Hello guys,
I started passive migration for one of my five nodes, 2 TB, just to test the difference between hashstore and piecestore, since I don’t have much data saved on it.
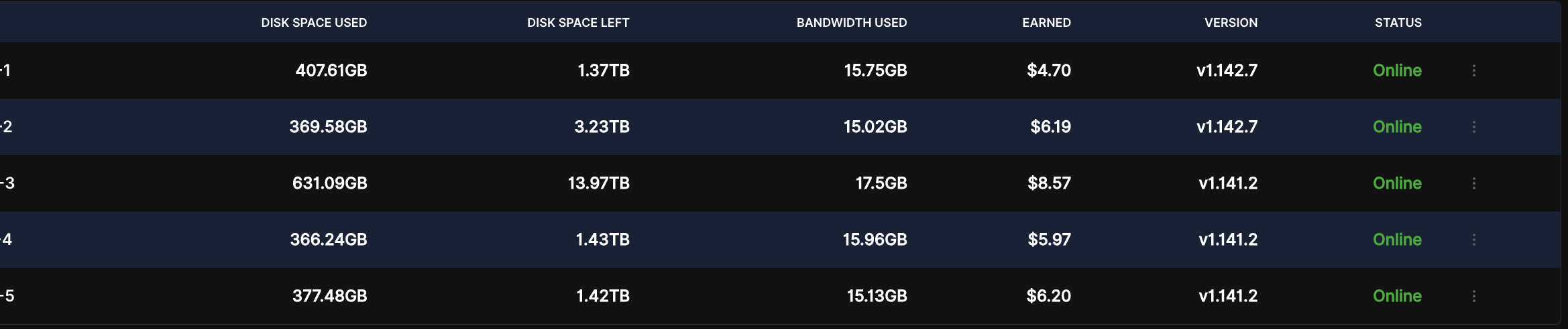
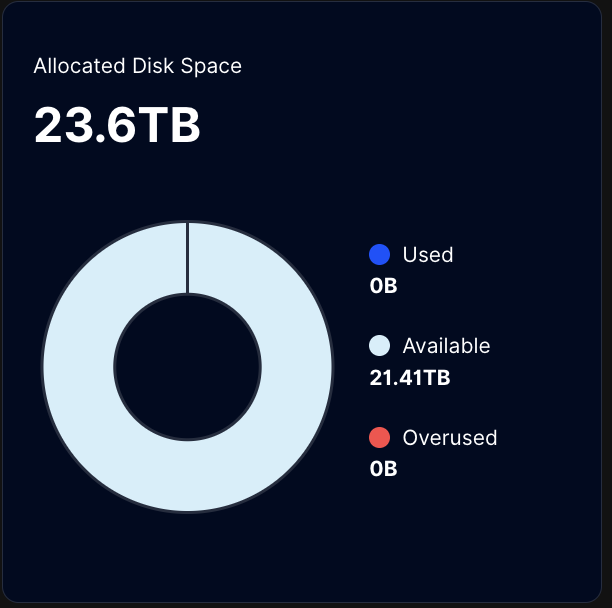
However, even though all values have been set to “true” in the /meta/*.migrate files, the migration still does not activate.I cannot see any logs related to the hashstore even after a couple of days. The piecestore is still in use, with the only difference being that Multinode now shows the “Used” value as 0 TB, while it should be roughly around 2.8 TB.
I see that there is already a discussion on this matter: Single node and multinode dashboards shows different values after migration to hashstore, but I don’t understand whether a suitable solution has already been found and we just need to wait for an update, or whether we need to intervene manually to resolve the bug ourselves.
Logs from the nodes:
user@server:~ $ sudo docker logs node-1 --tail 500 | grep "enqueued for migration" 2025-12-01T19:10:05Z INFO piecemigrate:chore all enqueued for migration; will sleep before next pooling {"Process": "storagenode", "active": {"12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S": false, "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs": false, "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE": false, "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6": false}, "interval": "10m0s"}
user@server:~ $ sudo docker logs node-5 --tail 500 | grep "enqueued for migration" 2025-12-01T19:10:02Z INFO piecemigrate:chore all enqueued for migration; will sleep before next pooling {"Process": "storagenode", "active": {"121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6": false, "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S": false, "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs": false, "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE": false}, "interval": "10m0s"}
user@server:~ $ sudo docker logs node-4 --tail 1500 | grep "enqueued for migration" 2025-12-01T19:10:01Z INFO piecemigrate:chore all enqueued for migration; will sleep before next pooling {"Process": "storagenode", "active": {"1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE": false, "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6": false, "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S": false, "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs": false}, "interval": "10m0s"}
user@server:~ $ sudo docker logs node-2 --tail 1500 | grep "enqueued for migration" 2025-12-01T19:03:50Z INFO piecemigrate:chore all enqueued for migration; will sleep before next pooling {"Process": "storagenode", "active": {"12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S": false, "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs": false, "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE": false, "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6": false}, "interval": "10m0s"}
user@server:~ $ sudo docker logs node-3 --tail 1500 | grep "enqueued for migration" 2025-12-01T19:14:20Z INFO piecemigrate:chore all enqueued for migration; will sleep before next pooling {"Process": "storagenode", "active": {"1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE": false, "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6": false, "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S": false, "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs": false}, "interval": "10m0s"}
*.migrate file Configuration example:
user@server:~ $ sudo nano /mnt/node-4/storage/hashstore/meta/121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6.migrate
GNU nano 7.2 /mnt/node-4/storage/hashstore/meta/121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6.migrate {"PassiveMigrate":true,"WriteToNew":true,"ReadNewFirst":true,"TTLToNew":true}
I’ve also saw that hashstore rollout has been paused due to an issue on Windows, however I thought it had been fixed few releases ago.
Any suggestions?
Thanks!