I’ve got two nodes, and saltlake is about to be disqualified on my second node (already on my first) because of audit. See my logs below. I’m confused as to why it can’t communicate with saltlake?
I have the error logs, but can’t post because I’m a new user limited to 2 links? Not sure what links are in the error log. I’ve tried to parse it a bit. The gist is that it says it can’t ping the satellite server and then gives what looks like errors in code. I can ping saltlake no problem from my server. How can I post my logs?
Ping stats:
user@host:~$ ping 78.94.240.189
PING 78.94.240.189 (78.94.240.189) 56(84) bytes of data.
64 bytes from 78.94.240.189: icmp_seq=1 ttl=43 time=220 ms
64 bytes from 78.94.240.189: icmp_seq=2 ttl=43 time=219 ms
64 bytes from 78.94.240.189: icmp_seq=3 ttl=43 time=213 ms
64 bytes from 78.94.240.189: icmp_seq=4 ttl=43 time=206 ms
64 bytes from 78.94.240.189: icmp_seq=5 ttl=43 time=221 ms
^C
— 78.94.240.189 ping statistics —
5 packets transmitted, 5 received, 0% packet loss, time 4005ms
rtt min/avg/max/mdev = 206.381/216.176/221.194/5.514 ms
Some of the log entries contain URLs or what looks to the forum software as URLs. You should be able to get around this if you post the logs and place three backticks with “text” above the block of logs (```text) and three backticks below the logs (```)
For example, this:
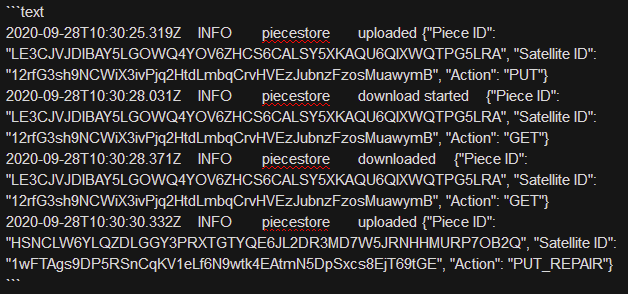
Produces this:
2020-09-28T10:30:25.319Z INFO piecestore uploaded {"Piece ID": "LE3CJVJDIBAY5LGOWQ4YOV6ZHCS6CALSY5XKAQU6QIXWQTPG5LRA", "Satellite ID": "12rfG3sh9NCWiX3ivPjq2HtdLmbqCrvHVEzJubnzFzosMuawymB", "Action": "PUT"}
2020-09-28T10:30:28.031Z INFO piecestore download started {"Piece ID": "LE3CJVJDIBAY5LGOWQ4YOV6ZHCS6CALSY5XKAQU6QIXWQTPG5LRA", "Satellite ID": "12rfG3sh9NCWiX3ivPjq2HtdLmbqCrvHVEzJubnzFzosMuawymB", "Action": "GET"}
2020-09-28T10:30:28.371Z INFO piecestore downloaded {"Piece ID": "LE3CJVJDIBAY5LGOWQ4YOV6ZHCS6CALSY5XKAQU6QIXWQTPG5LRA", "Satellite ID": "12rfG3sh9NCWiX3ivPjq2HtdLmbqCrvHVEzJubnzFzosMuawymB", "Action": "GET"}
2020-09-28T10:30:30.332Z INFO piecestore uploaded {"Piece ID": "HSNCLW6YLQZDLGGY3PRXTGTYQE6JL2DR3MD7W5JRNHHMURP7OB2Q", "Satellite ID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE", "Action": "PUT_REPAIR"}
Hi @UofM_Matt did you manage to find out the cause? I got disqualified on 2 satelites yesterday after my node being up for over a year. Quite unexpected and the only “error” I also saw was similar to yours, ping failed. Which seems just like a temporary communication issue that could be caused by X things.
I am quite confident I did not lose any data. That leaves me only option 2, although buffled how. (Suddenly, 2 satelites disqualify my node for timeout on the same day??)
Can I manually force a re-audit / prove that the data is indeed there? Would be happy to do this for the satelites that disqualified my node.
If your audit score is below 0.6 (60% on the dashboard), the disqualification is permanent and not reversible.
I can ask to check logs on satellites for your NodeID (it could take a time to get answer though).
If you have logs on that time, I would like to ask you to search for GET_AUDIT and failed in row.
On two satelites my audit score is now 0.59xxx so that checks out as a reason. I checked my logs, and can’t seem to find any GET_AUDIT and failed lines. What I do see are the likes of this,
ERROR orders.12rfG3sh9NCWiX3ivPjq2HtdLmbqCrvHVEzJubnzFzosMuawymB failed to settle orders for satellite {"satellite ID": "12rfG3sh9NCWiX3ivPjq2HtdLmbqCrvHVEzJubnzFzosMuawymB", "error": "order: CloseAndRecv settlement agreements returned an error: context canceled", "errorVerbose": "order: CloseAndRecv settlement agreements returned an error: context canceled\n\tstorj.io/storj/storagenode/orders.(*Service).settleWindow:491\n\tstorj.io/storj/storagenode/orders.(*Service).sendOrdersFromFileStore.func1:422\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:57"}
I just checked the disk, SMART data does not report anything and also running a Windows file system check did not return any errors either. ( I presume having e.g. a single bad sector on the drive would cause storj to fail a single piece audit. If a new, random piece, audit is then requested, I would find it extremely unlikely to have a bad sector in the position of that specific new piece again. )
Is there anything else that can be checked?
Edit: Can I check the history of my audit score? (I would like to see if it was dropping slowly or suddenly on the satelites in question.)
Running chkdsk in read-only mode (not fixing errors) also did not find anything.
Windows has scanned the file system and found no problems.
No further action is required.
7630882 MB total disk space.
4065268 MB in 3974805 files.
1605164 KB in 12327 indexes.
0 KB in bad sectors.
4292355 KB in use by the system.
65536 KB occupied by the log file.
3559854 MB available on disk.
I can run a complete disk surface check, but I doubt that it would give back anything else.
The aim here was to see if there was any error with the disk, potentially causing the issue, and not to fix it. But for the sake of completeness, I ran an 18h chkdsk full check with repair. No suprises: no error means nothing to repair and I got back the same result. (Ran as administrator at all times.)
Windows has scanned the file system and found no problems.
No further action is required.
7630882 MB total disk space.
4014782 MB in 3979698 files.
1605164 KB in 12327 indexes.
0 KB in bad sectors.
4297219 KB in use by the system.
65536 KB occupied by the log file.
3610336 MB available on disk.
As a summary,
The drive itself is 100% fine, healthy, has no errors.
No data was deleted accidentally or otherwise from my part.
The node is running fine.
However, it was still disqualified on 2 satelites.