I try to use the official AWS S3 SDK in C# to interact with storj.
I can access Storj from it, and list the bucket but:
A. when I try to list the objects in the bucket I get the bucket empty
B. when I try to access a file in the bucket I get an error of the file does not exists
C. when I upload a new file through the SDK, the upload succeeds, and I can see it when I list the objects, but, I can’t see it in the Storj portal.
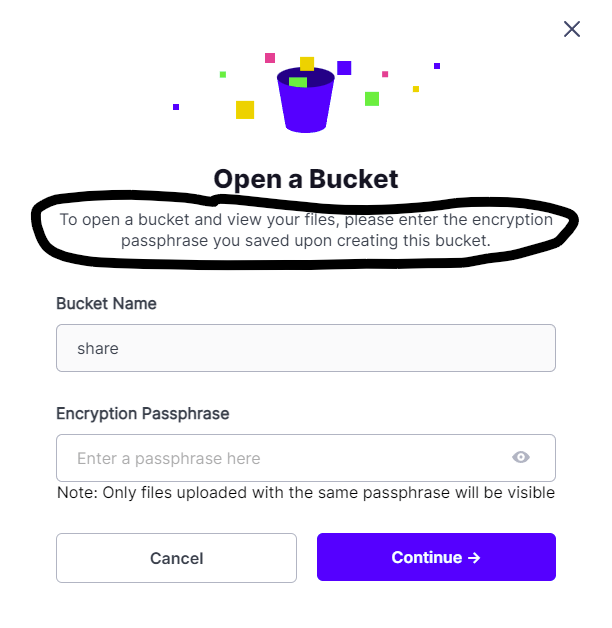
Looks like you are using a different Passphrase for the AWS SDK then you use in storj portal. If it is not the same it can’t be decrypted and therefore is not visible.
If that’s the solution (again) then I have to say, that we see this issue quite frequently.
Maybe this indicates that there is lack of documentation or intuitive understanding of how this works.
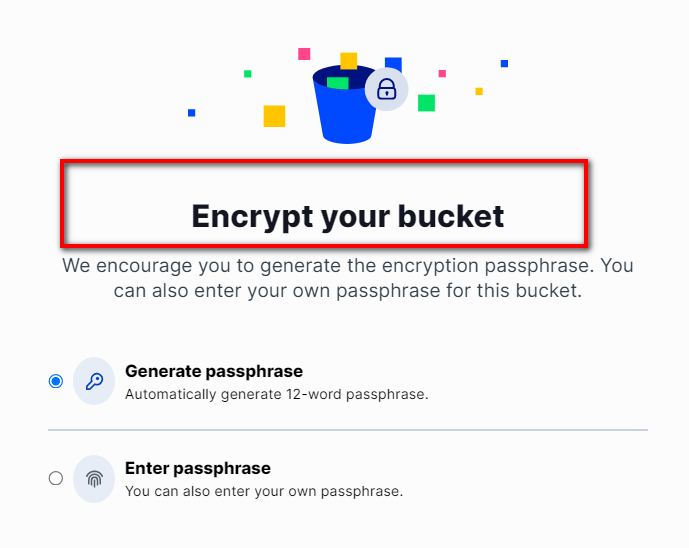
It would be step 3: Enter the encryption passphrase. There you can also set your own. If you enter the one that you use with the storj portal there, you should be able to see what you uploaded.
I agree, this is coming up a lot and isn’t exactly an intuitive result. Perhaps just adding a note to the satellite object browser that says “Note: Objects uploaded with a different passphrase will not be shown” would already help. Maybe also note this when creating a new access grant. Better documentation would be great too, but we know people don’t read documentation much. It’s better to have clarity within the user experience itself.
Similar notes could be included in uplink cli responses.
It’s not a catch all as it can’t be included when accessing Storj through other means, but I think reinforcing this in the native experience is probably enough for people to figure this out when they run into it elsewhere.
Edit: Having some limited experience with user interface design, I would bet if you did some research with eye tracking software, almost nobodies eyes would land on this phrase. It’s just in a spot that’s easily skipped.
It also seems to suggest you can only access the bucket if you enter the same passphrase or that only one passphrase can be connected to a bucket, neither of which is true. And while it tells the end user what to do, it doesn’t tell them why and doesn’t build additional understanding of how it actually works. Might as well omit that sentence entirely.
Why not also add it as additional note inside of the Download.txt file? This is probably the first place where user check, if their password is correct.
Another thing is, that I just saw that a password download option is available when creating an Access Grant but not when creating a bucket with own password. Does this make sense to me?
Lol @jammerdan you know I love intuitive clean designs
Thank you, this is great feedback.
I will pass this thread on to the teams who can asses this and make any necessary changes.
Maybe a sentence like “If you enter a wrong password the bucket will show as empty” would explain it better, but would not be entirely correct also. But surely the wording could be improved.
The thing is that you can input anything to enter the bucket after creation.
So maybe the entire workflow is misleading if you start with requiring a password for bucket creation in the first place. Because:
Once the bucket has been created and I use the wrong password, I can still upload to this bucket and the files get encrypted with the password that I have just used.
Yeah, it seems the workflow is built around a suggested usage pattern rather than actual functionality. Here again it suggests that the passphrase is a property of the bucket in the entire UX design. But if you want you could use a different passphrase for every uploaded file. Instead the passphrase is more a property of the connection and of the files. You can see the files that match the passphrase used for the connection. If that is the case, then why is the entire interface built around a different assumption? Why do you even need to enter the passphrase when creating a bucket? A much better flow would be to just return to the bucket overview after creation and ask for the passphrase only when opening the bucket. This would make it very clear that the passphrase you set is only the one for that specific connection to the bucket. That combined with the suggested notes would make it obvious how the entire system works.
The current setup really feels like it isn’t built for how the actual system works. I think the intention was to make it more user friendly by suggesting a more intuitive way of working. But it’s backfiring, because it teaches the user to expect it to work different than it actually does.
The behavior is also different from standard encryption tools like Bitlocker.
Maybe that’s also a reason why users would expect a different behavior when they are told they are encrypting buckets.
However hiding files is not uncommon. Network shares can be set up in a way that users will only be able to see files and folders they have actually access too. All other objects would simply not display for them. This sounds very similar to how Storj has implemented their encryption/access behavior.
Well it is unfortunately more complicated than that. Because the encryption key isn’t what determines what kind of access you have, that’s in the other metadata of an access grant. If you have access to the bucket and prefix, but don’t have the passphrase anymore, you can still use the uplink CLI to see the encrypted files by their encrypted IDs. So the better comparison with network shares would be that access rights determine what shares you have access to, but the files stored on the share are encrypted with a separate key. In that case you would actually expect the files to be visible, but just a meaningless blob unless you have the decryption key. Storj works the exact same way, but because it also encrypts file names, it can’t display encrypted files like normal files. So hiding the files you don’t have the encryption keys for is the deviation from expected behavior on network shares.
I guess they could show the encrypted filenames in the file browser in a greyed out font with a note that those files were uploaded using a different encryption passphrase. As long as your access grant has read rights to the prefix. But I think changing the default behavior in uplink CLI would definitely break things built on the existing version. It should be doable on the web interface though, I think.
I think there are some powerful unique features this set up allows, so I wouldn’t personally advocate for that changing. At the moment, it’s simple to build an end user application where only the end user has access to their encryption keys, which is of course an awesome feature. And there are other pros for developers. In my opinion it’s best to embrace the advanced feature set and adjust the interface to make these features more apparent. They could include ⓘ icons with more info and links to docs where needed in the interface to help people do a deeper dive into the details. In the end it’s storage aimed at developers, so I think they have the feature set right. The UX could just use some tweaking.
But I think we gave them plenty of suggestions and things to think about for now. I don’t want to drown them in a massive convo and risk tl;dr. Thanks @jammerdan for this conversation though! I think this was very constructive. Looking forward to response from Storj Labs regarding this!
Btw @StorjLabs, I’ve filled in questionnaires that included the question if I would be ok with joining a call regarding these subjects a few times. I’d be happy to hop on a call and share some feedback and ideas if that’s helpful. I’m not the most extensive user of Storj DCS myself to be honest, just personal backups atm, but if you think it’s useful anyway based on this thread let me know.