You can now respond quickly even when your network turns off briefly and then comes back on.
There are many reasons why the Windows network connection is lost, and this is only one solution, so it would be good to find several ways. (I used this method because even with the power saving settings(disabled),the device disconnects once a week.)
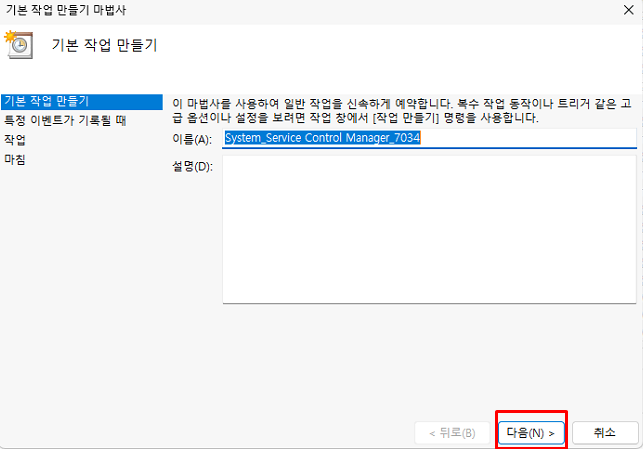
The contents are explained for beginners. Experts may have a better way.
Even beginners like me can make it easily, so if you want, follow along.
If there is a better way, please let me know. Thank you.
(I apologize in advance for the fact that the language is not English, so the icon descriptions are in a different language and that I am not good at English.)
This happened to me, but it was the network/mainboard drivers fault wich was not updated automaticaly.(while windows did updates and became incompatible to the old driver once a month)
but why does node service not start itself after a reboot? normaly its on autorun anyway.
and it can be set in the services tab to start again after a failure.
Maybe there are 1min timeout errors in the storagenode.log?
sometimes the network is not ready after reboot immediately, so you need to make some changes, if this is the case for your system:
I would suggest to check the storagenode’s logs for FATAL errors, they could be a reason for the stopped service but not the network.
You may also configure restart of the service in its settings in the Services applet (or with sc.exe program), but fixing the FATAL errors would be better.
I modified the meaning that I disabled it. And it’s easy to restart with the method you told me. Thank you It’s a great help for beginners.
I don’t know much about computers, so I often feel barriers to entry, but it’s a great comfort for me because there are a lot of people who kindly teach me on forums, Thank you always.
You are welcome!
But your method could be useful to restart on exact issues, i.e. hardware ones, but I likely would configure to stop the service in this case: being offline is better than disqualified.
this is a usual problem for Windows and disks without a defragmentation.
You need to:
Stop the storagenode service
Defragment the drive
Do not disable (or enable, if you disabled it) the automatic defragmentation for this drive
If that wouldn’t help - you need to increase a writeability timeout on 30s (by default it’s 1m0s), save the config and restart the node - either from the Services applet or from the elevated PowerShell:
I increased it by 30 seconds as you wrote, and I went in and saw the article you linked to.
Now I know that deactivation of sculpture collection can also cause problems…!
I feel like I’m getting more and more knowledge…
If you have readable timeout errors, you need to increase both - the readable check interval and readable check timeout. The first one is a frequency, the second one is the timeout itself. Increasing only the interval doesn’t make sense.
However, since the error mention only writeability check,
then you do not need to modify a readability interval and/or readability timeout.
And as @daki82 said, you need to remove a commentary character (# ) with space before the writeability check timeout, i.e.
# how long to wait for a storage directory writability verification to complete
storage2.monitor.verify-dir-writable-timeout: 1m30s
You doesn’t have a readable timeout errors accordingly to this logs excerpt:
you have only writeable check errors so far.
So, modify the config like this:
# how frequently to verify the location and readability of the storage directory
# storage2.monitor.verify-dir-readable-interval: 1m0s
# how long to wait for a storage directory readability verification to complete
# storage2.monitor.verify-dir-readable-timeout: 1m0s
# how frequently to verify writability of storage directory
# storage2.monitor.verify-dir-writable-interval: 5m0s
# how long to wait for a storage directory writability verification to complete
storage2.monitor.verify-dir-writable-timeout: 1m30s