if the disk can’t keep up stuff will go bad, if not immediately then over time…
but brief periods of problems like bandwidth.db locked won’t destroy a node… i’ve had it happen many times. (but with a lot of effort and trial and error, i have now gotten to a point where i basically never see it)
there really isn’t much to do, except reduce io to the storage media when possible.
here are a few options, i’m sure there are tons more… but i cannot remember them of the top of my head.
don’t install the OS on the same disk as the storagenode
disable xattr because this will cause extra write io
move the storagenode database to an ssd, or other hdd, the database load is rather extensive io and will greatly limit the storagemedia
make sure it’s not an SMR hdd
add more nodes to distribute the load between them.
if you run zfs the disabling atime will also reduce io by 1 per file write i think it is…
alternatively one can also add caches to help reduce the random io.
i’m running zfs for everything except my OS partition, so haven’t really had to the need to tinker with the linux partitioning stuff…
i did end up running my OS on xfs because alexey said it was faster, but later research into the topic made me doubt if that was the right choice, but thus far its been fine… tho was i remaking it today i would go with ext4 just because its like half a decade or more recent, than xfs…
after i installed linux i started using zfs, so my knowledge with linux parition and mounting configurations is basically no existing.
but certainly sounds like a good choice, and i added it…
maybe we should write a more specialized storagenode configuration recommendation…
not sure how well it works, but i started using
docker run -e RUN_PARAMS="--filestore.write-buffer-size 4096kiB --pieces.write-prealloc-size 4096kiB"
in my docker run command, i think it should also work for the binary, the run_params supposedly passes it through to the binary inside docker.
that is to reduce disk fragmentation because it shouldn’t write out files fragmented or allocates the space for the file in advance… not sure if it even works… but it seems to atleast from what little verification i’ve done…
not sure how to really verify if it works or not, but i’m sure someone will test that eventually… i haven’t had any problems while running it tho… and been using it for like 3 months or so now.
got it from somebody which was doing a deep dive because they was experiencing massive fragmentation of their data… and it made sense to me to start using it because, i know how much fragmentation can mess up a drive.
anyways seemed relevant, maybe you have a thought on that or maybe its peaked your interest. @BrightSilence
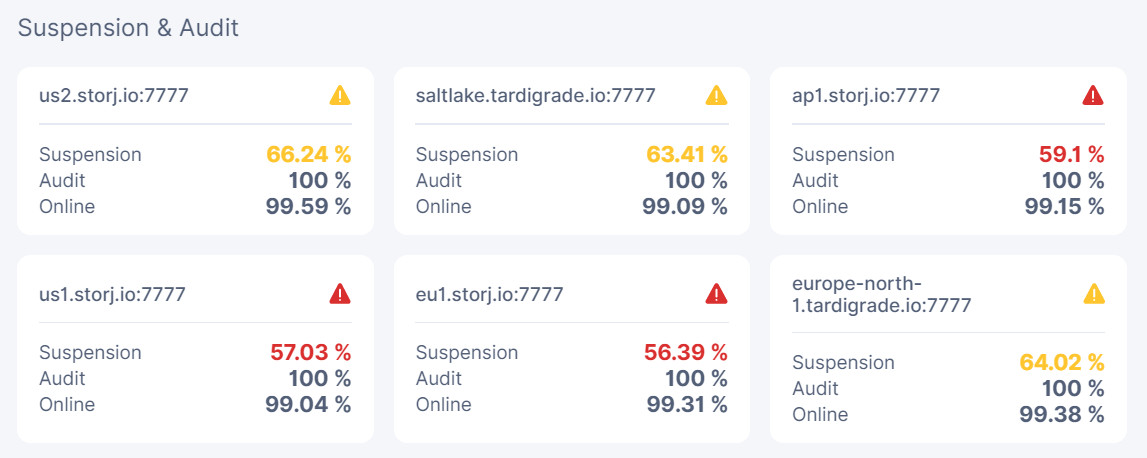
You can see that node2 has zero errors and the suspension got worse. So what should the typical error be? There is none.
Node1 has broken pipe error like below, but it did not affect suspension:
No, It should not.
I’ll ask the team, why there is no errors, but suspension score become worse.
Could you please submit an issue on GitHub and upload zipped logs from node2 to there? I think 5 last days should be enough.
I don’t have a Github account.
The logs got reset when I had rebooted yesterday I think. But it showed that since reboot the score got worse without new errors at least on node 2.
I mean I hope they don’t get disqualified but I’ll keep them running and if they don’t get disqualified I’ll have some more days of logs in a couple of days.
There is a bit of a delay between issues happening and lowered scores being reported back to the node. So this doesn’t necessarily mean there haven’t been any errors logged that are now gone.
Yes I see that, but how much time is that?
Probably not more than 24 hours?
So I think it is fair to keep the node running so we have logs for a good period.
Definitely shouldn’t be more than 24 hours. I would just suggest to ensure you have logs for longer so the response can’t ever be: “maybe the errors happened during that part that is missing in the logs you provided”
If you worry about losing logs in order to enable log redirection to a file you can always save the docker logs to a file prior to enabling the redirection.
If I ever run into an issue like this, my response would be: “Great, I have logs going back to June 2019, how much do you want?”. This also helps when missing file issues pop up. I can prove that a piece was delete many months ago if I have to.