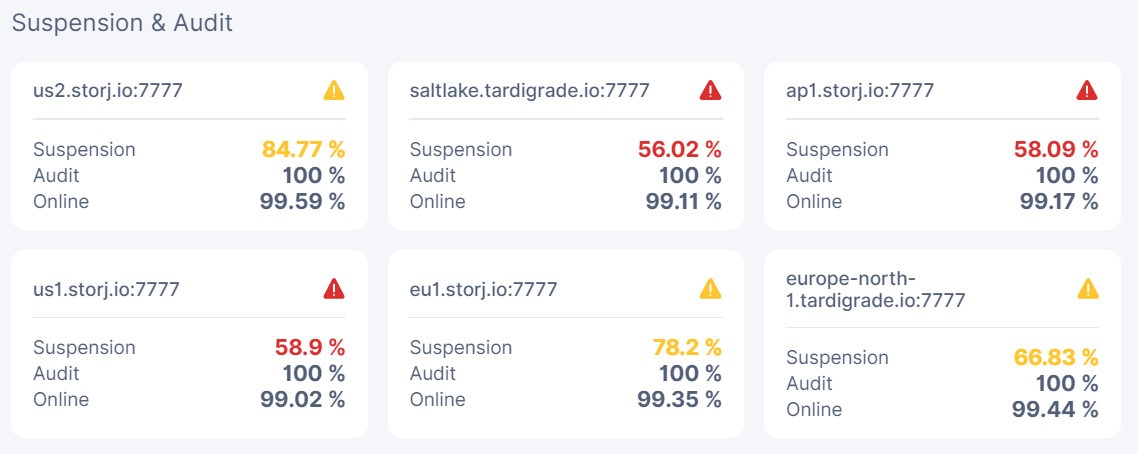
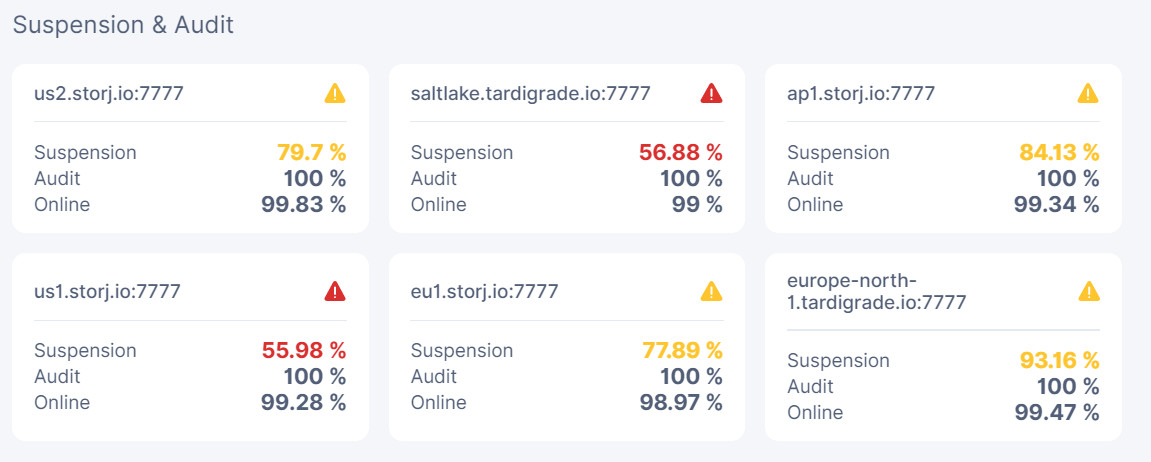
did you have any sort of issues and is the node still suspended on that satellite…
its not to difficult to offend the suspension score but that usually recovers very quickly…
had my system stall out a few days ago and got a few suspensions, but when i noticed and checked it a few days later it was all fine again.
yeah it surprise me to, apparently there are two stages or kinds of suspensions… one can be really short and is cause by a lot of intermittent issues in a short time, and the score will jump right back.
the other is the one we are more familiar with and usually lasts a lot longer.
don’t really know the exacts of it… i think it was @Alexey that was taking about it at one point.
That is weird, but regardless you should look at them. Unlike normal transfers, repairs shouldn’t do long tail cancellation, so you shouldn’t see errors for those at all.
I’ve experienced a similar thing with my latest suspension - huge traffic, directly linked linked to auditing and repairs. Node hang up - suspended. It took 3 days to recover and allow new ingress.
Yes. Nothing meaningful. It must have been stuck resp. offline somehow.
That was a good one: Up only 7 hours for this node. Which of course is not what it should be as I have not restarted it for days. So something must have gone seriously wrong.
Ah yes, this one is good too: dmesg: read kernel buffer failed: Operation not permitted
This is probably it.
20.10.7. I am on Debian but it seems I have pulled this from the original docker.com source.