As per the title, for the longest time I was running (Win 10) 3 nodes on 3 drives (one of which was the OS). All the nodes .exe’s are on the OS drive with folder as below
I have now purchased an SSD and cloned my HDD and booted. Everything seems to be running fine…
My question is, is the DB for each NODE currently in the data folder? And if so is that the best, or should I move their DB’s to the SSD (and why?)? If yes, is there a link or guide to doing that?
Second question, what should I look for in the logs do indicate anything going awry with my nodes? I’m planning on wiping my previous HDD and using it to move the node currently on the OS onto it, but don’t want to wipe my HDD until I’m certain everything got moved okay.
Moving DB’s is a process you can easily mess up. Unless you have large amounts of trash regularly or bad success rates, it’s not worth it. Especially because you will also introduce a new failure service to your nodes. If your SSD fails all nodes will initially fail and while you can fix that, you will have lost all historic stats. So yeah, only do this if you’re having issues with your nodes.
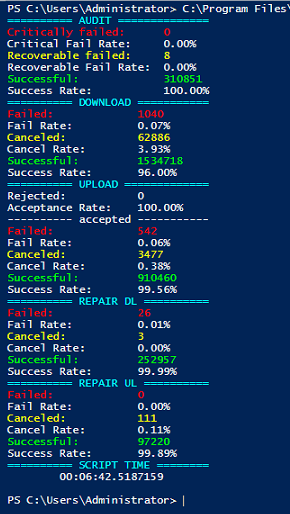
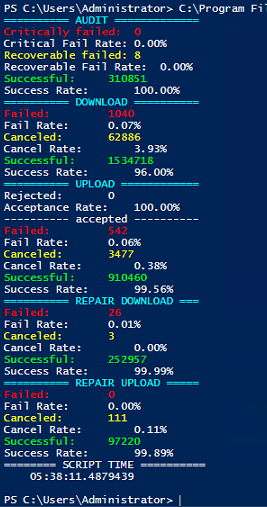
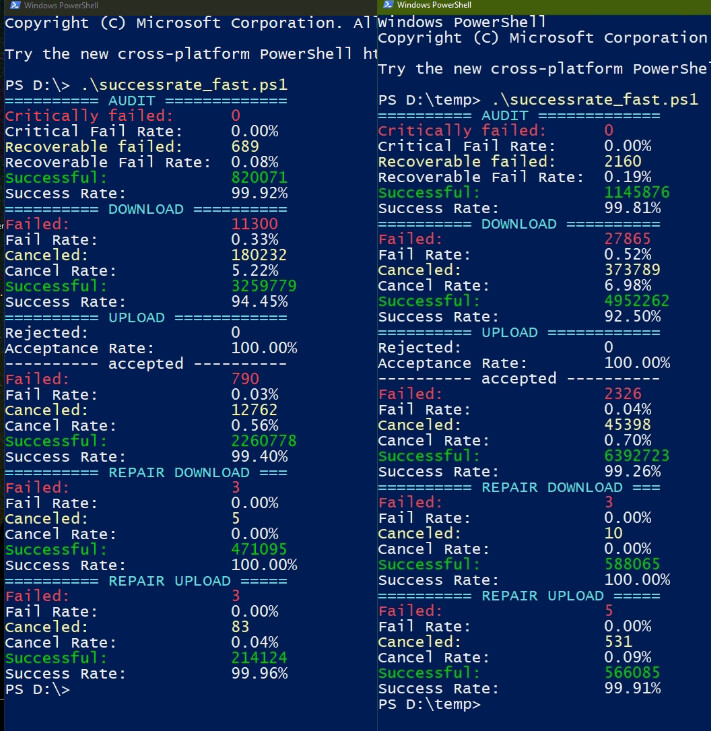
I’m trying to run Success rate script - Now updated for new delete terminology since v1.29.3 tool to get the success rates but it’s just not completing. It’s consuming all my ram (I have 32gb) and just churning. My log files are 3.5 and 7gb respectively. I can’t even complete the 3.5gb one. Is there another tool or anything I can do to speed it up?
You need to stop your node and rename the log file (or archive it and remove the source) and start the node back, wait for several hours to have stats and run this script.
Thanks, I’ll give it a shot after…maybe. Problem is, running the original script on a 32gb, i7 (doesn’t matter much since it seems to be single-threaded) is taking well over 12 hours now. I started it at ~11pm, at 7:30am it was still going. I have taken the machine to work and it’s running in the background. Now it is 1:16pm and still going strong lol.
It is currently on repair downloads. At this rate, it would take it days to process my 7gb file.
I have copied the files over so they are not being touched by the nodes.
Looks like download success rates are a little low. You may see some, but limited improvements from moving db’s to SSD. Just be sure to follow the steps carefully and don’t mess it up. It’s not worth losing your nodes over. We’re talking probably at best a 2-5% improvement. But there may even be no noticeable difference.
Should I be worried about the stress or the extra reads/writes to the ssd significantly wearing it out? I am using a samsung 870 1tb.
And the steps are, shut down node. Copy over files (what files exactly) to desired location on ssd. Change the config file to point there, restart node?
For just the db files I wouldn’t worry about that. It’d be different if you cached the entire node, which I don’t recommend (I do this myself for some of my nodes, but it’s a do as I say, not as I do situation).