My service in windows 10 is getting shutdown because of broken file / folder
2022-02-21T23:50:15.198+0100 ERROR piecestore:cache error getting current used space: {"error": "CreateFile I:\\Storj\\Shared\\blobs\\pmw6tvzmf2jv6giyybmmvl4o2ahqlaldsaeha4yx74n5aaaaaaaa\\7f/dcb6nelqogqoxlrvwictbbsiwkjxzq5ecx26bhr7qww4sdq6wa.sj1: The file or folder is damaged and cannot be read", "errorVerbose": "CreateFile I:\\Storj\\Shared\\blobs\\pmw6tvzmf2jv6giyybmmvl4o2ahqlaldsaeha4yx74n5aaaaaaaa\\7f/dcb6nelqogqoxlrvwictbbsiwkjxzq5ecx26bhr7qww4sdq6wa.sj1: The file or folder is damaged and cannot be read\n\tstorj.io/storj/storage/filestore.walkNamespaceWithPrefix:788\n\tstorj.io/storj/storage/filestore.(*Dir).walkNamespaceInPath:725\n\tstorj.io/storj/storage/filestore.(*Dir).WalkNamespace:685\n\tstorj.io/storj/storage/filestore.(*blobStore).WalkNamespace:284\n\tstorj.io/storj/storagenode/pieces.(*Store).WalkSatellitePieces:497\n\tstorj.io/storj/storagenode/pieces.(*Store).SpaceUsedTotalAndBySatellite:662\n\tstorj.io/storj/storagenode/pieces.(*CacheService).Run:54\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2.1:87\n\truntime/pprof.Do:40\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2:86\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:57"}
2022-02-21T23:50:15.206+0100 ERROR services unexpected shutdown of a runner {"name": "piecestore:cache", "error": "CreateFile I:\\Storj\\Shared\\blobs\\pmw6tvzmf2jv6giyybmmvl4o2ahqlaldsaeha4yx74n5aaaaaaaa\\7f/dcb6nelqogqoxlrvwictbbsiwkjxzq5ecx26bhr7qww4sdq6wa.sj1: The file or folder is damaged and cannot be read", "errorVerbose": "CreateFile I:\\Storj\\Shared\\blobs\\pmw6tvzmf2jv6giyybmmvl4o2ahqlaldsaeha4yx74n5aaaaaaaa\\7f/dcb6nelqogqoxlrvwictbbsiwkjxzq5ecx26bhr7qww4sdq6wa.sj1: The file or folder is damaged and cannot be read\n\tstorj.io/storj/storage/filestore.walkNamespaceWithPrefix:788\n\tstorj.io/storj/storage/filestore.(*Dir).walkNamespaceInPath:725\n\tstorj.io/storj/storage/filestore.(*Dir).WalkNamespace:685\n\tstorj.io/storj/storage/filestore.(*blobStore).WalkNamespace:284\n\tstorj.io/storj/storagenode/pieces.(*Store).WalkSatellitePieces:497\n\tstorj.io/storj/storagenode/pieces.(*Store).SpaceUsedTotalAndBySatellite:662\n\tstorj.io/storj/storagenode/pieces.(*CacheService).Run:54\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2.1:87\n\truntime/pprof.Do:40\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2:86\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:57"}
2022-02-21T23:50:15.296+0100 FATAL Unrecoverable error {"error": "CreateFile I:\\Storj\\Shared\\blobs\\pmw6tvzmf2jv6giyybmmvl4o2ahqlaldsaeha4yx74n5aaaaaaaa\\7f/dcb6nelqogqoxlrvwictbbsiwkjxzq5ecx26bhr7qww4sdq6wa.sj1: The file or folder is damaged and cannot be read", "errorVerbose": "CreateFile I:\\Storj\\Shared\\blobs\\pmw6tvzmf2jv6giyybmmvl4o2ahqlaldsaeha4yx74n5aaaaaaaa\\7f/dcb6nelqogqoxlrvwictbbsiwkjxzq5ecx26bhr7qww4sdq6wa.sj1: The file or folder is damaged and cannot be read\n\tstorj.io/storj/storage/filestore.walkNamespaceWithPrefix:788\n\tstorj.io/storj/storage/filestore.(*Dir).walkNamespaceInPath:725\n\tstorj.io/storj/storage/filestore.(*Dir).WalkNamespace:685\n\tstorj.io/storj/storage/filestore.(*blobStore).WalkNamespace:284\n\tstorj.io/storj/storagenode/pieces.(*Store).WalkSatellitePieces:497\n\tstorj.io/storj/storagenode/pieces.(*Store).SpaceUsedTotalAndBySatellite:662\n\tstorj.io/storj/storagenode/pieces.(*CacheService).Run:54\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2.1:87\n\truntime/pprof.Do:40\n\tstorj.io/storj/private/lifecycle.(*Group).Run.func2:86\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:57"}
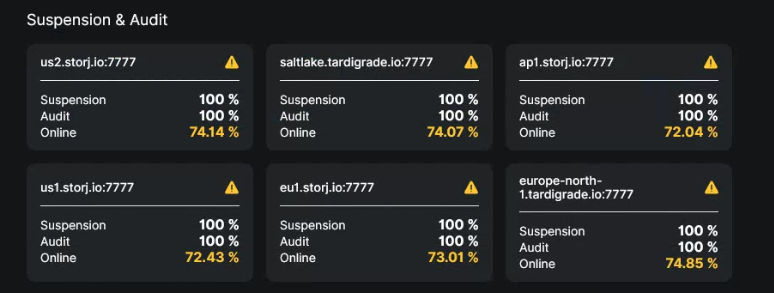
is there any chance to recover node with 20% uptime now ? And how to try resolve the problem.
Hdd seems to be good.
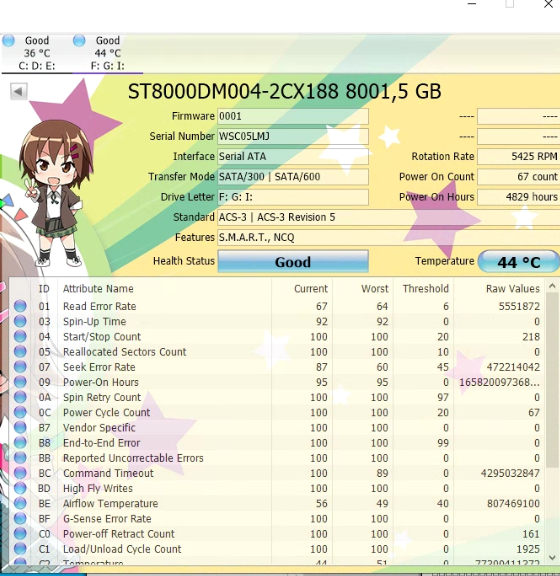
Any advice what to do now ? Thanks