For one or another reason my youngest node (i have 3) got disqualified on one satellite a couple of weeks ago (10. august). It is strange what happened because the machine ( Ubuntu 16.0.4) was up and running well… Not offline, and not showning any other signs of problem. I have monitoring on all my tree nodes (Uptime robot) and also earlyer got warnings when my nodes for some reasons got a suspension.
This time i got no warnings at all before i got an email telling me that my node was disqualified. I checked and as i mentioned all looked OK, but I rebooted the machine. This prevented me for beeing disqualified on all sattelites.
What I want to know is if it, in the long run, will be better to take down this node and start a new one? The node has been up for four mounts and holds 4TB of data.
Did this node get suspension message? If you did then are you sure you fixed it. When you don’t fix the issue behind suspension then the node is disqualified.
No, as mentioned got no warnings or alerts. It was the dsq. message that led to my actions. All seemd fine and my two other nodes was OK. But my dashboard on this node showed a suspension score far below 60% for all satellites. Hence I restarted the node and avoided dsq. on the other satellites.
As I understand there is no “appeal court”, so this is something I have to live with :-/
I’ve been playing with Storj since 2017, and my oldest V3 node (from april 2019) now gives me a nice payback ![]()
Yesterday i moved (with rsync) this node from a 4TB disk to a 8TB disk. The question is really if I should exit the node with disqualification, and start a new 8TB node (two 4TB disks), or just start another 4TB node?
Another annoying thing with this incident is that i daily have to look at this message:
" Your node has been disqualified on 1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE . If you have any questions regarding this please check our Node Operators thread on Storj forum." ![]()
There is no warning of “pre-disqualification” is implemented. If something went wrong the disqualification is happened in a few minutes-hours.
The suspension only applies to “unknown” errors. “File not found”, “Timeout x4”, “piece corrupted” are known errors thus affect audit score immediately.
You can still run this node, it just will not receive payout from the satellite disqualified your node.
But suspension warning could also lead to disqualification after some time if action not taken? Or am I wrong?
What you’re saying is that there might be cases where you will not get any warning before disqualification? Regardless of notificaton or Uptime monitoring?
This is true. You can get disqualified with no warning.
Yes, both true. The suspension can finish with disqualification after a while and there is a fast disqualification when data is lost.
If disk is corrupted it doesn’t matter, you can’t recover from that.
If disk is unmounted in the v1.11.1 your node will crash with error if it can’t write a check file to the data folder.
However, if you store the data in the root of the disk and disk is unmounted, the mountpoint will still be available for write, so storagenode will start from scratch and will store the data in the mountpoint (on your system drive) instead of disk. And will be disqualifed for lost data (which is still on unmounted disk).
To prevent this from happening you should place the storage inside the folder on the disk. In such case if disk unmounted, the subfolder will not exist and storagenode will crash.
There is one case still could be - mixed access rights. Some files have owner as root, some as user and docker container is working from user with name user. Sometimes it will fail audits, when it doesn’t have an access to files owned by root.
To prevent this is recommended to change the owner of the data to user, who run the container. If it’s root - then you should run the storagenode container with sudo, if it is not root, then you should replace the owner to the right user and add this user to the docker group and run the storagenode container as that user.
Hi guys,
sorry to bother on the " Sat, 05 Sep 2020 05:48:11 GMT" my node was disqualified on the 3 satellites. 
I checked the logs and see thous errors. Please see the attached picture.
To be honest when COVID start. I had one intervention when Linux partition was full.
I do not check the logs. Since that Seagate HDD case. No suspensions I was thinking all good.
Errors referring to the "ERROR piecestore download failed " are on the satellite I’m currently not disqualified. So I scare to get disqualified on them as well.


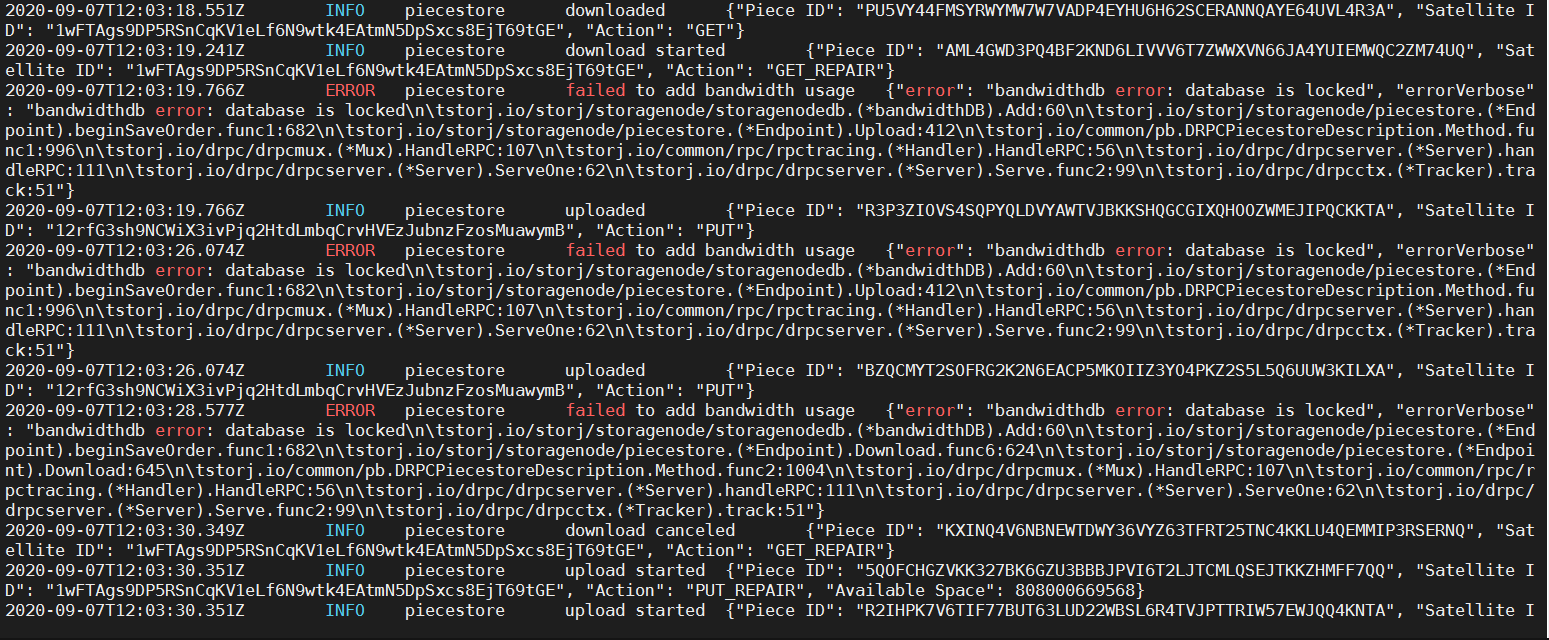

Is that serious, do I need to start from the beginning.

All those errors do not affect the audit rate.
Please, search for GET_AUDIT and failed in the same line. Your node can fail audits only if:
- the piece is unavailable (file not found);
- the piece is corrupted or hash is wrong;
- timeout 4 times in row for the same piece.
All other GET_AUDIT errors could only suspend your node.
Hi Alexey. I checked all of the logs and do not see GET_AUDIT and failed in the same line.
Can I send the logs on priv or any other option to check why I got disqualified?
Please, give me your NodeID, I’ll ask the team to look into logs of the satellites.
Hi Alexey,
Node ID:
1ajd4S5ZCrroaywMiBTnLFWcob6fKeREz4Hh2SYJho2jAqTt7v
Thank you.
Hi all,
Dont want to open a new thread since it is related. I just got a message that my node is disqualified on the stefan Satellite.
What does this mean now?
The node has about 4TB of data. Should I wipe it and set up a new node? Or just let it run and accept the fact that stefan disqualified me ![]()
Any way to find out why the node got disqualified? The email I got is not very informative…
Stefen is going to be shut down if that’s the only satellite you got dqed on I wouldn’t worry about it.
Hello @krilson,
Welcome to the forum!
Because of failed audits. Please, check your logs and search for GET_AUDIT and failed to see a reason. Also, the audit will be treated as failed if you have GET_AUDIT and download started, but not downloaded at the end. And of course, if audited piece is exist but corrupted, the audit will be treated as failed too. If audit score fall below 0.6 (60% on the dashboard), the node will be disqualified.
Hi @Alexey, thank you for the warm welcome.
I checked the logs, but I only see logs since the last restart. And I restarted the node after getting this disqualified notice.
Is there a log archive somewhere to be found?
I checked the logs using:
docker logs storagenode >& storjshare.log
And then searching this file. Did not find any “failed” entries.
Edit: I tried opening the web dashboard now for the first time (used the CLI dashboard only before).
I see these entries near the top:
Your node has been disqualified on 118UWpMCHzs6CvSgWd9BfFVjw5K9pZbJjkfZJexMtSkmKxvvAW 1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE 121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6 12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S 12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs .
For example, opening the stefan satelite shows:
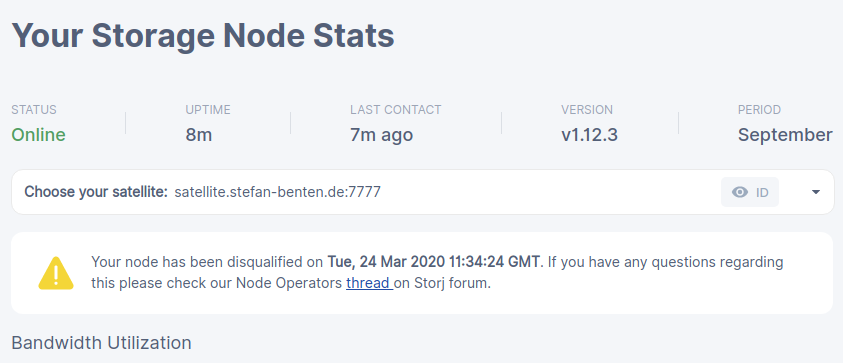
So it got disqualified on 24.March 2020. But I got this email notification on 15.September (yesterday). Is this normal? Such a delay in the notification…
Upon further inspection I see that I got disqualified from all but one satelite. All on the same date 24.March 2020.
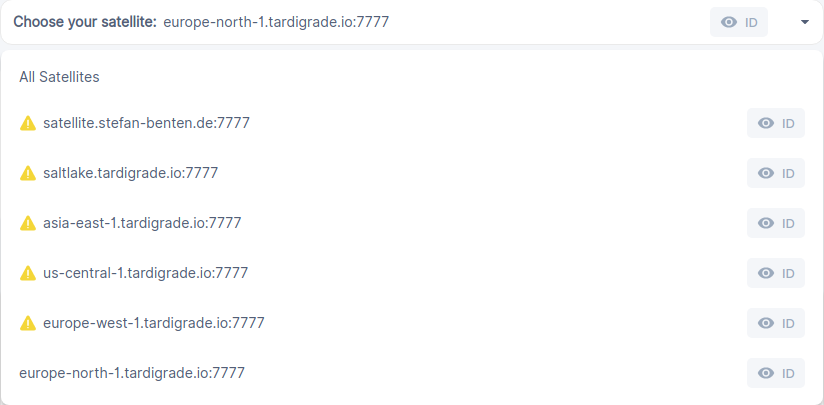
They all have the same audit score of 59.9%
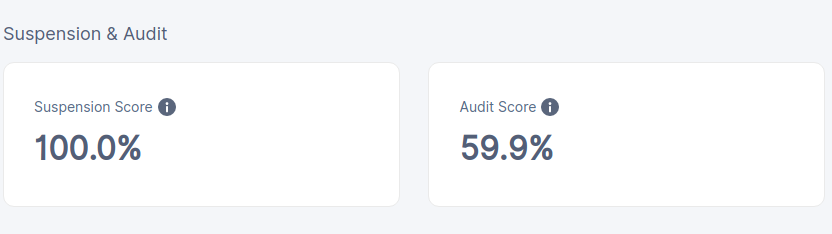
The one satelite that is ok is: europe-north-1.tardigrade.io:7777, it has both scores 100% 100%.
Is this all normal? I apologize for being a bit confused. I set and forget this node a while ago with watchtower updates, only monitoring the CLI dashboard. Seeing that it was storing data and using bandwidth I assumed that everything is ok with the node.
Looks like your got DQed on every satellite. This is probably because of a bad mount or you moved nodes to another hard drive, and didnt start with the right location of the data.
I did extend the partition. The node is running on a VM and I increased the disk size.
But all seemed well, same mount point and all the files are intact.
So should I wipe it and start as a new node now? Im a bit confused, since europe-north-1.tardigrade.io:7777 is ok.
What is the smart move here?
I would try and run a graceful exit on europe-north, assuming you have made the 6 month minimum and the amount held is worth it to you. Then start over with a new node. EU-North is probably fine because it didn’t exist until April of this year.
Could be a matter of time before it is too DQed possible has less data so it would take longer to DQ at this point.
I would just cut my losses and start over, EU north isnt worth saving a node for.