This causes SNO confusion and worry, do the satellite operators know?

I’ll report to the team. Thank you!

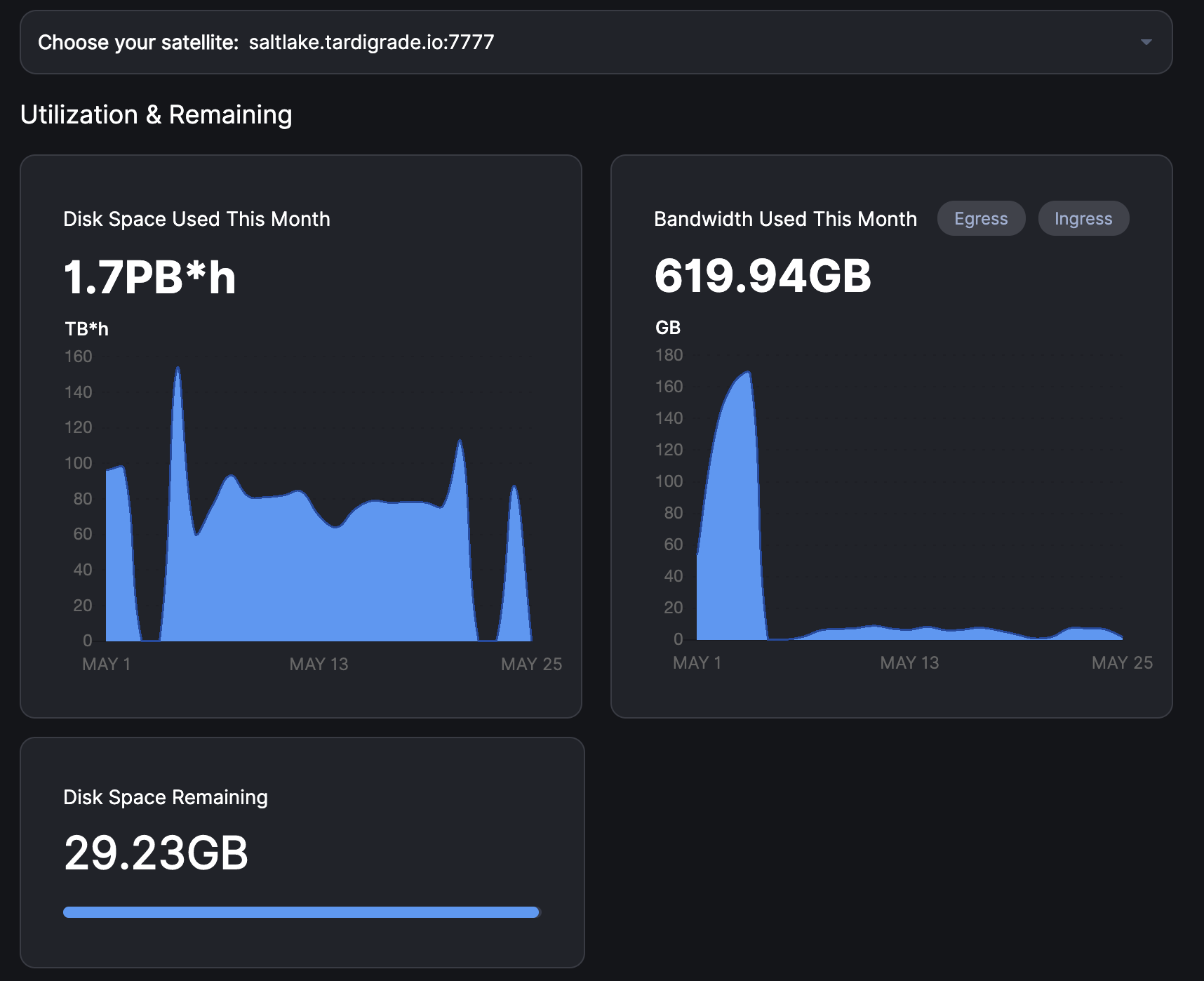
Same problem since 4 May

That’s not quite the same. That is your bandwidth used. I would check if your disk is used up or other problem
I think “it” has happened again

Hmm true.
Thought this might be why the ingress stopped but the ingress came from europe-north… But might be why the egress dropped a bit (or this was just a coincidence).
Is that graph for all satellites, or just Salt Lake? Have you checked it recently.
Some lag is expected in reporting storage usage data. However, we have noticed the lag is longer in the Salt Lake satellite than others. This is currently under investigation.
for me only saltlake is affected on 2 nodes. All other satellites are fine.
Just saltlake got a zero in the chart for me
Yep, seeing the same thing on all 3 nodes. @ethan, it’s expected for the current day, but we’re seeing it for yesterday as well.
for Salt Lake on 23 july in my graph of the disk space used is correct now. For 22 july is 0 yet
now both days are ok for me on node 1. node 2 missing 22nd but 23rd is there.
The storage node has a 12hr cache of storage usage. It is likely the account rollup for the 22nd had not completed when your storage nodes requested the latest usage , and cached the 0 value.
You could test by restarting the storage node, waiting about 5min , and checking the dashboard. The cache should refresh itself. I realize this is not a solution. Just a way to test the theory.
restarted the node, waited 20 minutes, 22nd still missing. It might catch up eventually like on the 1st node I guess…
But I don’t understand how a 12 hour cache should be relevant in this case sind the 22nd is over since ~21 hours.
The rollups for the 22nd completed around 17:30 UTC today.
If you would like me to investigate your specific node, you could DM me your storage node ID

Are they supposed to show up on the 23rd? This is without a restart btw.
22nd still shows as 0.
It’s ok for me now both 22 and 23 july. for all three nodes. i don’t restarted the nodes.
Saltlake didn’t do the rollover for the 22nd:

NodeID: 1cYRm7virx4Z7xXvgG9SxMBfJqkEA2XDoy6bWXfxkf2vLsmWjV
(deleted the other answer because I just did F5 and looked at the graph before selecting saltlake again… it’s early…)
Hope it helps you figure out the problem. Don’t care much about the Storage earnings from that day since it’s just a 800Gb “backup” node that I keep alive.
My concern, is only that it seems to get worse toward the end of the month. Just taking the picture (20) above, the variability is 6TBh at the first week of the month by the second week it is up to 10TBh and third week it is 16TBh.
I think it shows a capacity issue somewhere.
We’ve had assurance that it doesn’t affect payments.