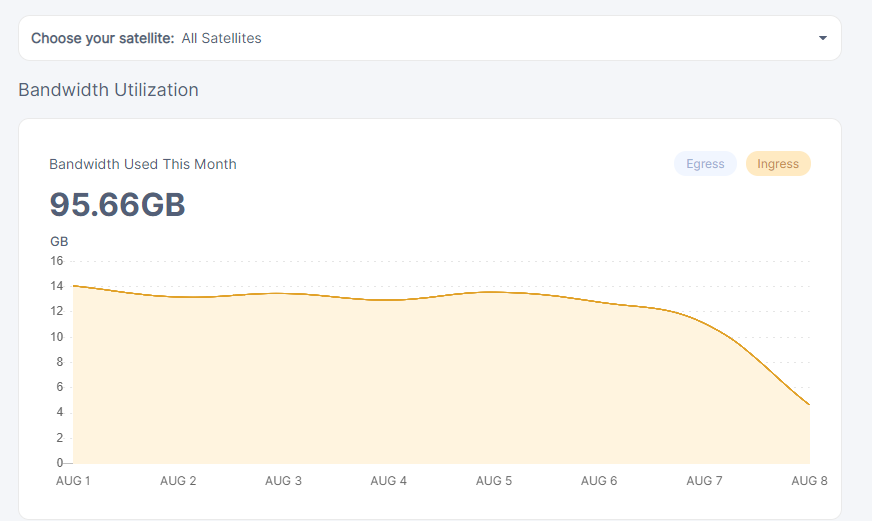
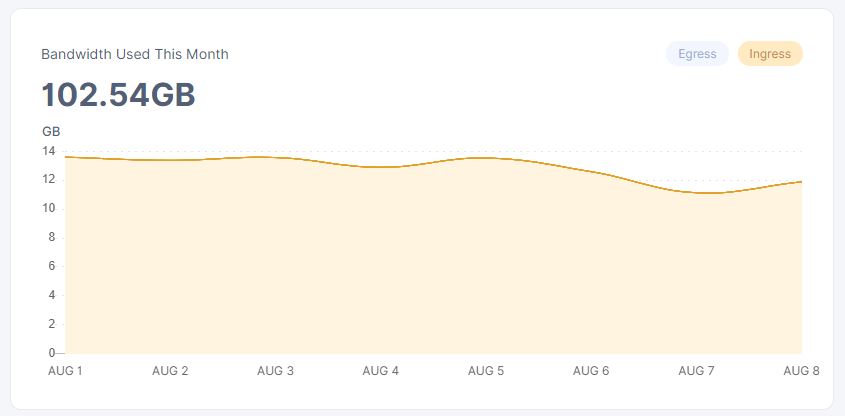
about the same here. 200 something on most
lol 15TB! I can only dream of such a figure. I’m having enough trouble trying to keep the oldest node at 1.1TB! The deletes on that node pretty much wiped out 80% of gains this month.
yeah growth have been slow lately… with my downtime and what not… my node is having negative growth…
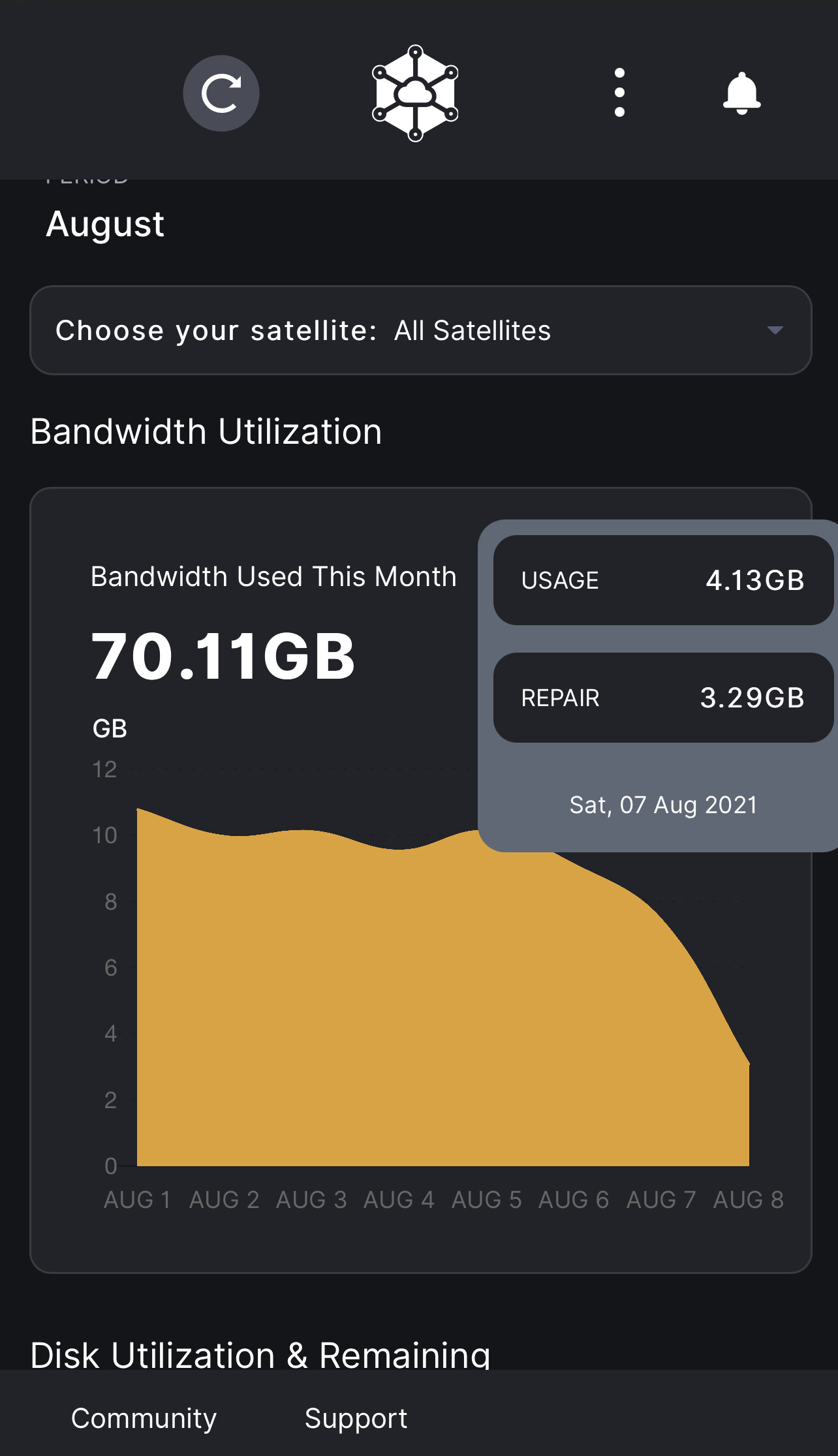
at 15.1 with 250gb in trash…
so could slip below 15TB i forget if trash is still counted i bet it still is tho… so between like 1-2weeks i should go below 15TB
but i think this is beginning to become a pattern… there are many deletes around the ½ year mark… most likely due to backups… and ofc the big backups often will correlate with stuff like holidays.
so summer and xmas basically.
i was a bit surprised the other day when i saw that there are actually 40000 nodes in the network these days…
thats a lot of nodes, basically 4x since 6 or so months ago, so that we still see decent ingress is a good signs… must mean that adoption of storj DCS is picking up
or ofc that storjlabs are pumping out tons of test data… also eventually many of these new nodes will fail or give up, i’m not sure how sustainable 40k nodes are…
but maybe i guess… just seems like a lot, when it to me seems like we just passed 10k…
also no wonder that we aren’t seeing any ingress with those numbers.
simply to many people, fighting over data.
That is very surprising. Storjnet.info still lists under 12000.
Unfortunately, I don’t think adoption is as great as you might think. I’m particularly basing that on the recent feedback from the S3 customer as to how difficult he found the whole process. Now, @Alexey handled that really well - but what about the customers that just gave up and just went elsewhere? Backups are certainly concerning in the long run - a whole lot of storage but not much egress until it all goes pear shaped. And we don’t know how storj will handle things in the event of a widespread ransomware attack. Particularly those SNO’s running on Windows. Microsoft has been doing a really bad job the last couple of months with multiple vulnerabilities taking ages to patch. Printnightmare still isn’t fully mitigated. We have had to turn the print spooler service off for some clients that were highly exposed.
maybe i was reading the graphs wrong … or looking at something else… yeah 12k was what it was at last i heard…
but if you check the satellites it says 40k nodes… maybe it counts all nodes that have ever been or something weird… i duno… does seem to say 12k and 3k vetting higher up the page
https://storjstats.info/d/storj/storj-network-statistics?orgId=1
storj DCS is a backend network… it’s not suppose to really be exposed to consumer directly… its suppose to be used by developers as their backend…
so really it’s not built to be customer friendly… but if that is what the market wants then maybe that will happen… but making a successful product rather than selling a service are two very different things and one might be a lot more easily managed than the other…
storj deals with storage, not all the other stuff… that is for somebody to grab the torch and take the opportunity to develop a platform that uses Storj DCS to its full potential.
i think it’s a smart move by storj to start like that… often 1000 products might fail before you find a perfect marketable product, storage is pretty basic…and universally required.
its a bit like leasing rack space in a data center… not really the smooth vps solution most consumers want… but still it is what is required beyond a certain level.
maybe they will become a supplier of that… but will take time… has taken years to build this system as is… and it still needs a lot of work.
This is true but those SNO’s on windows are still vulnerable to Microsoft screwing things up. I’m not suggesting the storj network is the problem but the stability of the SNO base if it is on Windows. MS has been getting worse and worse lately. Even the stability of O365 has not been great.
i don’t think we should expect to see storj go for the consumer market…
but i’m sure we will eventually see hundreds if not thousands using Storj DCS as a backend, and some of those projects will be the dropbox type projects…
sure maybe StorjLabs could get lucky and make such a successful project… but look at google… making and killing projects right and left… even with their resouces its difficult to figure out what people want, how to provide and market it… if it even works
but a search engine… everyone needs a search engine
one day storj might do much more… but i think it’s wise to hedge their bets on what they know works, while working with limited resources and personnel.
and the Storj DCS network give opportunity for those that want to develop something innovative to do just that, taking advantage of storjslabs good project, research and advances.
so really everybody wins.
Yes correct, as far as i understand those are all nodes which are connected an satellite ever. If you substract exited nodes an disqualified nodes, then you should get the amount of active nodes, which is around the 12k
total_nodes - total number of unique storage nodes that ever contacted the satellite
A friend of mine worked for Google. We both loved NetBSD and MIPS machines when we got together. He was based in Zurich for a few years. So I have heard all the war stories. lol. He invited me to apply at one point but he scared me off to be honest - and by the end of his time there he hated the place too.
that is horrifying… so 2/3 nodes in what like 18 months maybe two years have failed…
makes my choice of going with redundancy feel a bit more sensible lol
I wonder what’s the ratio of Windows to other OS nodes, or storage (two different metrics). I somehow feel that it should still be strongly skewed towards the other types.
I wonder how good is nmap nowadays at detecting OS…
This will include lots of nodes that never were online in the first place. Because people couldn’t figure out the port forwarding etc. The majority most likely dropped out during vetting, which is exactly what vetting is for. And even for the rest there is no reason to think hardware failure is any significant part of it. Mostly just people who decided to stop for whatever reason. Maybe they needed the space back or maybe they didn’t like the compensation.
Either way, there will always be plenty node churn in the newer and younger nodes. But I think by now there is also a very reliable solid base amount of nodes that stick around.
thats a good point, crib death… i like your way of thinking lol
was a bit surprised by the number but didn’t really think much about it…
Hmmm… now I imagine a backblaze-like dataset, except instead of drives’ daily SMART data, it would contain some summaries of node health checks for each day…