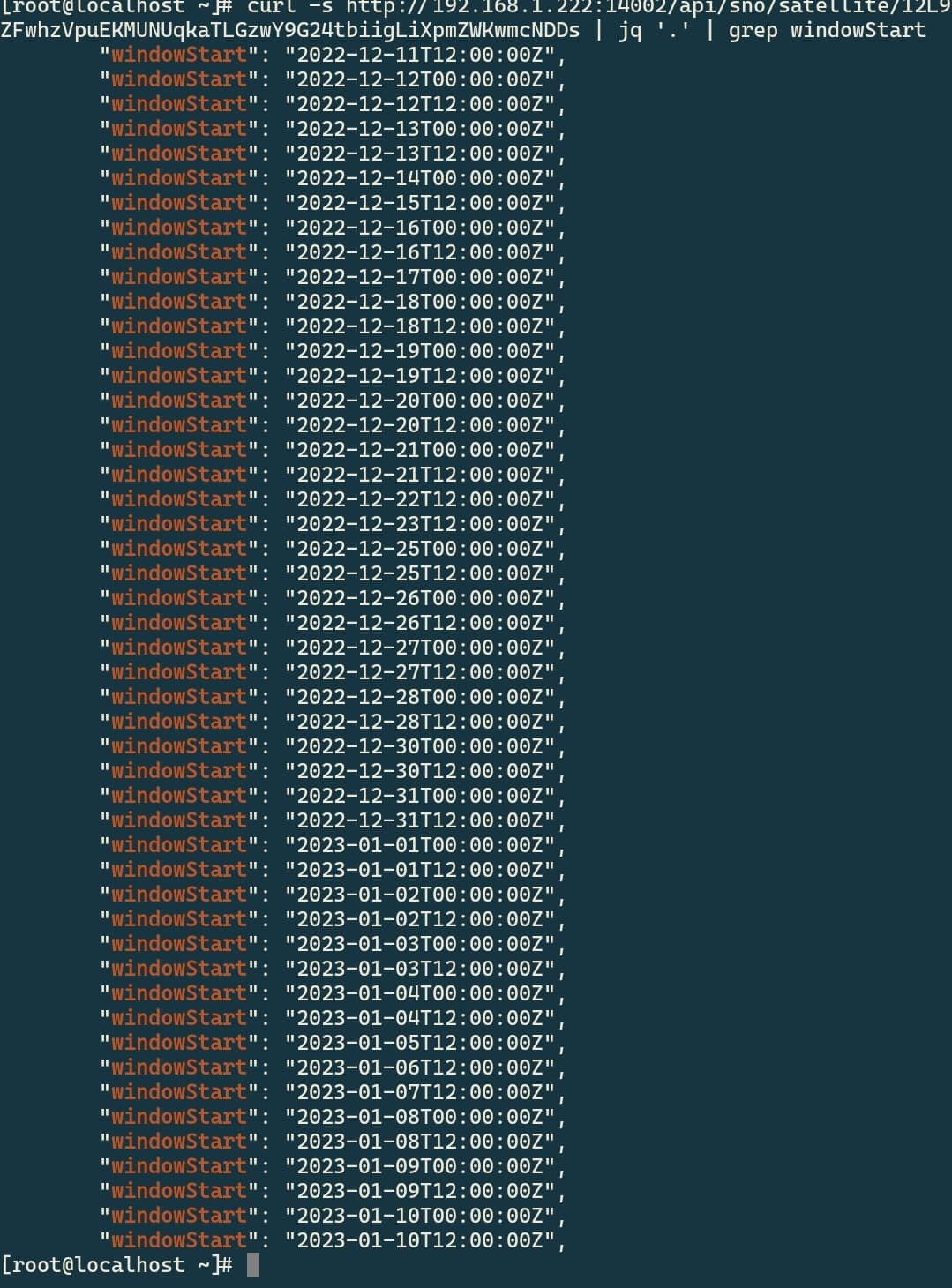
These are failed audit windows month ago:
[root@localhost ~]# ./storj_audit.sh | grep windowStart | grep -Po "(?<=\s\")\d{4}-\d{2}-\d{2}(?=T)" | sort | uniq -c
10 2022-12-13
4 2022-12-14
3 2022-12-15
5 2022-12-16
2 2022-12-17
1 2022-12-18
10 2022-12-19
9 2022-12-20
9 2022-12-21
7 2022-12-22
1 2023-01-08
[root@localhost ~]#
Dashboard:
Last 20 lines of log:
[root@localhost ~]# tail -20 /storj/node.log
2023-01-12T20:20:11.378Z INFO piecestore uploaded {"Process": "storagenode", "Piece ID": "JKSZDV523IN2H2J2FEGUCTKAJPPJDHCHKI3GYOQMIXCMC5IU4ZDA", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Action": "PUT", "Size": 13824}
2023-01-12T20:20:11.978Z INFO piecestore upload started {"Process": "storagenode", "Piece ID": "5JLQC5WW7JFAWKMSRW5TDHHEVKROY5UFTHZRHTVROK4UFSFG6RMQ", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Action": "PUT", "Available Space": 2326740932240}
2023-01-12T20:20:12.118Z INFO piecestore downloaded {"Process": "storagenode", "Piece ID": "XI4CBCSVQWZDXBPWZZXC6GJQC2TWXD3NMNTEPYMSI4CG35SOTMXA", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Action": "GET"}
2023-01-12T20:20:12.162Z INFO piecestore uploaded {"Process": "storagenode", "Piece ID": "5JLQC5WW7JFAWKMSRW5TDHHEVKROY5UFTHZRHTVROK4UFSFG6RMQ", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Action": "PUT", "Size": 2048}
2023-01-12T20:20:12.895Z INFO piecestore upload started {"Process": "storagenode", "Piece ID": "6FWTGIIBQXSO4VON27SCMWDX46FAOAHL6ORMJMJ6NMNYO4IDRWDA", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Action": "PUT", "Available Space": 2326740929680}
2023-01-12T20:20:12.987Z INFO piecestore uploaded {"Process": "storagenode", "Piece ID": "6FWTGIIBQXSO4VON27SCMWDX46FAOAHL6ORMJMJ6NMNYO4IDRWDA", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Action": "PUT", "Size": 2304}
2023-01-12T20:20:15.739Z INFO piecestore upload started {"Process": "storagenode", "Piece ID": "RUQPVABHYKYTRZC3DT37RDQ4RUTH6YHIJBHAVNQQP24ZCJRTKTSQ", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Action": "PUT", "Available Space": 2326740926864}
2023-01-12T20:20:17.324Z INFO piecestore download started {"Process": "storagenode", "Piece ID": "5JLQC5WW7JFAWKMSRW5TDHHEVKROY5UFTHZRHTVROK4UFSFG6RMQ", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Action": "GET"}
2023-01-12T20:20:17.339Z INFO piecestore download started {"Process": "storagenode", "Piece ID": "5JLQC5WW7JFAWKMSRW5TDHHEVKROY5UFTHZRHTVROK4UFSFG6RMQ", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Action": "GET"}
2023-01-12T20:20:17.368Z INFO piecestore download started {"Process": "storagenode", "Piece ID": "5JLQC5WW7JFAWKMSRW5TDHHEVKROY5UFTHZRHTVROK4UFSFG6RMQ", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Action": "GET"}
2023-01-12T20:20:17.426Z INFO piecestore download started {"Process": "storagenode", "Piece ID": "5JLQC5WW7JFAWKMSRW5TDHHEVKROY5UFTHZRHTVROK4UFSFG6RMQ", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Action": "GET"}
2023-01-12T20:20:17.474Z INFO piecestore upload started {"Process": "storagenode", "Piece ID": "BHPE4CZU25GUN3OTDSHP5CNZ45I6XTUTRL25LQM3XKULTZICHWRQ", "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "Action": "PUT", "Available Space": 2326740926864}
2023-01-12T20:20:17.498Z INFO piecestore downloaded {"Process": "storagenode", "Piece ID": "5JLQC5WW7JFAWKMSRW5TDHHEVKROY5UFTHZRHTVROK4UFSFG6RMQ", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Action": "GET"}
2023-01-12T20:20:17.522Z INFO piecestore downloaded {"Process": "storagenode", "Piece ID": "5JLQC5WW7JFAWKMSRW5TDHHEVKROY5UFTHZRHTVROK4UFSFG6RMQ", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Action": "GET"}
2023-01-12T20:20:17.558Z INFO piecestore downloaded {"Process": "storagenode", "Piece ID": "5JLQC5WW7JFAWKMSRW5TDHHEVKROY5UFTHZRHTVROK4UFSFG6RMQ", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Action": "GET"}
2023-01-12T20:20:17.595Z INFO piecestore downloaded {"Process": "storagenode", "Piece ID": "5JLQC5WW7JFAWKMSRW5TDHHEVKROY5UFTHZRHTVROK4UFSFG6RMQ", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Action": "GET"}
2023-01-12T20:20:17.696Z INFO piecestore uploaded {"Process": "storagenode", "Piece ID": "BHPE4CZU25GUN3OTDSHP5CNZ45I6XTUTRL25LQM3XKULTZICHWRQ", "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "Action": "PUT", "Size": 108288}
2023-01-12T20:20:18.385Z INFO piecestore upload started {"Process": "storagenode", "Piece ID": "BSOCAIHZSRR7JE7YZUDZN7A4R2JOTE2NMWYXBR434XRF2PLBQWNA", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Action": "PUT", "Available Space": 2326740818064}
2023-01-12T20:20:19.142Z INFO piecestore uploaded {"Process": "storagenode", "Piece ID": "BSOCAIHZSRR7JE7YZUDZN7A4R2JOTE2NMWYXBR434XRF2PLBQWNA", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Action": "PUT", "Size": 2319360}
2023-01-12T20:20:24.685Z INFO piecestore upload started {"Process": "storagenode", "Piece ID": "E2NID6NJZAWWKFNLY2ZVHORCREDQ4BYKWESVXZUVCC5OZC6TQXNA", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Action": "PUT", "Available Space": 2326738498192}
[root@localhost ~]#