@Odmin @cdhowie the issue is fixed in version v1.14.X
This is currently in progress and due to an internal oversight we removed the satellite a little to early again. The change was reverted, so a restart or the given cache period and the issue should be fixed until everyone is on v1.14.
2 Likes
A restart of the node didn’t fix the problem. Interestingly, what did is accessing the API from a different IP address. Using http://127.0.0.1:14002/api/sno/ shows the error but using http://$LAN_IP:14002/api/sno/ does not for some reason. I have no idea why the origin IP affects the results returned by the API (is that a bug?) but changing the monitoring API endpoint to use the LAN IP address instead of a loopback address resolved the issue for now.
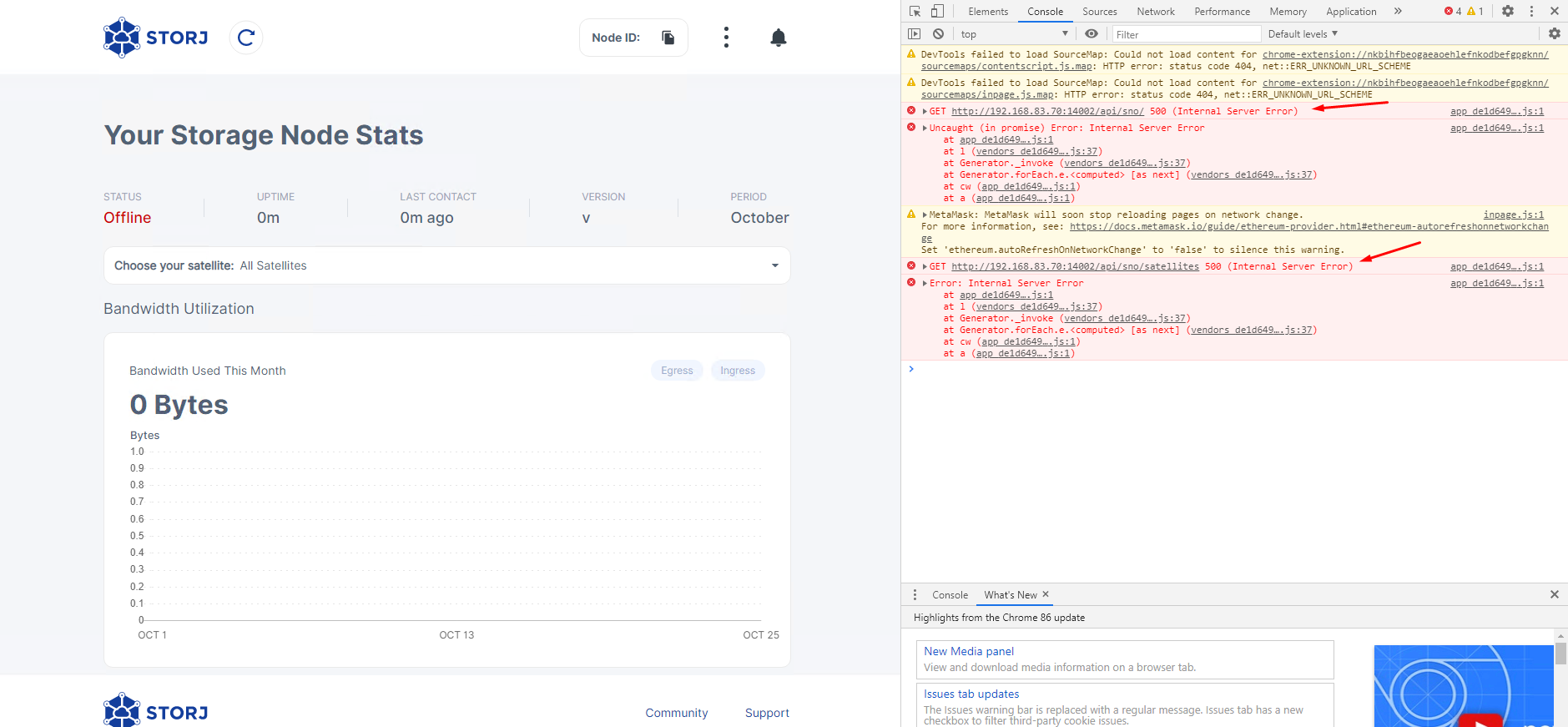
Unfortunately, the issue is not fixed and error 500 is still here:


cat /storj/trust-cache.json
{
"entries": {
"https://tardigrade.io/trusted-satellites": [
{
"SatelliteURL": {
"id": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S",
"host": "us-central-1.tardigrade.io",
"port": 7777
},
"authoritative": true
},
{
"SatelliteURL": {
"id": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs",
"host": "europe-west-1.tardigrade.io",
"port": 7777
},
"authoritative": true
},
{
"SatelliteURL": {
"id": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6",
"host": "asia-east-1.tardigrade.io",
"port": 7777
},
"authoritative": true
},
{
"SatelliteURL": {
"id": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE",
"host": "saltlake.tardigrade.io",
"port": 7777
},
"authoritative": true
},
{
"SatelliteURL": {
"id": "12rfG3sh9NCWiX3ivPjq2HtdLmbqCrvHVEzJubnzFzosMuawymB",
"host": "europe-north-1.tardigrade.io",
"port": 7777
},
"authoritative": true
}
]
}
}
1 Like
Can you try to restart the storagenode and clean the browser cache (or Ctrl-F5) after the restart?
We have had once that the updater didn’t restart the storagenode after update, so things worked only partially until restarted.
Because I do not see such behavior on 1.14.7 on both docker nodes.
Already did it, unfutuately the issue is still here.
How to reproduce?
Is it a new node?
What return the
curl -L 192.168.83.70:14002/api/sno
and
curl -L 192.168.83.70:14002/api/sno/satellites
from the CLI?
It is old node (>15 month), reproduction is simple, it apper after trusted_cache was updated, so you cat manualy remove trusted_cache and update it during storganode restart.
My trust-cache.json is updated
sudo ls -l /mnt/storj/storagenode1/trust-cache.json
-rw------- 1 root root 1204 Oct 25 07:48 /mnt/storj/storagenode1/trust-cache.json
And there is no Stefan satellite.
I have tried to remove this file and restart the storagenode
$ sudo mv /mnt/storj/storagenode1/trust-cache.json /mnt/storj/storagenode1/trust-cache-20201025.json
$ docker restart storagenode
storagenode
$ sudo ls -l /mnt/storj/storagenode1/trust-cache.json
-rw------- 1 root root 1204 Oct 25 08:54 /mnt/storj/storagenode1/trust-cache.json
Check:
$ curl -L localhost:14002/api/sno
{"nodeID":"*","wallet":"*","satellites":[{"id":"1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE","url":"saltlake.tardigrade.io:7777","disqualified":null,"suspended":null},{"id":"121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6","url":"asia-east-1.tardigrade.io:7777","disqualified":null,"suspended":null},{"id":"12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S","url":"us-central-1.tardigrade.io:7777","disqualified":null,"suspended":null},{"id":"12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs","url":"europe-west-1.tardigrade.io:7777","disqualified":null,"suspended":null},{"id":"12rfG3sh9NCWiX3ivPjq2HtdLmbqCrvHVEzJubnzFzosMuawymB","url":"europe-north-1.tardigrade.io:7777","disqualified":null,"suspended":null}],"diskSpace":{"used":1718838891648,"available":1800000000000,"trash":1034754304},"bandwidth":{"used":474819004160,"available":0},"lastPinged":"2020-10-25T08:54:52.99929833Z","version":"1.14.7","allowedVersion":"1.13.0","upToDate":true,"startedAt":"2020-10-25T08:54:08.223529056Z"}
No 500s
Dashboard:

Can you try to stop and remove the container, remove the image and re-pull it and run the storagenode again?
Sometimes my rpi can’t download correct image for some reason (maybe too outdated docker ![]() ) and this trick solves 99.999% problems
) and this trick solves 99.999% problems
Also, I noticed that you bind the dashboard to the specific local IP, could you please use a standard 127.0.0.1 for test?
1 Like
I found the root cause, one of the databases is corrupted, I follow your guide and now it working fine!
(but how it was corrupted is an open question for me…)
Anyway, thanks for your quick reaction! I apologize for reporting the wrong issue.
1 Like
If you still use a network attached storage it could be a reason. I can’t say for sure.
However, I have had a database corruption on my Windows docker node (please, note that Docker desktop for Windows uses a SMB under the hood to bind disks) and never on my raspberry PI, even if it uses a USB to connect the drive (but I used a Geekworms extension board for that).
And I do not have a UPS for the rpi
This node is using local storage only, databases are separated into the SSD mirror, but it also local, so it really an open question for me what’s going wrong… it was my first database corruption during two years…
Perhaps those same additional points of failure played a role?
I can’t say that is an additional point of failure, I will monitor other nodes for the same issue, if I found the root case or any additional information I will post here.
1 Like
@Alexey I have one idea, tonight in our country we have a clock shift (one hour back), it can be a potential issue (this server also did it)
It’s unlikely - the storagenode and satellites uses UTC anyway. The corruption of sqlite can be reached by these ways:
1 Like
I hope that one day storjnode software will handle corrupted databases on its own, and fix them automagically… and it could report a warning also, so that the SNO could investigate what happened (as it could be the sign of an imminent disk failure for instance…).
3 Likes
Edit: Seems the firewall rule got messed up somehow and the port that was open was closed for some reason. Seems to be running fine now:
Same issue here on v1.16.1:
WARN console:service unable to get Satellite URL {"Satellite ID": "118UWpMCHzs6CvSgWd9BfFVjw5K9pZbJjkfZJexMtSkmKxvvAW", "error": "storage node dashboard service error: trust: satellite \"118UWpMCHzs6CvSgWd9BfFVjw5K9pZbJjkfZJexMtSkmKxvvAW\" is untrusted", "errorVerbose": "storage node dashboard service error: trust: satellite \"118UWpMCHzs6CvSgWd9BfFVjw5K9pZbJjkfZJexMtSkmKxvvAW\" is untrusted\n\tstorj.io/storj/storagenode/trust.
Node has been running fine for over a year and suddenly this occurs. Any ideas?
That satellite has shutdown so you can safely ignore that warning.
Same 2020-12-14T11:02:43.456Z WARN console:service unable to get Satellite URL {“Satellite ID”: “118UWpMCHzs6CvSgWd9BfFVjw5K9pZbJjkfZJexMtSkmKxvvAW”, “error”: “storage node dashboard service error: trust: satellite “118UWpMCHzs6CvSgWd9BfFVjw5K9pZbJjkfZJexMtSkmKxvvAW” is untrusted”, “errorVerbose”: “storage node dashboard service error: trust: satellite “118UWpMCHzs6CvSgWd9BfFVjw5K9pZbJjkfZJexMtSkmKxvvAW” is untrusted\n\tstorj.io/storj/storagenode/trust.(*Pool).getInfo:228\n\tstorj.io/storj/storagenode/trust.(*Pool).GetNodeURL:167\n\tstorj.io/storj/storagenode/console.(*Service).GetDashboardData:168\n\tstorj.io/storj/storagenode/console/consoleapi.(*StorageNode).StorageNode:44\n\tnet/http.HandlerFunc.ServeHTTP:2042\n\tgithub.com/gorilla/mux.(*Router).ServeHTTP:210\n\tnet/http.serverHandler.ServeHTTP:2843\n\tnet/http.(*conn).serve:1925”}