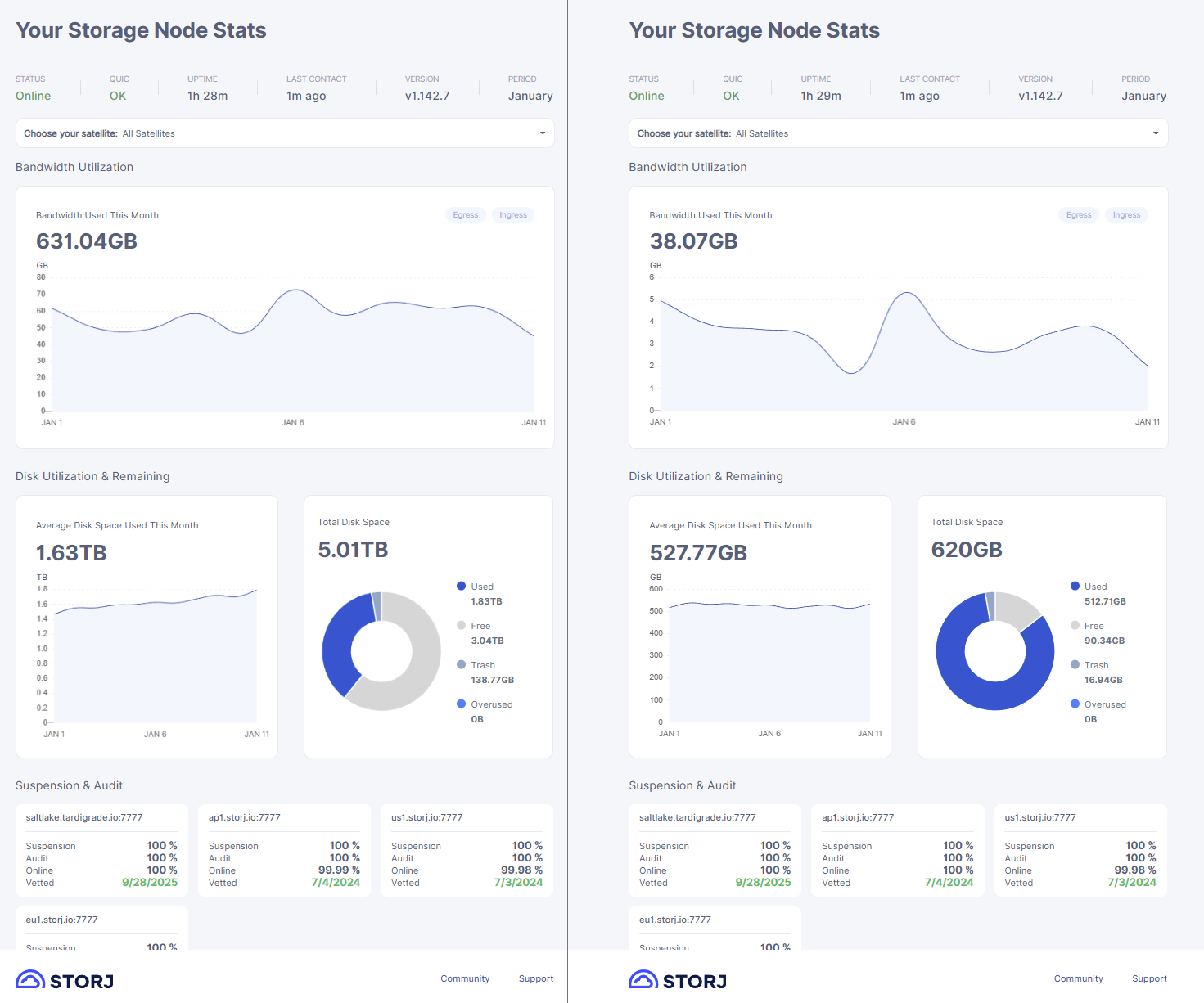
Here’s an image of two nodes on the same subnet. There are 25 nodes on the same subnet. 24 of them are showing the same behavior; nodes are sized from 500-650GB, and have all completely stalled in growing in size. The 25th node is sized at 5TB, and gets healthy ingress every day.
This is not really a problem so to say, but I would like for the 24 small nodes to fill up and then stop ingressing, instead of holding back at around 80%
All nodes are dockerrized, have been running for years and are healthy. All nodes are running Hash Store, and were upgraded to that on the exact same time. I don’t come to this location very often, and last time I did was back in summer, where I set the nodes to do the Hash Store conversion - I must have left the 25th node on 5000GB instead of 500GB.
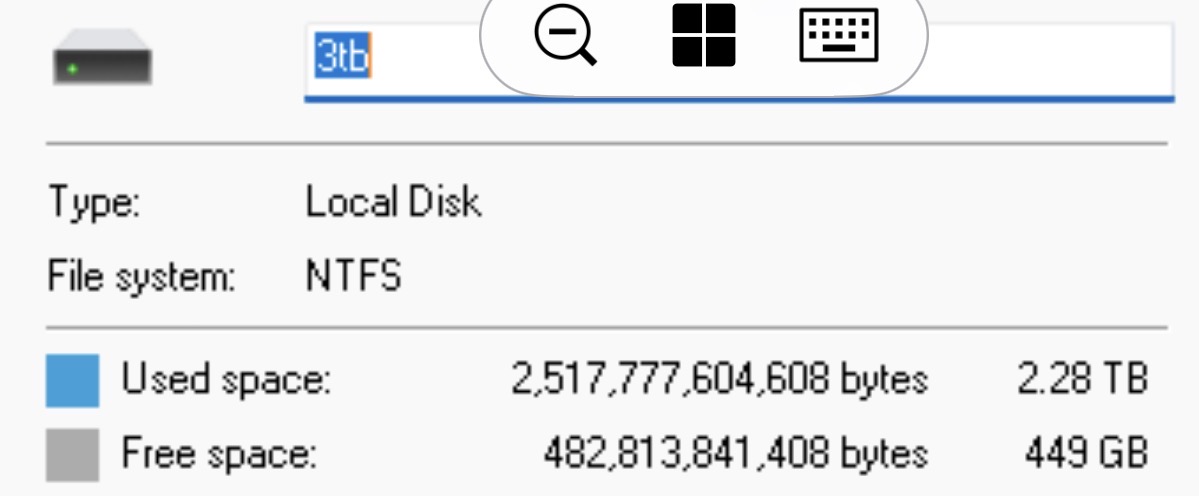
I don’t know that this has anything to do with anything: but I often see nodes that hover around 70-90GB Free. No matter how large the disk is, no matter how much trash, no matter how long they’ve been running.
I can’t explain it. That final space never fills. I can add 100GB to the node… it will fill that new space… and pause at 70-90GB Free again.
I agree, it sounds like something like that, but all of the nodes differ slightly in size, and it does not seem like it’s a fixed amount of space in GB, but in percentage of total node size instead. Other than manually starting the Hash Store conversion, these nodes are bog standard with no exciting configuration changes
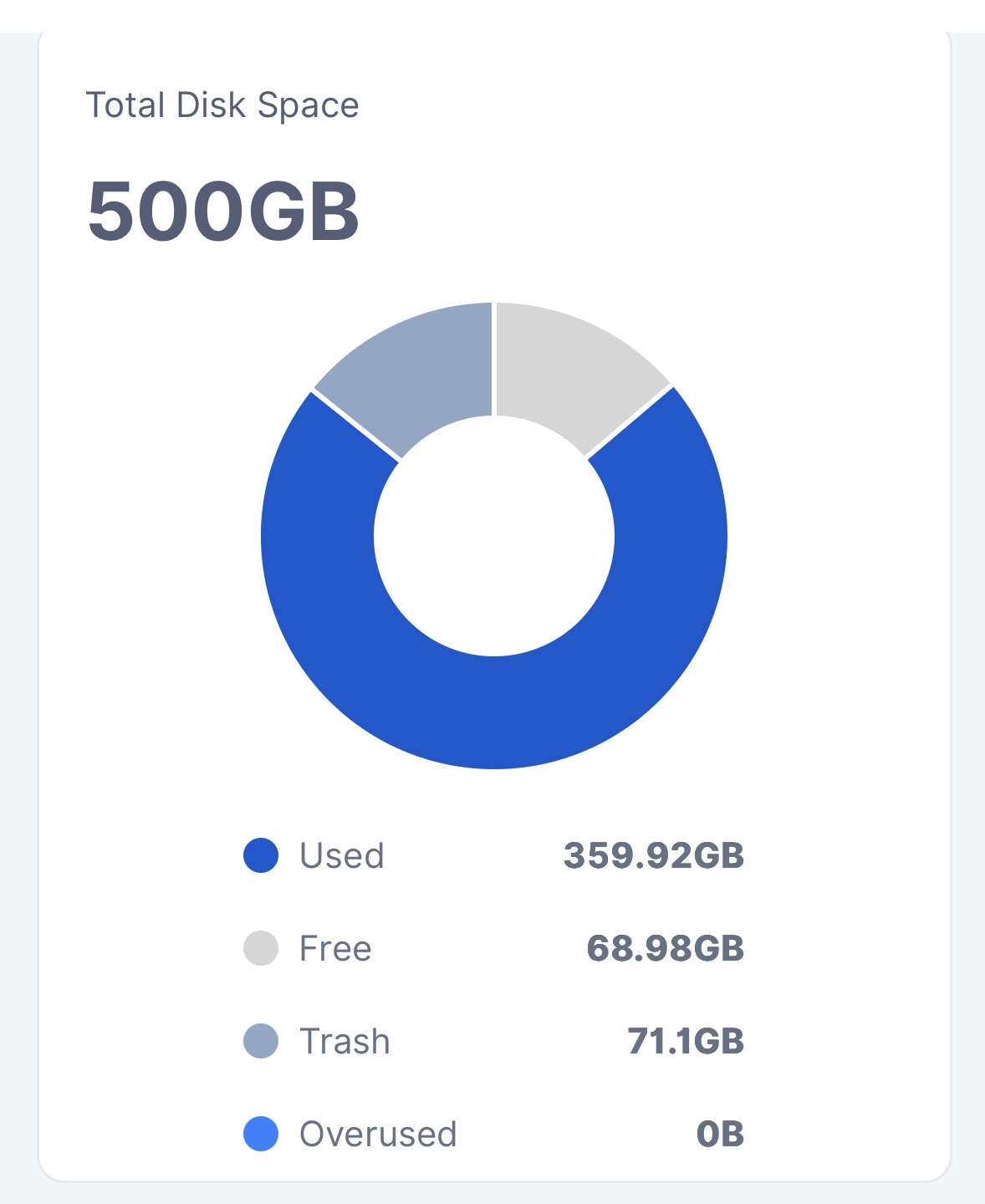
I see this happening to my node too. It’s fully vetted, has a 500GB allocated space, but it stopped getting ingress at 360GB occupied. It has 14% space left.
I don’t use dedicated disk option and it’s fully migrated to hashstore. After migration, I cleaned the blobs and deleted all db-es (my standard procedure). No lazzy walker. Start up piece scan active. Ver 1.142.7. Docker in Ubuntu.
What would be the cause of this? I’m pretty sure is related to hashstore.
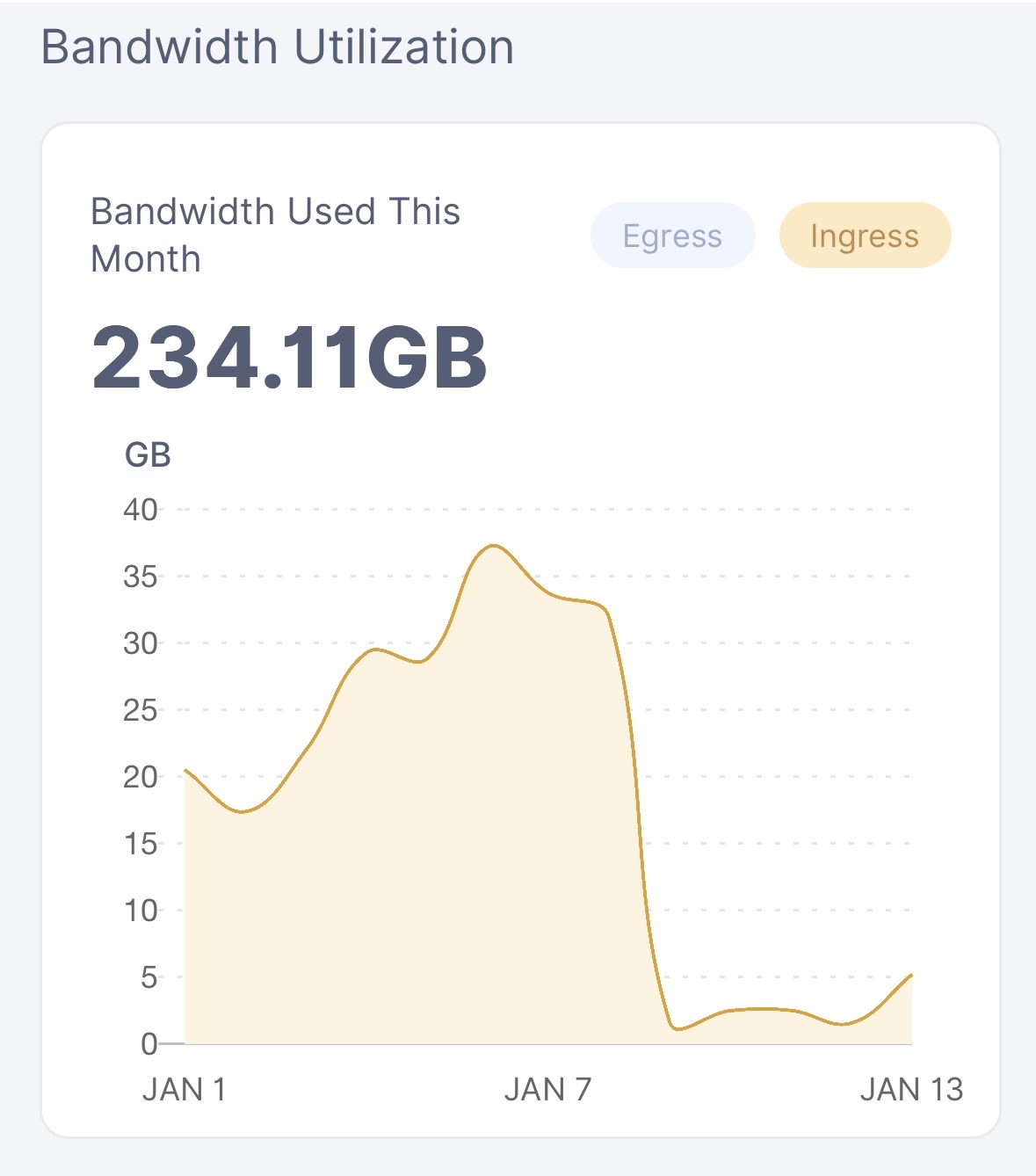
I have the same problem. On the node dashboard, I have 350 GB free, but it never fills up. On the Multinode dashboard, I only have 5-10 GB. The node is 1.142.7, the multinode is the latest version. No dedicated disk. Allocated 2.5 Tb
I don’t use multinode dashboard, but the underlaying storage is the same RAID0 (BAD, I know) volume for all the 25 nodes. It’s two 18TB drives, so there’s plenty of space left on it, and each individual subfolder representing a node corresponds with what each node thinks it’s using itself
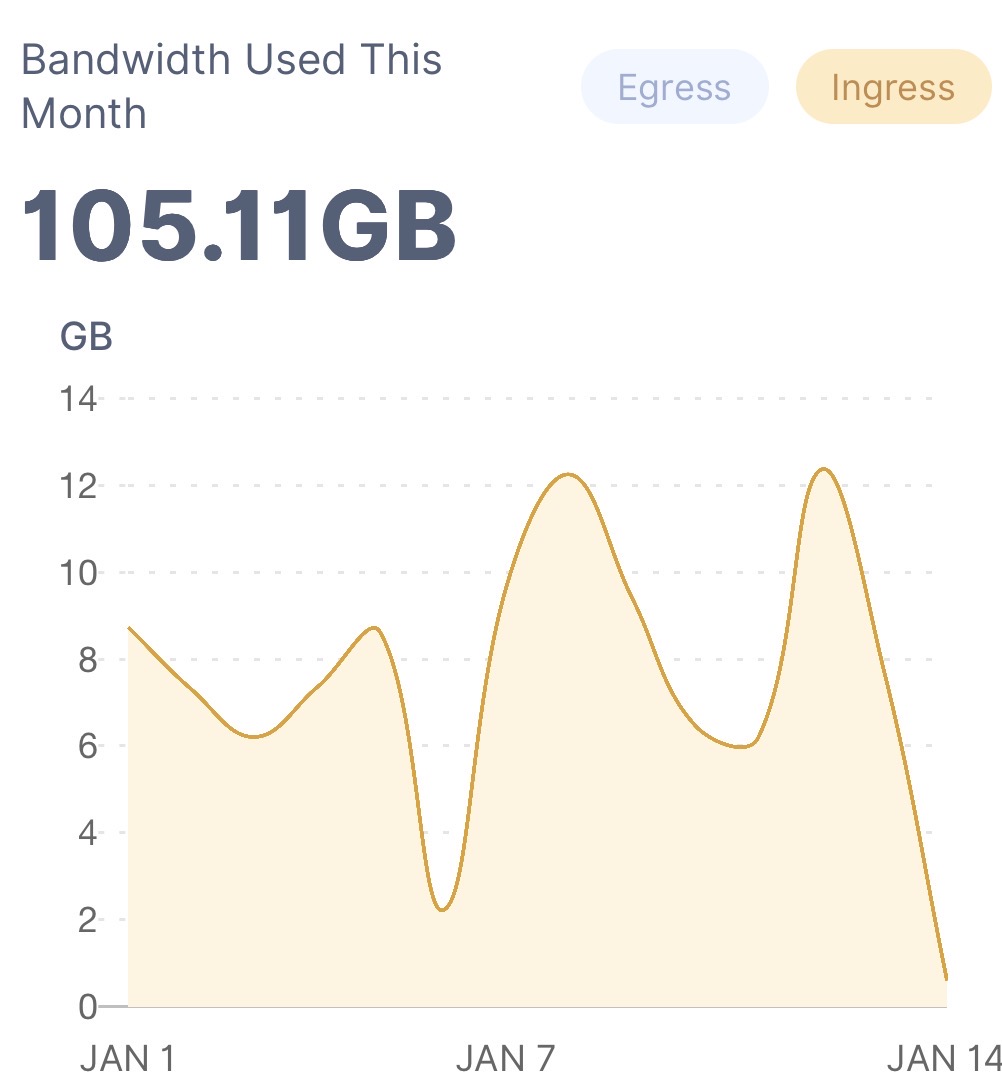
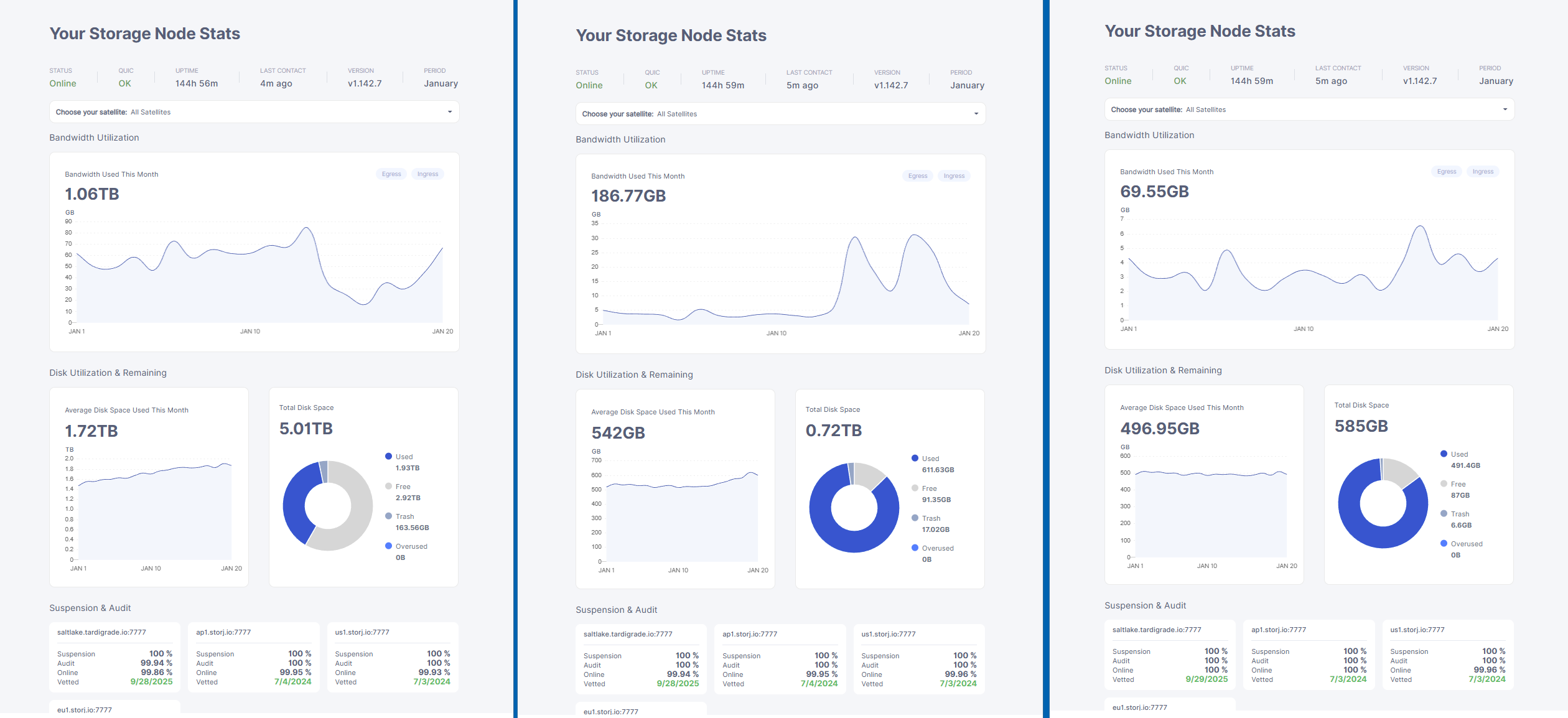
I wanted to see if your hypothesis held water - and it does. I added 100GB to the node from before, and look what happened
Left: Large node from before. A dip can be seen from the 14th to the 19th, where it shared ingress with the newly grown node
Middle: “Troubled” node from before. I added exactly 100GB to it, and it’s clearly visible that it added 100 GB, and then stopped growing again. I don’t know why it had less ingress Friday the 16th, but the same bump can be seen on the other node; I’ll chalk this down to randomness.
Right: Random node on same subnet; no change in size or major network fluctuations over the month Edit - All of the other 23 nodes on this subnet had increased ingress the 16th, current thought: There have been some TTL data that got deleted on all of them.
When I created the post, the “troubled” node was at 512GB, and now after adding 100GB it grew to exactly 611GB before stalling again. (Edited 511 → 611, thanks for spotting that typo @Roxor)
If all goes well, all of this is just a random bug, that will be fixed in a soon update
I wonder if you shrink the allocated space, will the occupied space will shrink too, to make 100 GB free again? Of course it will take some time, for the usual deletes to make that room.
Users are reporting a huge bonanza bloomfilter deletions. See thread:
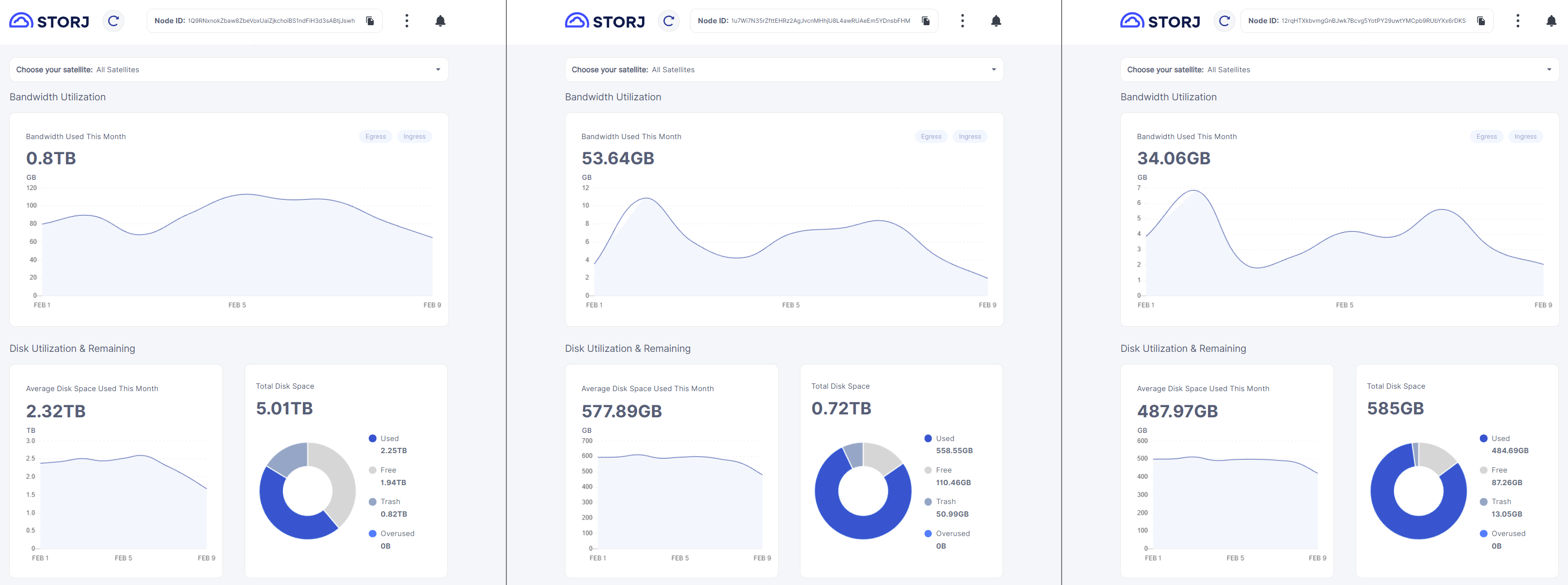
Interested in what kind of data might be deleted, I thought it would be fitting to check the nodes that have been discussed earlier in this very thread.
Therefore:
Left; large node - It is pretty much the only node that get’s ingress on this subnet, as all the other nodes have stabilized at around 80% filled, with as much ingress as egress. This large node has lost a significant portion of it’s data.
Middle; node that I expanded 100GB to test if it would grow to fill that space, and then stop ingressing. As its first ~500GB is old “stagnant” data, it was not hit very hard
Right; random old node on the subnet. It has been at around 80% utilization for the last ~year. It has some trash, but is almost untouched by deletions.
My poormans conclusion: The recent bloom filter affected very new data, but a lot of it .
I think you’re right. Looking at Th3Vans numbers… I think he only lost around 10TB. I believe a lot of the recent total-used-space growth has been captured by nodes in the US… and that yes the recent large deletion was of fresh data.
So US nodes that had been winning a lot lately probably got hurt the most by BFs in the last day or so.