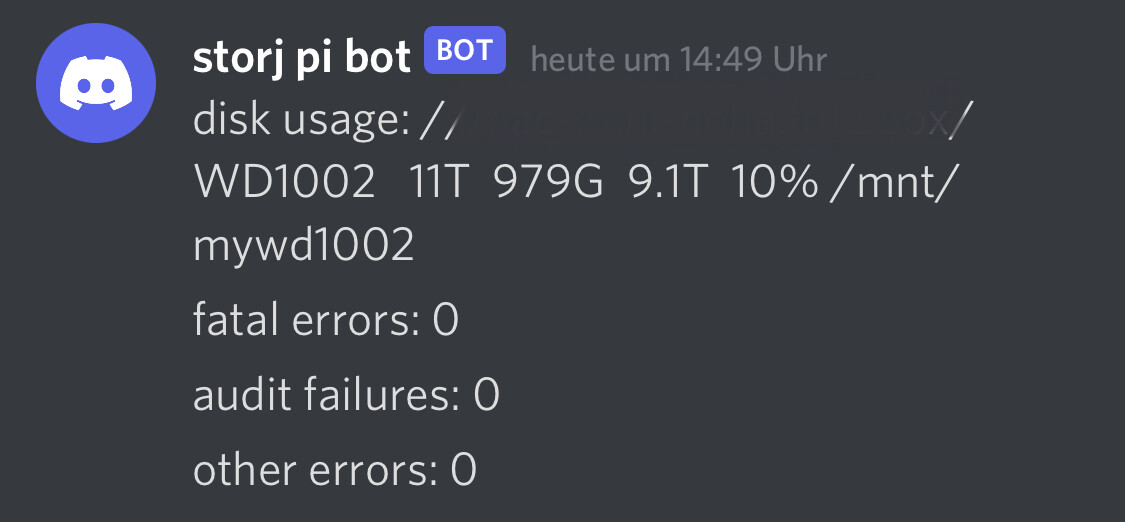
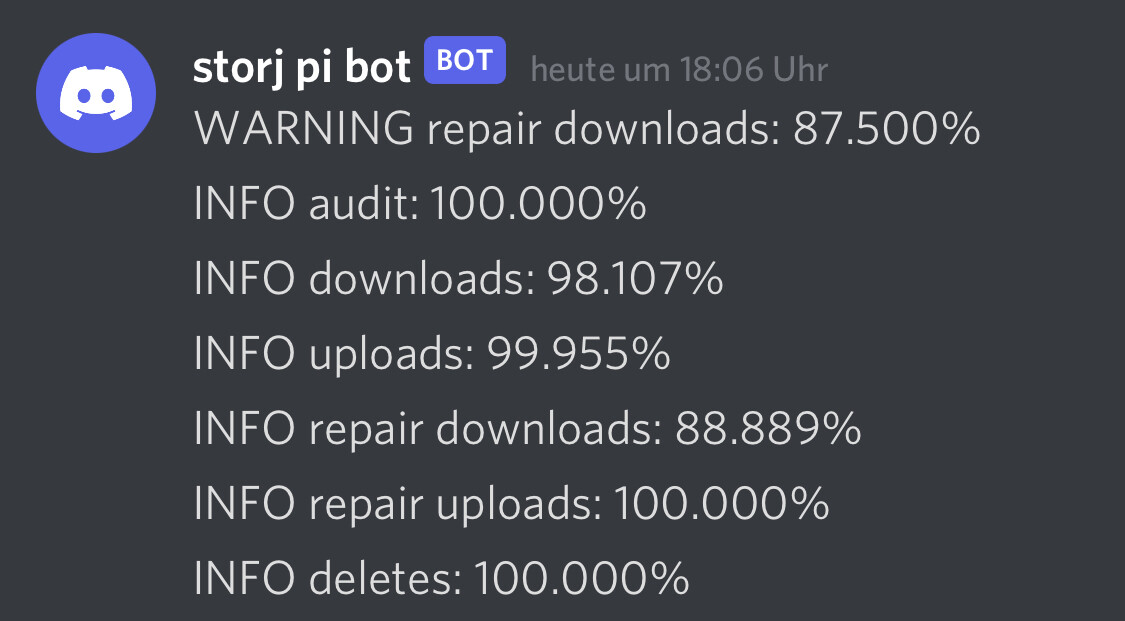
I was wondering, if I could be aware of any error message in the logs, when they occur and not when I realise my node is offline or similar.
I’ve found out, that pushing warnings to a Discord webhook would fit my needs best. That’s why I have found the following howto and script (both at the end of the post).
My questions to you experts:
Which log messages should I care of?
How can I [pipe or grep or summarize] the log analysis results into the given .sh script, mentioned above?
Ideally I run a .sh script with crontab regularly. What are your recommendations here?
Thank you very much in advance!
#!/bin/bash
message="$@"
## format to parse to curl
msg_content=\"$message\"
## discord webhook
url='https://my-discord-webhook-url'
## sending the message to discord
curl -H "Content-Type: application/json" -X POST -d "{\"content\": $msg_content}" $url
i’ll post my first draft of it here, hopefully sooner than later, have had something like this in mind for a long time but never really wasn’t sure of where or how to pipe the data.
i plan to make it very straight forward to setup, atleast the parts i’ve been working on, and i already performance tested and optimized the solution, even if the last couple of bits doesn’t work exactly yet.
and thus far it’s pretty sleek, but don’t want to to be to advanced either because it will be running all the time.
oh i’m not great at it either lol, just sort of stumbling ahead one byte at a time lol…
and maybe i’m a bit picky about how to make it, because i want to consider the performance impact.
my script seems to be failing again and not for the first time… not sure my solution is even viable, since logs aren’t very useful if they don’t work reliably…
i will most likely be switching from my custom logging script to this.
This will ping me via discord, in case the download rate drops below 98% and periodically in debug mode just for my (daily) information. Having the success rate script prepared, it is called via crontab with and without parameters.
I’ll extend that with other scripts like “scanning” the logs for FATAL or ERROR messages and/or SMART tests of the HDD(s) and push them on a regular base as well.
i was told one shouldn’t create ones own logging scripts… i guess its a bit like the issue with creating ones own mail server, its just a bad idea because even tho it’s supposedly a fairly simple task, it does end up becoming much more advanced and labor intensive as it progresses.
my failure i think was in me trying to process the logs while they was being exported, to avoid them being read multiple times, want to cut down on iops where i can.
it seemed to work at first, but for some reason the script that would work fine for one container might not want to execute correctly for others, maybe due to some inherent limitations of my server, or other software issues.
i hope the grafana / prometheus / loki solution can process the logs live with out issue, but i’m sure they can do that just fine.
my attempts at processing my logs with custom scripts sure wasn’t a good idea and now about 1 year in i can just throw it all out lol
one of the issues with docker logs storagenode 2>&1
is that it will read the entire storagenode log file since last update, so this is an ever increasing resource demand, ofc it doesn’t matter to much if it doesn’t do it to often, but then that defeats much of the point of live tracking it for alerts.
one could set a max size for the storagenode log file in docker or use a daily log file and run the script on that…
this parameter will set the max megabyte size for docker logfiles based on megabytes, usually on older nodes its like 20-45 MB a day i think…
so each time your script runs now at the day 18 since the last docker storagenode release push your docker log file will be something along the size of 400MB to 2GB which you seem to be processing twice… and then however many times you decide to do that per day.
#docker log size max parameter set to 1MB
--log-opt max-size=1m \
docker logs --help
Usage: docker logs [OPTIONS] CONTAINER
Fetch the logs of a container
Options:
--details Show extra details provided to logs
-f, --follow Follow log output
--since string Show logs since timestamp (e.g.
2013-01-02T13:23:37Z) or relative (e.g. 42m for 42
minutes)
-n, --tail string Number of lines to show from the end of the logs
(default "all")
-t, --timestamps Show timestamps
--until string Show logs before a timestamp (e.g.
2013-01-02T13:23:37Z) or relative (e.g. 42m for 42
minutes)
i didn’t have much luck with the --log-opt max-file= multiple files thing, but didn’t really give it much of a chance as i didn’t really need it for anything… maybe i just did something wrong.
-rw-r----- 1 root root 53011692 Nov 27 22:47 abc-json.log
-rw-r----- 1 root root 100000841 Nov 26 23:13 abc-json.log.1
-rw-r----- 1 root root 100000057 Nov 24 20:07 abc-json.log.2
...
I intend to optimise logging either by logging to the RAM or logging to another, external HDD - in order to reduce write operations on the RPi’s SD. Will keep you posted.
weird how your logs seems larger than mine… i don’t think my zfs compression is counted when just using ls -l
because only zfs can see that its compressed…
1 is 16tb and 2 is like 4tb so the size seems almost irrelevant to the log sizes…
and 3 is even less…
these are all 24 hour logs
i guess these scripts might also be failing and your logs are the correct size and mine are lacking data, haven’t gotten around to replacing my custom scripts
-rw-r--r-- 1 100000 100000 27269607 Nov 27 22:54 2021-11-27-sn0001.log
-rw-r--r-- 1 100000 100000 30906674 Nov 27 22:54 2021-11-27-sn0002.log
-rw-r--r-- 1 100000 100000 24092844 Nov 27 22:54 2021-11-27-sn0003.log