Yeah for sure in ADSL if you download a lot upload also get’s used more. Even though from my stats there should be still enough room - you never know.
I’m just a bit hesitant to get a new connection. It’s super good value for money, has never been off in the last 3 years… and even with netflix ultra HD / videoconferences for work (and now multiple as kids also do school stuff through VC) never any issues - even with 2MB to 3MB/s from storj ![]()
Yeah I hear you there I don’t always recommend spending money just for the sake of storj, If you were going to do it anyways then do it, If not there’s not much you can do about it. But since I got fiber I cannot go back to Adsl or cable. Nothing beats being able to upload without worrying about it slowing your internet connection. I cant go back. But you have a really nice NAS and Im sure its not your issue its for sure the internet connection.
Or you just could add the storagenode to the PRUNEPATHS in /etc/updatedb.conf.
Hello!.
How can I obtain this statistic or information from my node. Thank you!
Allthough a connection like that does not help I have a 100mbit up and down and have similar figures in Rotterdam
Look at the first link of “Popular Links” underneath post 1.
wasn’t meant in a bad way, just that with 30% successrate it doesn’t matter if it is a Ferrari, it still has flat tires… the question is why…
certainly shouldn’t be anything bad about that setup… tho it does kinda make me ponder if those are SMR drives which i will now look up xD
people seem to be all arguing back and forth, which is usually a good sign… no consensus just means not that bad xD so not SMR or whatever they want to call it these days…
256mb cache on those bastards tho… my rig feels cheap now…
maybe the system is so fast it stalls out the internet and so in a sense chokes itself…
i just ran my system at 200 max concurrent for barely 12 hours… i already been disconnected for 30 minutes because my time would sync correctly, i went from 1 in the 137sec catagory on reads to 20k… even that that was zfs scrubbing in the background… but still
basically nearly went through every configuration i could think of… also killed the lan internet tv… i mean the node by just maybe overloading the router or something…
@deathlessdd tho i’m sure it doesn’t help… that he has ADSL then even with my 400mbit fiber i’ve basically never gone past 40mbit sustained ingress… and i can upload at like 250mbit to the states from europa… last i checked anyways…
so its not a connection thing… tho maybe my iops on my drives are to low… checked my read writes earlier…
1600 a second… think it was nearly 1200 read and 300-400 writes good luck doing that on a slow raid setup, might partially be zfs tho because i still have a bad drive…
moved to 5 other drives and then i found one of those also threw me a damn error… working with old tech sucks, tho granted i should have performed indepth tests before i had the computer working for days for moving to the other drives…
where was i … right should be fine with his connection… xD
@fonzmeister hmmm that kinda makes one think its a regional issue… maybe
You gotta remember something though 40mbit download with a 16mbit upload turns into 25 Mbit download to a 6mbit upload. If theres alot of ingress and egress at the sametime what do you think happens to that connection, we had alot of ingress in the last months from saltlake…
I dont know the exact numbers but it’s not comparable to fiber at all. If its not one bottleneck its going to be another. He has a really good nas though so the bottleneck is going to be the internet connection before the hard drives become an issue.
@deathlessdd fine, so we will just fix his internet from getting to congested ![]()
try to put this into the bottom of your config.yaml @tankmann
you will find it in the storagenode folder
that should make it so it won’t overload the internet connection… duno if it will help, but its worth a try.
# Maximum number of simultaneous transfers
storage2.max-concurrent-requests: 10
i ran mine at 14 for a good long while… ran kinda great, but with all the deletions coming in atm, we get flooded, so i increased it to 20, which helps to allow almost everything… without me getting into the range of having 800 open connections, which even my 400mbit fiber doesn’t like to much
I have 100mbit fiber… running unlimited connections… a bitcoin core node, an ipfs public gateway, multiple other services… regular Internet usage along with increased data for Work-at-Home… multiple streaming services…
No problems whatsoever with regard to connection slow downs.
BTW…
I have nearly 900 ipfs connections right now:
$ ipfs swarm peers |wc -l
893
Almost all of them are IPv6
$ ipfs swarm peers |grep ip6 |wc -l
795
some of my network gear is old… maybe thats to blame… i am on 1gbit lan, but there are way to many local hops around the network and way to many crappy old routers i converted into switches to get everything hooked up… and no managed switches or QoS
i should get that tested tho… also one of the switched i moved to the server was discarded because it kept dropping a port, tho i have a theory that this is because of voltage differential between different gear and that the STP cable isn’t grounded like it should be…
its always something… i should really get back on task, so i can actually get some real redundancy on my node… been running upwards of a month now with basically just raid0 lol
tho in my defence the first 16 days i didn’t notice and then it tooks ages to move everything and then before i was done, one of the new used drives failed…
LIKE A PRO
Hi guys! I’m fairly new, joined the network recently.
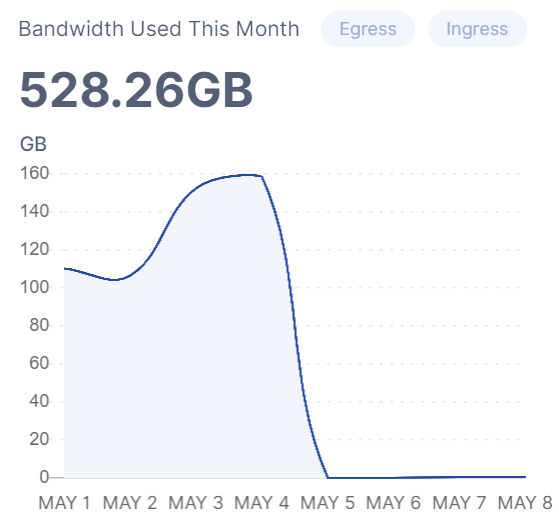
I might have to wait until the satellites finish vetting me, but for now the network doesn’t really seem to favour my node. Ingress at around 150GB per day until May 4th, then sudden drop to <10GB per day which the node hasn’t recovered from until this day (May 8th). Other operators report similiar behaviour on the forum and there has something been going on with the saltlake satellite recently, maybe new testing patterns?
Anyway, my success rate has been quite low. A RAID 6 expansion that was slowing down my node might be one of the reasons. Lets see how my node evolves in the next weeks!
Hardware : Synology RS1219+ (Quadcore Atom C2538, 16GB RAM), 6x 10TB WD White Label in RAID 6, 10GbE
Bandwidth : 10Gbit synchronous
Location : Zurich, Switzerland
Version : 1.3.3
Uptime : 16h, joined the network 8 days ago
========== AUDIT ==============
Critically failed: 0
Critical Fail Rate: 0.000%
Recoverable failed: 0
Recoverable Fail Rate: 0.000%
Successful: 13
Success Rate: 100.000%
========== DOWNLOAD ===========
Failed: 0
Fail Rate: 0.000%
Canceled: 5
Cancel Rate: 1.408%
Successful: 350
Success Rate: 98.591%
========== UPLOAD =============
Rejected: 0
Acceptance Rate: 100.000%
---------- accepted -----------
Failed: 0
Fail Rate: 0.000%
Canceled: 1376
Cancel Rate: 58.553%
Successful: 974
Success Rate: 41.447%
========== REPAIR DOWNLOAD ====
Failed: 0
Fail Rate: 0.000%
Canceled: 0
Cancel Rate: 0.000%
Successful: 0
Success Rate: 0.000%
========== REPAIR UPLOAD ======
Failed: 0
Fail Rate: 0.000%
Canceled: 23
Cancel Rate: 39.655%
Successful: 35
Success Rate: 60.345%
========== DELETE =============
Failed: 0
Fail Rate: 0.000%
Successful: 228
Success Rate: 100.000%
@cubesmi
not totally informed here, but from what i understood, there was some issues with one of the satellites, and while being vetted for atleast the first month, the node will mainly receive test data from that particular satellite… so its very possible that people in the vetting process could see issues, from that…
your cancelled upload rate is also kinda high… would recommend seeing if you cannot improve upon that… due to latency, i think i go through that
these are ofc my opinions and not financial advice, to be taken with a glass of water and all that…
and from what i’ve seen thus far, the successrate varies by storj network activity, local disk or server usage… aside from that it doesn’t really change that much… even if other stuff can affect it.
The “issues” only had impact on calculation and reporting of used space. That was slightly delayed. But that shouldn’t impact core functions of the node including vetting and customer traffic.
As for the success rate, latency in the internet connection can also be a factor. As a result location and internet infrastructure between you and the customer could have an impact. That’s a factor you usually can’t do all that much about.
Thanks @SGC and @BrightSilence !
Still an interesting pattern since I don’t seem to be the only one barely getting any ingress from saltlake since May 5th.
The network latency, at least for the European satellites, is okayish:
--- saltlake.tardigrade.io ping statistics ---
100 packets transmitted, 100 received, 0% packet loss, time 99006ms
rtt min/avg/max/mdev = 144.984/145.812/148.219/0.649 ms
--- satellite.stefan-benten.de ping statistics ---
100 packets transmitted, 100 received, 0% packet loss, time 99117ms
rtt min/avg/max/mdev = 25.208/38.069/118.376/11.188 ms
--- asia-east-1.tardigrade.io ping statistics ---
100 packets transmitted, 100 received, 0% packet loss, time 99109ms
rtt min/avg/max/mdev = 269.166/269.836/271.499/0.847 ms
--- us-central-1.tardigrade.io ping statistics ---
100 packets transmitted, 100 received, 0% packet loss, time 99102ms
rtt min/avg/max/mdev = 115.880/116.194/117.401/0.440 ms
--- europe-west-1.tardigrade.io ping statistics ---
100 packets transmitted, 100 received, 0% packet loss, time 99091ms
rtt min/avg/max/mdev = 15.220/15.894/17.229/0.382 ms
--- europe-north-1.tardigrade.io ping statistics ---
100 packets transmitted, 100 received, 0% packet loss, time 99101ms
rtt min/avg/max/mdev = 40.219/40.958/44.190/0.620 ms
--- 8.8.8.8 ping statistics ---
100 packets transmitted, 100 received, 0% packet loss, time 99124ms
rtt min/avg/max/mdev = 2.227/2.917/5.442/0.440 ms
Since my RAID 6 is expanded now I expect some better disk latency now… lets see!
going to hook up 4 extra drives today… running raidz1 so going to have 2x raidz1 vdevs of 4 drives
to help me get my IO and latency even better… often i think it’s because i work to much on the server… been shuffling data around like crazy the last few months…
hopefully no more dying drives for me in the near future and the server can keep up…
also just cloned my own computers SSD onto a HDD so now the SSD is going into the server as SLOG / OS drive and then the old bigger SSD will become my dedicated L2ARC
then i’m going to start to try and boot my own computer over the network from the server instead of having an ssd mainly sitting idle…going to be interesting
raid6 is reliable, but it’s really not amazing in high IO write if memory serves.
reads and write sequentially can get pretty amazing, but you might still be working with something like single or double disk sustained Read Write performance.
you might be better off running a stack of mirrors, sadly that makes it expensive, but its with good reasons many enterprise solutions work with nested raid 10
nice and easily approachable, each to manage, upgrade and great performance… but cost is higher…
This is more likely a reporting issue than actually no traffic. Unless your node is suspended or disqualified on that satellite it should have gotten quite a bit of ingress during those days.
Latency to the satellites doesn’t matter. It’s much more important to have a good latency to the customers, which are all over.
i take it i’m not the only one seeing this…???
looks like my performance testing is over for now… might record it or find something putting a similar strain on the system… would be nice to actually be…well there’s an idea
a node simulation, doing nothing aside from stress testing the system… or like a benchmark.
You can take a look on storj-sim
thanks you are a lifesaver … O.o so i can just run my own storj cloud… well that is certainly interesting… was kinda hoping on just some basic SNO load testing…but i kinda blew out one of my drives during the night… or something… so not really able to go full tilt right now anyways…
looks very interesting, but looks like a lot of work to make it do what i wanted it to… but maybe, when i get around to daring enough try to go full tilt again.