Just check your audit score. If it is fall below 0.6, your node will be disqualified on that satellite. However, it can work with others.
1 Like
I just thought it would be nice to update you with the latest stats:
PS C:\Windows\system32> ((curl http://127.0.0.1:14002/api/dashboard).Content | ConvertFrom-Json).data.satellites.id | %{
"$_"; ((curl http://127.0.0.1:14002/api/satellite/$_).Content | ConvertFrom-Json).data.audit}
>>
12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs
totalCount : 7600
successCount : 7600
alpha : 20.000000000000014
beta : 0
score : 1
12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S
totalCount : 15996
successCount : 15356
alpha : 19.99999999999995
beta : 8.98331247762025E-212
score : 1
118UWpMCHzs6CvSgWd9BfFVjw5K9pZbJjkfZJexMtSkmKxvvAW
totalCount : 23361
successCount : 22308
alpha : 19.99999999999995
beta : 9.68381719968422E-25
score : 1
121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6
totalCount : 11526
successCount : 11523
alpha : 20.000000000000014
beta : 2.82971398224556E-248
score : 1
PS C:\Windows\system32>To me it seems fine. Not a huge difference in terms of numbers since the last time I posted, maybe the traffic is not that high currently?
regarding the data which are not found: will the system eventually stop looking for them? Will I ever get rid of all those lines in the logs showing the issue?
Thanks
It looks like your node is fine. And those missed pieces never been on your node. Perhaps consequences of fixed bug.
@Alexey Thank you for your message.
I was wondering: there is no way to fix my dashboard then? It still shows as if my node was completely full, but it is not the case. I am wondering what does the storj network “think” of my node. Do satellites think that my node is full? Or are they aware that there is still almost all the harddrive that could be used? I have dedicated 800GB out of 1000GB to storj. Out of those 800 GB only 100 GB are used.
Is it because there is no traffic on the network or is it because there is something wrong with my node?
If my node is healthy, as the stats suggest, is there any way to correct what the dashboard is showing?
Thank you.
How many allocated and how many free space do you see on the dashboard?
Can you run a CLI dashboard?
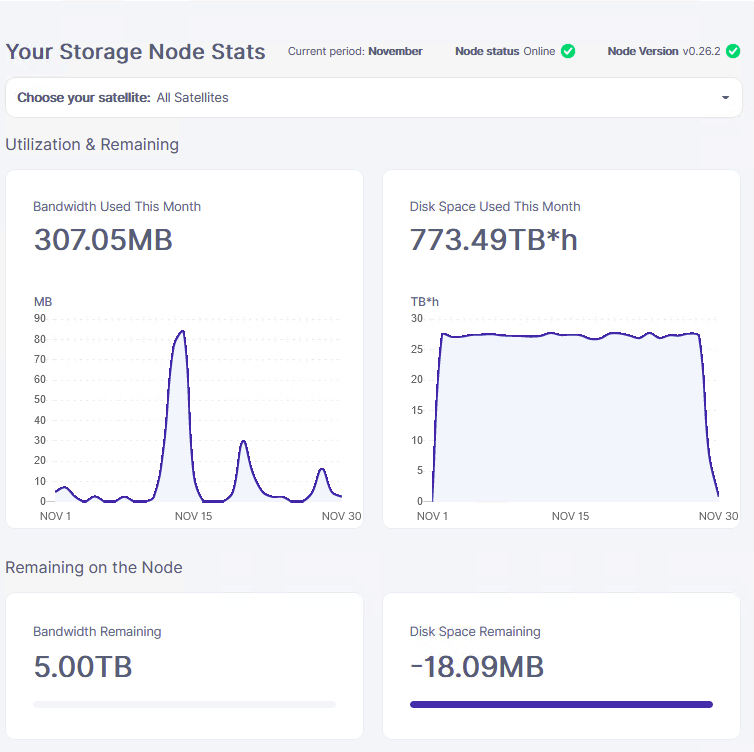
What are the commands I need to run on the CLI? I only have the ones we used when it was running on docker.
@Alexey have you got any suggestions for me? Will I have to live with my broken dashboard? And more important, what are satellites thinking of my node: is it full or empty? 
The satellite will treat your node as full. You can increase the allocation (if you have enough space) and you will see the zero or even plus 
I do not know what you mean. I have dedicated 800 GB to Storj, but, by opening the properties of the disk it is filled by 100 GB only. Still the dashboard thinks that my HDD is completely full.
This is not true. Since I have set 800 GB for storj, and only 100 GB have been used, 700 GB should still be available for use.
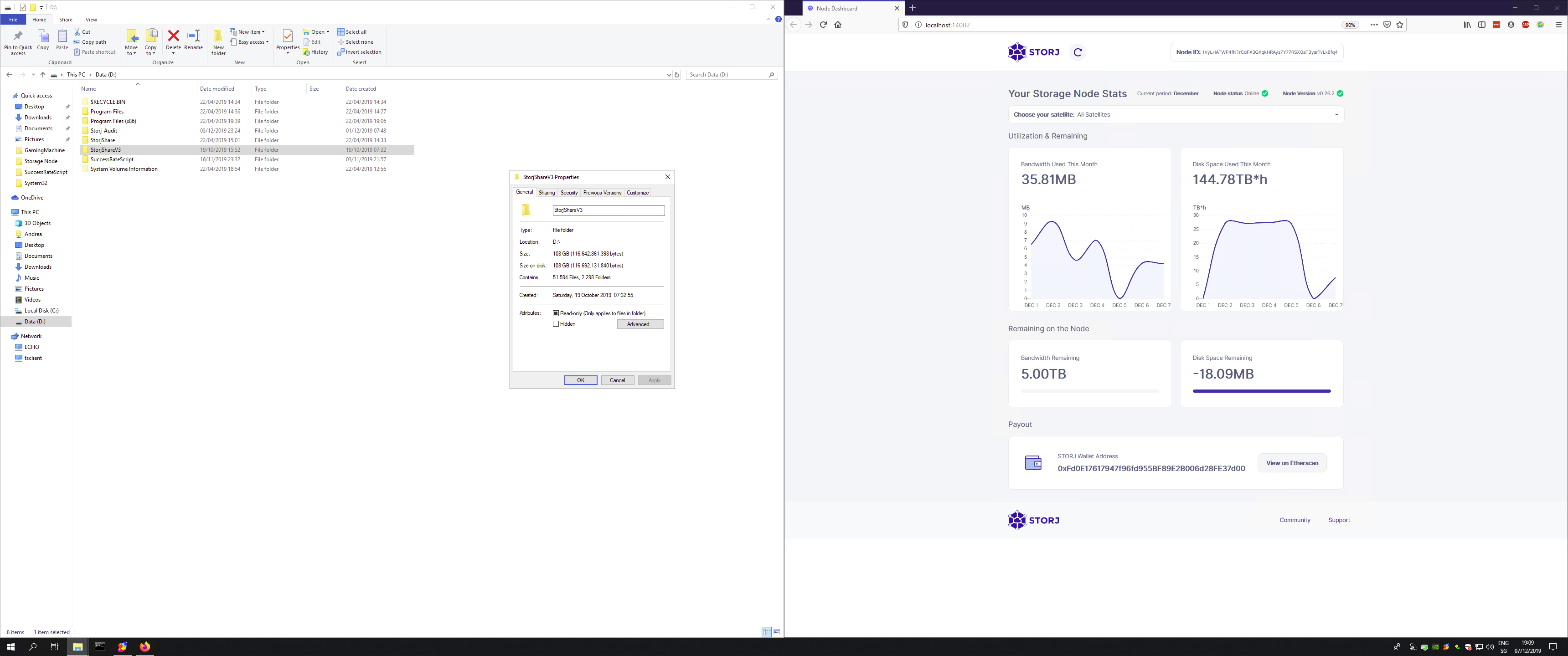
In order to complete the information at your disposal, please find here below a printscreen of the HDD properties:

Thanks.
I mean, if you increase the allocation in the config, the negative number should disappear.
But yes, your usage stat for space will be broken until this data would be deleted by customers.
The other option is start from scratch and lose your escrow for this identity.
I hope that the graceful exit will be released soon and you can exit the network with that node and start with a new one without losing escrow. The tradeoff is your new node will gain a reputation from ground.
I would disable indexing for that drive, if I were you.
Not very pleased, but thanks for the answer. One more question though: the HDD is of 1 TB. What if I tell the storj network that I have 700 GBs more (a total of 1.7TB) even if it is not true?
Thanks!
It doesn’t help, the previous stat for space usage was lost because of wrong path in the storagenode configuration after migration from the docker
The storagenode checking the available space on start, it takes the allocation, subtracting the usage (by the stat from DB) and comparing with available space. If you allocated more than available, it will reduce the allocation to the actual value. But since your stat is wrong it still will think that you have used such amount of data even if this is not true anymore. This is consequence of losing the correct stat…
1 Like
Hello @Alexey and happy new year.
I did not do anything on the node for the moment being: it still is the same node.
I have seen that today the amount of available space on the dashboard is of about 14GB
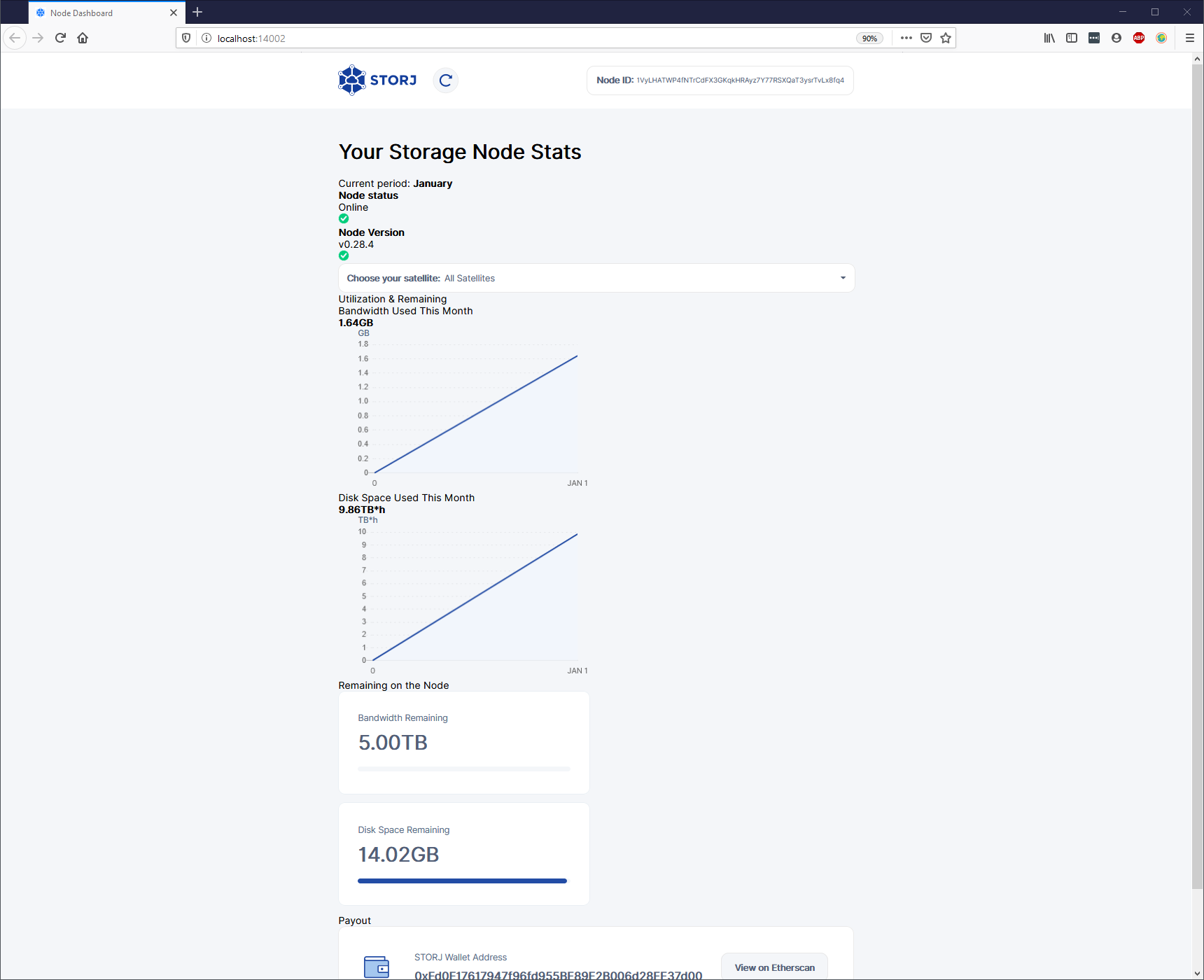
Which is somehow better than the previous value of -18.0 MB. This makes me hope for the best… therefore a few questions for you.
Is that the result of the garbage collector doing his job? Will this help my node to get realistic values over time?
Since tomorrow I will have some free time I would like your help in deciding what to do, also because I have now 3x2TB drive which I could dedicate to the cause (current drive is 1TB only). I have at least 3 options in my mind:
-
Kill the current node and install a new node on a 2TB drive.
-
Keep the current node on the existing 1TB drive and install a new node on a 2TB drive.
-
Move the current node on a 2TB drive.
The two more drives may be used in the future once the node is full or may not get used at all (given the restrictions we have), which is a pity as it seems a waste of resources.
As usual thanks a lot for your help.
I would recommend to refresh the dashboard with Ctrl+F5
More like yes.
if you would like to kill the node, you will lost all related held amount. So it doesn’t looks like an option.
Our recommendation is still the same - better to have each node on own HDD, unless you have a RAID1, RAID10, RAID6 already.
You can move data to a bigger HDD, if you want or create a new node on this HDD, it’s up on you.
The constraint still the same - all nodes behind the same /24 subnet of public IPs are treated as a one node for uploads and downloads, and as a separate for audits and uptime checks.
Thanks for the answer.
Are you kidding me? The main issue is that the dashboard is showing either negative space or way less space available than what it is available (ca. 800GB of dedicated space, used < 100GB, free should be at least 700 GB). But we have already analysed this in the messages above. I do not see how this should be solved by refreshing the page (I refreshed it in any case, I believe the node has received more data now and the available space has decreased to a few KB).
Either it is an option or it is not, please decide… ![]()
I think I will go with option 3, that is to move the current node to the bigger HDD. I have checked the following page but it does not cover my case, since I am not moving to a new computer, I am just moving the data to another folder.
I believe I will:
-
Stop the node
-
Copy/Paste the folder to the new drive
-
Modify the existing configuration config.yaml file which is, in my case, held at the following PATH: C:\Program Files\Storj\Storage Node with the following information:
New path: will change the unit letter from D: to E:
New size: will change the available space from 800 GB to 1600GB -
Cross fingers
-
Restart the node
Thanks
1 Like
I know, I suggested you refresh the dashboard because it looks weird ![]()
I remember about the problem with lost stat, refreshing dashboard doesn’t help to solve this problem, only the weird view.
It’s option. Just when the graceful exit will be enabled you can activate it and return your escrow and start with a new node without losing the held amount.
In case of removing the node without graceful exit, the escrow will be used to recover lost pieces to other nodes.
Hi @aseegy.
I did move my node from a 1TB drive to a 2TB once. Copying so much data takes hours and I wouldn’t recommand doing it while the node is offline as it’s not supposed to be off-the-grid: its reputation may badly suffer from it.
On linux, I used rsync to synchronize everything from the source drive to the target drive, twice (took roughly 5 hours, then 20 minutes).
Then I stopped the node, ran rsync one last time to grab the latest changes (took 2 minutes) and then restarted the node, targetting the new drive.
I’m not sure what could be used on Windows instead of rsync, but I think you should search for a similar approach to cut down your node’s downtime to a minimum.
Hi there and thanks for your message.
In this specific case I only have 100GB to me copied, so no biggie. Still you are right that it would be a good decision to use something safer instead of copy/paste.
In windows I know it is a good option to use “robocopy”. Still I have never used it and I do not know its syntax. I know there is microsoft documentation available, still it is one thing to know how to use a command and another to learn how it works.
I might give it a try, maybe with some test folders and then go for it.