Adding these together gives about the same ingress as SGC mentioned. On the other hand, I see constantly 20-30 even 40GB in the trash. Considering the 7 days retention period, the stored data amount is more or less stable or very slowly increasing. I don’t have nice graphs about it, but used to make notes about the values. Since 1st January I have only 90 + 130GB used space increase (on the two nodes). Back in October-November it was around 200GB / month / node.
It seems the number of nodes are increasing faster than the newly stored data, so each node gets less and less new data.
i think i see a deletion rate of about 1/3 of ingress, but haven’t really kept good track of it…
not sure if i have log data to calculate it…
but i might have… going to try…
can calculate it for this month… and its bad… really bad… but i have some crashes, so might have gotten punished with some extra deletes.
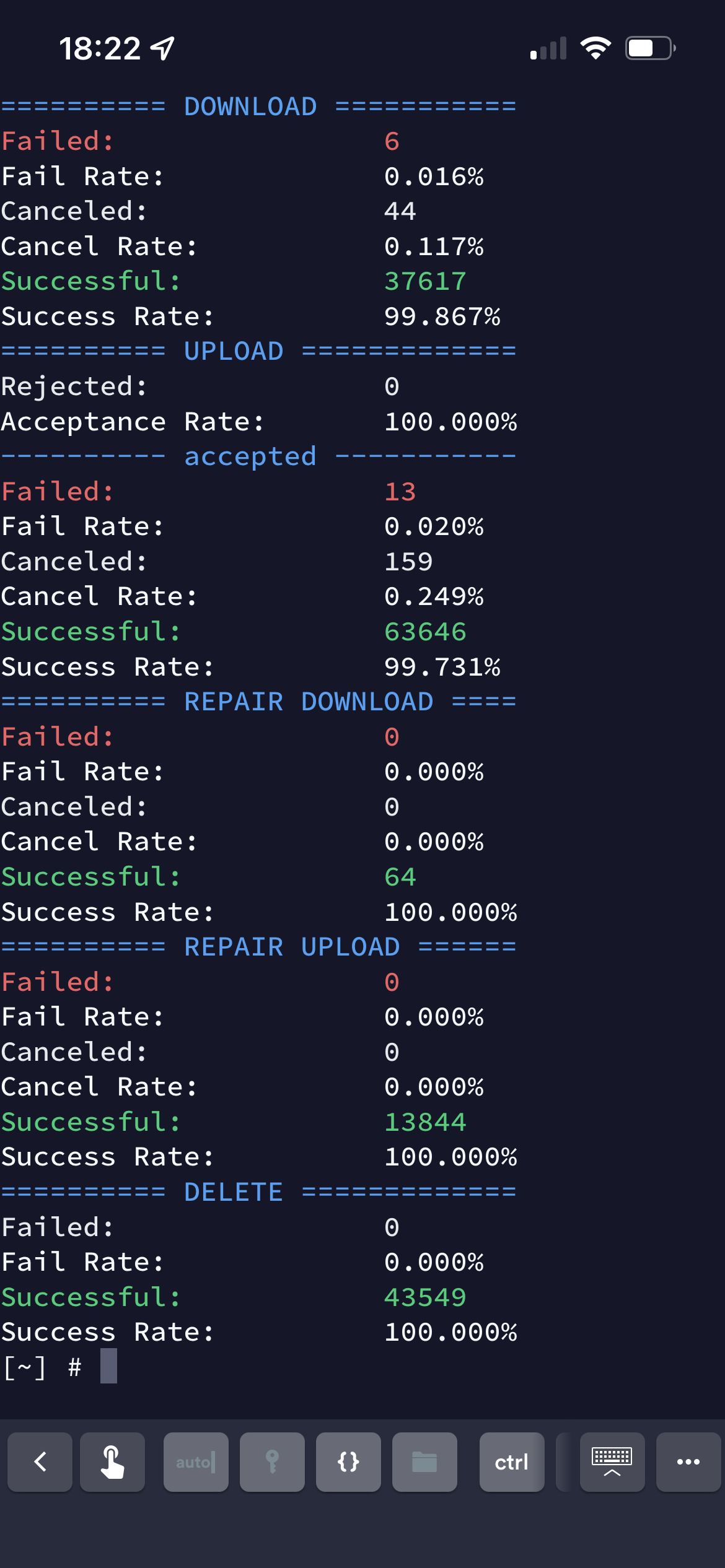
55% of my ingress this month was deleted…
ofc size of the nodes also play a major effect…
i got a running log of how much space is used, so i took that number and compared it to my ingress according to my multinode dashboard…
i would be very interested in hearing what kind of delete ratio other people are seeing…
i will figure out a better way to log this… because that is so so high…
it almost can’t be right
it behaves as if one node, except vetting is ofc double and thus takes twice as long.
there are some good reasons to have multiple nodes on one ip, like easy storage expansion, reducing storage iops and latency,
and if one node dies or is damaged it doesn’t affect all storj data
aside from that, because of the extra vetting process it is time consuming and inefficient.
and more points of failure… like all things each choice has pros and cons
So it feels like one node for ingress, but i guess egress performance is hard to tell. Looking to add another node, but I still have 8TB free on first node…
egress is often similar across nodes of the same age, but there is a bit of a lottery component to it also.
one month or one day a node can get 3x or higher of egress compared to others that are from the same period and have been running under the same conditions.
the sad trend tho seems to be that the older data gets on a node the less egress it will see compared to how many TB is stored.
ofc this is over years… and since we don’t have much information to go on long term… the trend might be better as these years long stored data blocks without much egress, might one day require a full download, instead of the usual few % downloads that avg data sees.
so if we say the avg download / egress % pr TB is like 5%… i forget if thats right, but its easy to work with, and what i remember it to be approx.
then if a data block is downloaded 100% at one point, the wait period to reaching that compared to the other avg used data blocks, would be 20 months where it could be inactive and then get 100% egress for the data block and thus be equal in earnings to the other more avg blocks/customers.
and if it can take 20months just to get a download then trend from what are we up to now 2 years of enterprise service offered, we might barely be starting to see data uploaded to the network on day 1 get redownloaded and could still with a 100% download of the data / backup actually equal the more active data.
long story short… even if the trend looks kinda bad for older nodes, it might still turn around.
and do keep in mind i’m using rough numbers here.
new nodes seems to earn like 5$ pr TB stored while older nodes in the 2½ -3 year old range earn like 2$ pr TB stored… so thats quite the gap.
but like i said long term data storage profitability might still recover if all the data is downloaded
yes it might have to do with that data older than 2 years or so is test data… i duno…
but you are exactly right nodes that are even just a little bit younger doesn’t seem to have the same poor profitability pr TB.
it’s one of the main reasons, i’m considering decommissioning my 16TB node when i run out of space next time.
45,79$ / 16,67TBm = 2.74$ pr TB stored… and i’ve seen older nodes be in the 2$ range.
this 16.7TB node is from 2020-03-07 so just about 24 months.
i started just early enough that i got the last bunch of test data from storjlabs prelaunch stresstests.
still if we compare to yours then i’m loosing 1.5$ pr TB, so the same capacity would be able to earn 25$ more when refilled…
but still not sure if thats what i’m going to do, kinda depends on when i run out of capaity.
it would also be nice to keep the node for future reference.
to see if the profitability recovers.
From a personal profit point of view, I can understand that decomming node 1 would allow for greater future profits. But at the current rate, it will take 3-4 years to get back to where you are now profit wise and another few years till you break even on losses from doing nothing…
a good rule of thumb is that all nodes, without having some sort of performance decrease, will get the same ingress (after being vetted)
ingress from one month or another can vary greatly and so can the later data deletion ratios.
if you want to evaluate your node performance you should compare daily or monthly ingress.
or whatever time period you prefer, ofc this is only really possible for vetted nodes, as nodes with unvetted sats will or can get very different results.
nodes are best compared if they have about the same age, then if a node has been performing without handicaps, it will usually be near the exact same data stored.
i will recommend the ingress method.
something like this works very well.
my ingress might be slightly lower that a perfect performing node would see… because i have had a bit of issues with my storagenode host.
and yeah use days that have already ended for examples, because current day is ofc a variable measure, and thus basically useless as it depends upon when one posts it.
the daily ingress comparison we have tested in the past and the deviation was down to like 1%, between optimal performing nodes, so its highly accurate and very easy to do.
if one wants a good idea if a node is performing correctly.