I’ve been trying forever to transfer my node from Windows to a different computer running linux.
I followed all the directions both in the guides and what @Alexey has told me to do in other posts but I don’t think the node is up and running because the node dashboard won’t load.
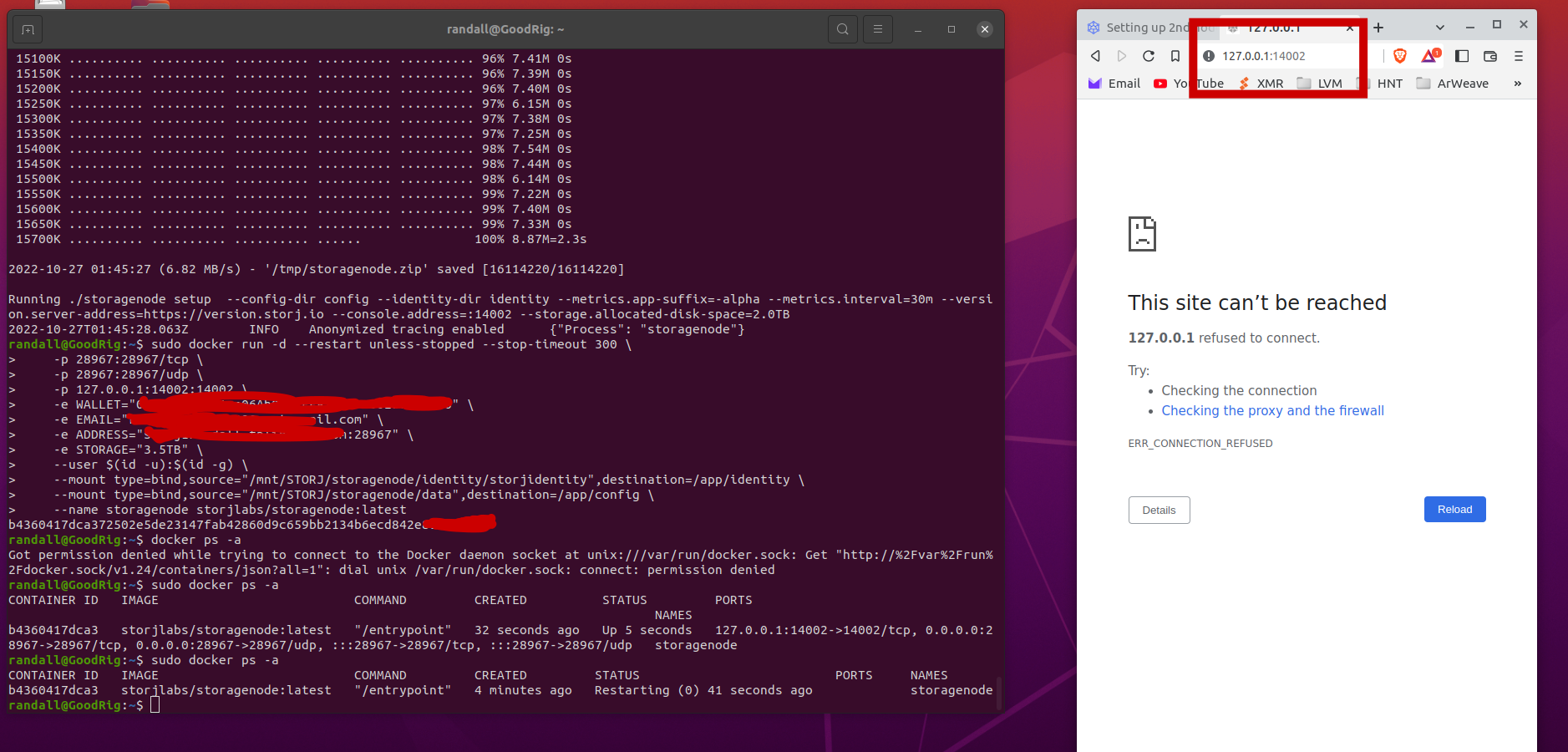
Here is a screenshot. I believe setup worked just fine and I’m not getting any error when I input the run command but never the less the dashboard will not load
Please provide the last 20 lines from your logs (text please, not a screenshot).
To prettify the look, place logs lines here between two new lines with three backticks, like this
2022-10-27T09:51:35.621Z INFO bandwidth Performing bandwidth usage rollups {"Process": "storagenode"}
2022-10-27T09:51:35.621Z WARN piecestore:monitor Disk space is less than requested. Allocated space is {"Process": "storagenode", "bytes": 219709210624}
2022-10-27T09:51:35.621Z ERROR piecestore:monitor Total disk space is less than required minimum {"Process": "storagenode", "bytes": 500000000000}
2022-10-27T09:51:35.621Z ERROR services unexpected shutdown of a runner {"Process": "storagenode", "name": "piecestore:monitor", "error": "piecestore monitor: disk space requirement not met", "errorVerbose": "piecestore monitor: disk space requirement not met\n\tstorj.io/storj/storagenode/monitor.(*Service).Run:125\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2.1:87\n\truntime/pprof.Do:40\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2:86\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:57"}
2022-10-27T09:51:35.621Z ERROR gracefulexit:blobscleaner couldn't receive satellite's GE status {"Process": "storagenode", "error": "context canceled"}
2022-10-27T09:51:35.621Z ERROR collector error during collecting pieces: {"Process": "storagenode", "error": "pieceexpirationdb: context canceled", "errorVerbose": "pieceexpirationdb: context canceled\n\tstorj.io/storj/storagenode/storagenodedb.(*pieceExpirationDB).GetExpired:39\n\tstorj.io/storj/storagenode/pieces.(*Store).GetExpired:532\n\tstorj.io/storj/storagenode/collector.(*Service).Collect:88\n\tstorj.io/storj/storagenode/collector.(*Service).Run.func1:57\n\tstorj.io/common/sync2.(*Cycle).Run:99\n\tstorj.io/storj/storagenode/collector.(*Service).Run:53\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2.1:87\n\truntime/pprof.Do:40\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2:86\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:57"}
2022-10-27T09:51:35.622Z ERROR gracefulexit:chore error retrieving satellites. {"Process": "storagenode", "error": "satellitesdb: context canceled", "errorVerbose": "satellitesdb: context canceled\n\tstorj.io/storj/storagenode/storagenodedb.(*satellitesDB).ListGracefulExits:149\n\tstorj.io/storj/storagenode/gracefulexit.(*Service).ListPendingExits:58\n\tstorj.io/storj/storagenode/gracefulexit.(*Chore).AddMissing:58\n\tstorj.io/common/sync2.(*Cycle).Run:99\n\tstorj.io/storj/storagenode/gracefulexit.(*Chore).Run:51\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2.1:87\n\truntime/pprof.Do:40\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2:86\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:57"}
2022-10-27T09:51:35.622Z ERROR piecestore:cache error during init space usage db: {"Process": "storagenode", "error": "piece space used: context canceled", "errorVerbose": "piece space used: context canceled\n\tstorj.io/storj/storagenode/storagenodedb.(*pieceSpaceUsedDB).Init:73\n\tstorj.io/storj/storagenode/pieces.(*CacheService).Run:81\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2.1:87\n\truntime/pprof.Do:40\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2:86\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:57"}
2022-10-27T09:51:35.622Z ERROR bandwidth Could not rollup bandwidth usage {"Process": "storagenode", "error": "sql: transaction has already been committed or rolled back"}
2022-10-27T09:51:35.622Z ERROR nodestats:cache Get pricing-model/join date failed {"Process": "storagenode", "error": "context canceled"}
Error: piecestore monitor: disk space requirement not met
2022-10-27 09:51:35,681 INFO stopped: storagenode (exit status 1)
2022-10-27 09:51:35,682 INFO stopped: processes-exit-eventlistener (terminated by SIGTERM)
/dev/sdc1 on /mnt/STORJ type ext4 (rw,relatime)
nsfs on /run/snapd/ns/snap-store.mnt type nsfs (rw)
nsfs on /run/snapd/ns/brave.mnt type nsfs (rw)
nsfs on /run/snapd/ns/docker.mnt type nsfs (rw)
nsfs on /run/snapd/ns/discord.mnt type nsfs (rw)
All it says when I run “dh --si” is…
dh: error: "debian/control" not found. Are you sure you are in the correct directory?
I tried running that command in several different directories including “/mnt/STORJ/storagenode”
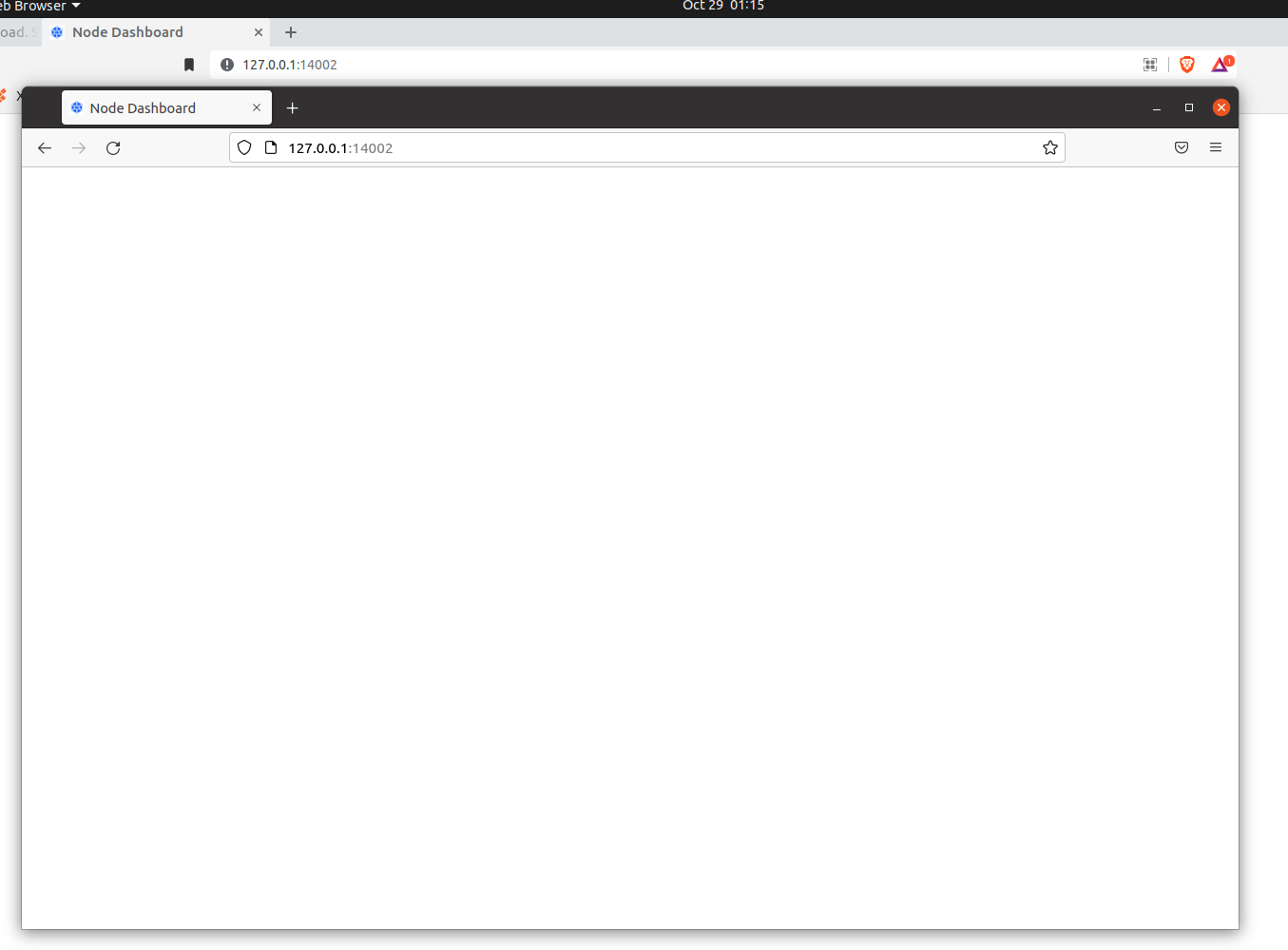
Also I noticed that I do get the little STORJ icon on the browser tab when trying to load the dashboard. It even says node dashboard. But the screen is blank. I don’t know if that helps at all. Here is a screen shot of that:
I completed every step in this guide (including static mount, port forwarding, and rysnc of orders, identity, and data) and things went smoothly except the dashboard won’t load.
I’m starting to worry I will lose my node as it has been down for a few days per the instructions in the guide to shut the node down on the Windows PC.
I tried another browser and it also recognized the IP address as the node dashboard but again gave me a blank screen. Is there anyway to externally see if my node is up and running at the issue is just with the dashboard?