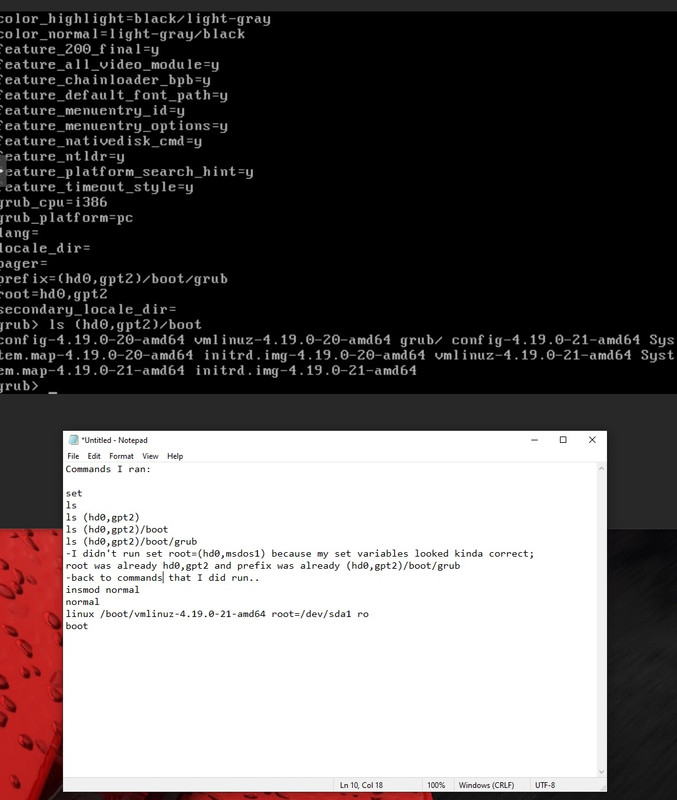
congrats on getting it working again.
running proxmox myself, the only issues i’ve had with updates or such things like random power offs and such, was due to how i ran the storage cache on the vm…
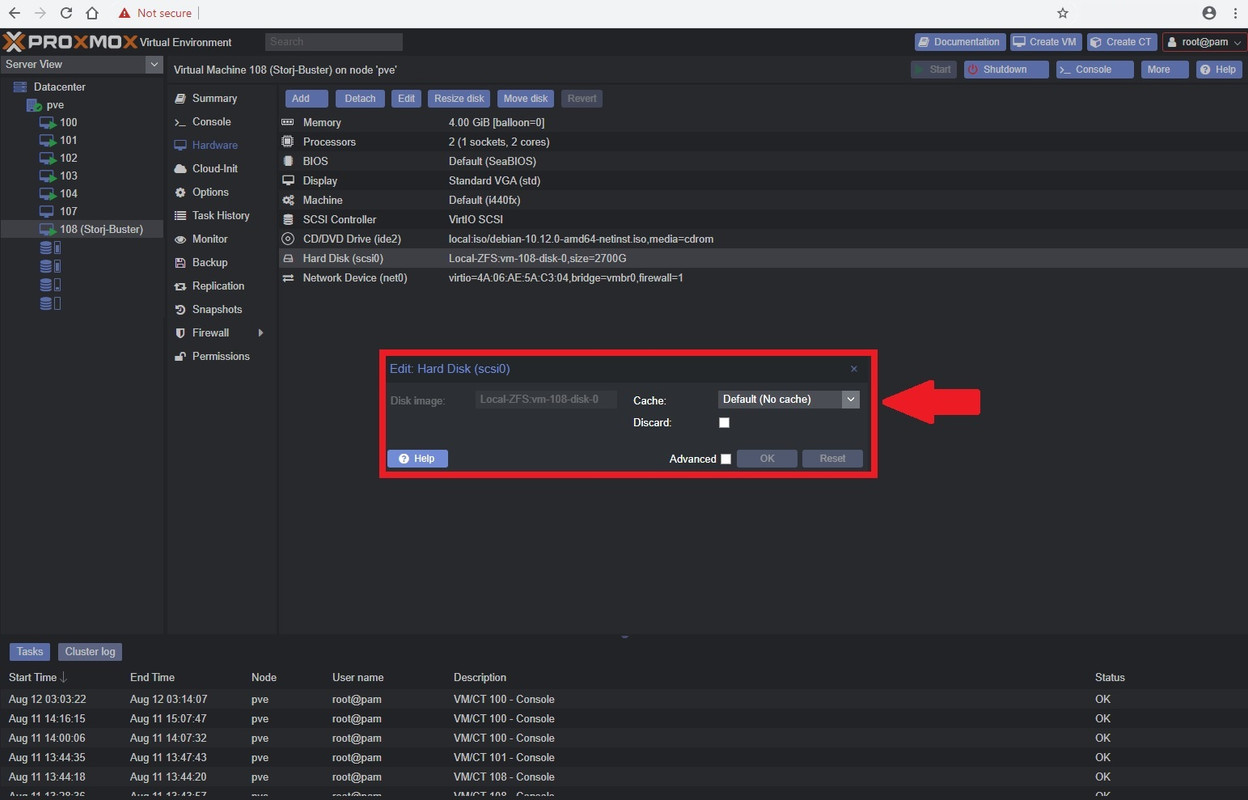
these days i leave it on default, because i just don’t want to deal with the bullshit that happens when running cache / writeback.
i’ve updated my proxmox vm’s and containers many times without issues, but i also had issues… its not always clearly why an issue arises, i can recommend using good storage setups, so that stuff doesn’t linger in RAM to long.
zfs seems really nice for VM storage, using a SSD with PLP for a SLOG device, i like my VM’s stable.
running without cache is a lot slower, so it often ends up depending on the use case.
also using the backup features of proxmox can be quite nice, which is why its often a good rule to keep the boot disk small, so its easy to backup.
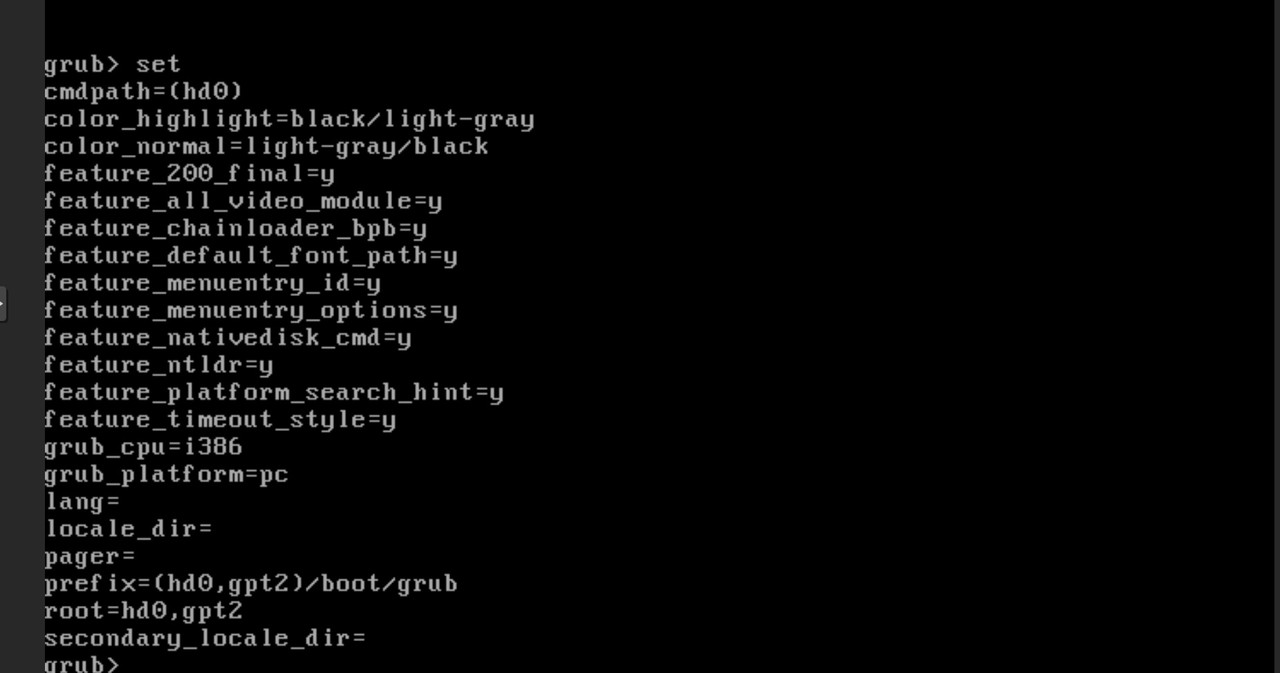
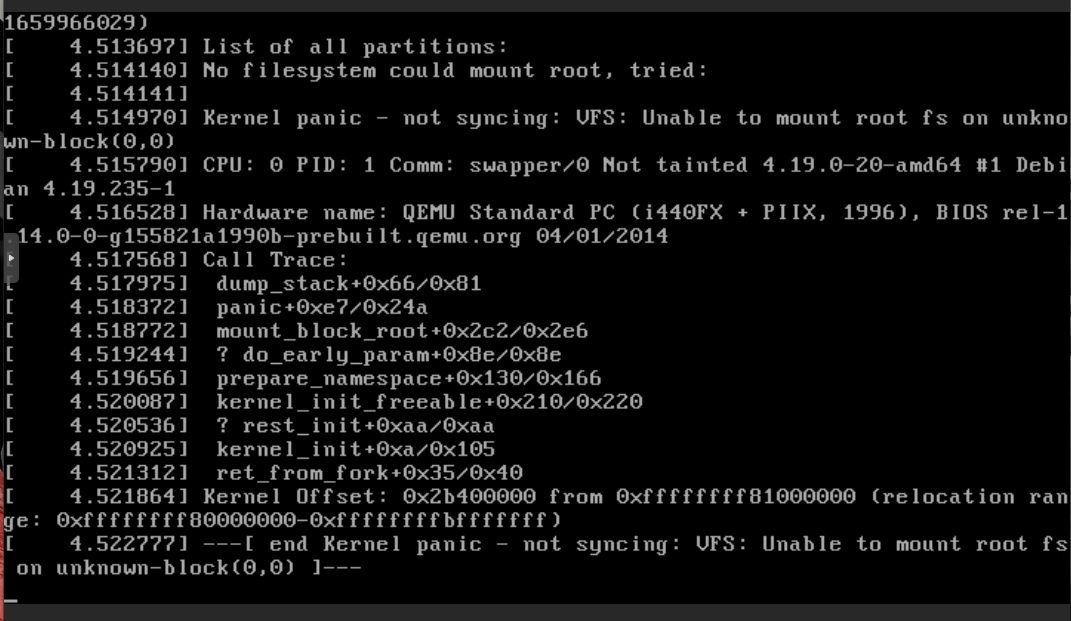
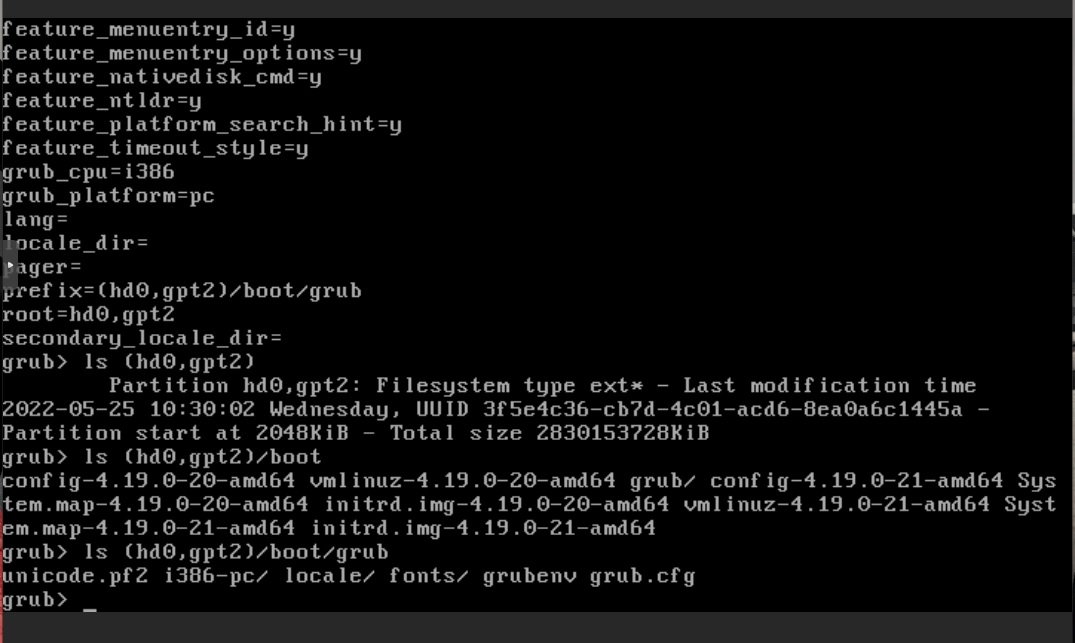
that being said, it does seem more like this issue was due to some sort of poor configuration, using the SDA / SDB / SDC… names i don’t really like, as they can change in linux when one starts having many drives…
so yeah i duno what exactly went wrong for you.
but its certain possible that it was something similar, for my zfs pool i’ve been using /dev/disk/by-id/…
names to define my storage devices, that way they will never get mixed up…
don’t think that was what happened… because your configuration seemed “fine” but clearly it wasn’t so somewhere something must have gone wrong.
i mean GPT2 isn’t exactly random data…
one can also use GPT identifiers / names to define physical storage… which is kinda cool, the reason i don’t like using that for ZFS is because, if the drive is corrupted and the GPT name is lost or removed, ZFS will not recognize the storage media and try to reintegrate it.
ofc locking storage media into a pool using hardware identifiers comes with its own issues, but i kinda like that it limits how much damage i can do.
even if it is rather annoying to work with at times, it does make me less able to kill me pools.
because i do stupid and dangerous stuff if it is the easy path forward lol
but i digess, to make a long story short…
make sure your VM disk cache is configured for default, in the Proxmox VM hardware disk tab.
its what has given me the most grief thus far.
maybe CP has a better idea of what happened.
i’m still only like 3 years into this stuff, so far from an expert.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}