Did a quick glance around the forums and docs, but couldn’t find anything relevant, so asking here. I’m trying to understand the factors that affect the download rates of buckets.
I switched from Backblaze to Storj and I really like Storj and the lower cost, but the download rate has been gradually eating up my cost savings, so I’d like to manage it, if I can.
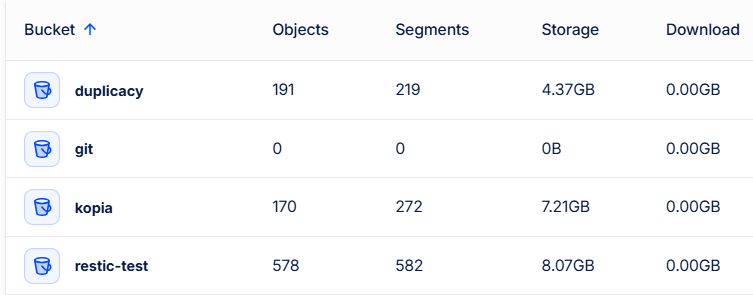
As you can see in the linked image, bucket #1 has the highest rate of download, while bucket #3 has considerably less download despite being 4x larger and having 4x as many objects as bucket #1.
Bucket #3 is ~30% smaller and has similar data to bucket #1, but it has less than 3% of bucket #1’s download rate.
So, I assume that size and number of objects is not a primary factor in download rate, but that changes in files may be. I can confirm that the data in bucket #1 is more dynamic than that in buckets #2 or #3. Is this why the download rate is so high? If not, why?
Finally, Is there anything I can do at source to lower download rates? The data in bucket #1 is a daily system backup on a NAS and it is backed up to Storj by Synology HyperBackup in a .hbk file , as are all the other buckets.
I can’t speak to your specific setup, but in general for backups there’s a couple large classes of behavior:
If you’re only syncing files (only keeping the most recent versions) then the backup can compare the loose files directly. Usually that’s easy - if it can see the size and modification time of every file: in general it doesn’t have to download any full files (since most individual files don’t change).
If you’re keeping versioned/timestamped backups-over-time… then often each backup is collected together into a large archive (what HyperBackup may be doing with the .hbk file). If that file always has the same name… then all the program-talking-to-Storj can see is that the file changed (size, mod time)… so to know what changed (to hopefully only sent the differences) it often has to download a lot of the file first.
To get around that, often backup programs can either:
Be configured to have different filenames every time (like a timestamp in the filename). This may use more space… but every time the backup runs it doesn’t have to download anything.
Be configured to save incremental/synthetic-full files - again with different filenames - and each of those incremental backups are small.
I know that doesn’t directly help you - just saying your backup program may have options you can change so every run is sending a new filename, and usually it will be a small file (incremental), and the backup program won’t have to download almost anything.
It often looks something like “make a full backup (new filename, but large) every Sunday, then every other day make an incremental backup (compared to that full file: new filenames but small)”.
@Roxor is correct.
So, you may also consider to use other backup tools, which doesn’t download much (only the index with hashes) when they do a snapshot, like restic or Duplicacy or HashBackup and similar.
Please note, Kopia has issues with their implementation, because they uses the prefixes without a ending delimiter and this could produce errors when the number of objects will grow up to 100k and you use the paths encryption (it’s by default), but you may bypass that flaw in their implementation by:
Thanks, but I’m not interested in other backup apps. I have a solid 3-2-1 backup and the storj is the copy of last resort. Using HyperBackup from my NAS is straightforward and effective.
Thanks for the reply. The process for the backup in question is a daily rsync from a linux desktop to a NAS, then the NAS backs up to storj using Synology’s Hyperbackup application.
Re: your #2, ALL of my storj backups are in .hbk format with versioning. It would seem then, that if your #2 were the issue, ALL of my backups would have excessive downloads, but, as you can see from the linked screencap, only the one backup does.
I’ll take a closer look at the rsync from desktop to NAS. That data should be relatively static, but if the rsync command is capturing a lot of transient files, that might be part of the problem.
HyperBackup does periodic time limited test restores, depending on nature of data and layout some datasets may manage to downloads more data than others. That’s not the only reason.
It is designed with entirely different goals in mind: it must work on seriously resource constrained hardware. All engineering decisions were made to support this goal.
There are no benefits of using HyperBackup: you get vendor lock-in, instability (try to cancel backup in progress — see how it takes 15 minutes to finalize? What is it doing so important? Now think what will happen if you gent network interruption that would not wait 15 minutes? Correct, data corruption, and you would need to star from scratch losing version history). HyperBackup and other Synology “apps” are there to sell you NAS. That’s it. This is their only goal. Becuse when you try to use these apps a variety of cans of worms uncork themselves. You are in the middle of enjoying one of them, a small one, now.
Don’t trust marketing gimmick of a consumer electronics company to safeguard your data. Use backup tools designed by people who know what they are doing and whose focus is the backup tool in question. There plenty of high quality tools available. Duplicacy, restic, borg to name a few.
HyperBackup does periodic time limited test restores, depending on nature of data and layout some datasets may manage to downloads more data than others.
That a possibility; I have integrity checks scheduled monthly, but this specific bucket rate has been on a relatively upward trend for 12+ weeks now. It also doesn’t explain the large rate differences between similar datasets on similar schedules. I’ll monitor it a bit more closely to see if it changes.
Re: alternative backup applications. I’ve been using Hyperbackup to backup my NAS for almost 9 years. I understand it’s limitations and proprietary nature. It is imperfect, yes, but it’s never failed me in backup or restoration. I’ve used duplicacy, borg and other ways to accomplish my NAS backup. Some are better at some things, not so much at others. Each has their own set of warts.
My time is valuable; Most alternatives require more effort to install, manage, and monitor. HB is tightly integrated into the Synology ecosystem, minimising complexity and management. It handles encryption, compression, schedule, retention policy, backup rotation, versioning, validation, and deduplication within a single package and offers built-in support for a wide range of destinations and cloud services.
HB is optimised for Synology hardware, which means better compatibility, easier updates. HB will backup and restore not only user data, but also Synology application data, system settings, and package configurations and allow me restore individual DSM packages, along with their configs and data directly. That kind of flexibility in a single, integrated package is much more than just a “marketing gimmick”. I don’t buy Synology for their backup app; I buy them for their excellent quality, great OS, plug-and-play capabilities, excellent features, and reliability. I did DIY NAS for several years; once I switched to Synology, I never looked back.
While the packages you prefer to use offer some advantages for some users, HB is a good fit for users who prioritise and value Synology integration, simplicity, easy management, etc. I’m not looking for a new backup application; I’m just trying to understand curious variations in download rates I see using Storj. It’s important to me because it costs me money. I switched to Storj purely because it saved me money, but these downloads rates are eroding that savings. Telling me to change my backup application is not a solution. If I need to change my backup application in order to enjoy savings offered by Storj, I might as well switch back to Backblaze.
Thanks for the responses and possible explanations. I’ll monitor this more closely and see what happens over the next couple of months.
It is curious. In the end if an app asks to upload… Storj accepts it. If an app asks to download… Storj provides it. So I’d expect you’d see the same behavior with any S3 provider - HB is going to do the same thing with all of them.
If you’re wondering why HB has different network behavior with different backup jobs - maybe HB has a users forum or Discord too?
My experience:
I have been using Syno NAS and its HyperBackup since 2016, multiple units in my home (I’ve been runing DS216 since 2016 until now, non-stop, still with the same 2 WD RED HDDs, no single failure since I turned it on for the first time) and number of my relatives, with some of them we perform cross backups for each other. I tested numerous times if the backup is recoverable, I recovered random files here and there, a few TB in total, and never run into any troubles.
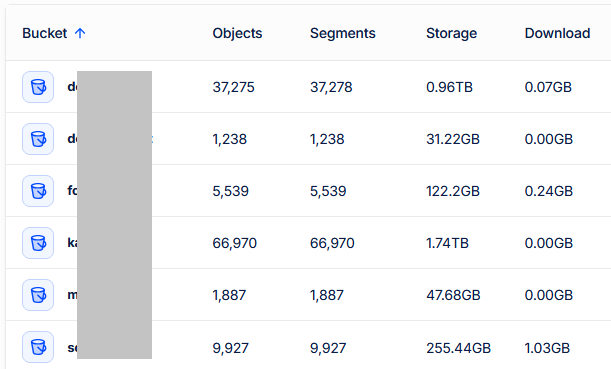
With storj S3 I have 6 buckets, one for photos, one for video-camera recordings, one for documents (doc, txt, pdf…) one for zip archives, etc. It means some buckets content is only adding, never changing or deleting content, whereas others will perform many deletes or updates. Size of the individual buckets are between a few GB up to something little over 1 TB. This is current year stats:
In every Hyper Backup set I have Integrity check turned on, once per month. Therefore the downloads are based on the data nature and its changes and the Integrity check. If it is supposed to perform Integrity check, it necessarily needs to download something, otherwise it would be actually checking nothing. I never seen any excesive D/L, usually it is a few megabytes per month, I saw it reached 1GB once, when I was doing significant change in some datasets. And yes, the download size does not follow the bucket size:
Conclusion: I checked current year billing, and highest monthly fee I paid for Egress (download) was 0.01 $, soooo I don’t care…
If you wish to investigate further, please provide some details, how is you HB set, what is size of the dataset, whether perform Integrity check often? Like this
PS. I’m not on Synology side any further because they lost their mind and stopped supporting any HDDs and SSDs but their own overpriced lower quality HDDs/SSDs. That’s ridiculous and no-go.
HyperBackup dedupes automagically by default. afaik, there are no settings or options in Hyper Backup’s configuration to disable it. It’s built-in to all backup tasks.
Thanks for that perspective. Our settings are essentially the same. But, I still think I need to look more closely on my end. I am starting to think this may well be related to dataset changes, either at source or, possibly, with HB versioning changes. If I look at the download rate history over the past 6-12 months, it is relatively low and stable until a few months ago. That suggests to me that some changes made then have caused this.
QUESTION: Am I correct in thinking that a large deletion of data from a storj bucket would result in a spike of the download rates?
No. The deletion operation doesn’t produce egress, they are separate operations (DEL vs GET).
The egress usage can be produced solely on the client’s side. Either by the tool or if you generated a shared link and gave it to someone or published somewhere.
Additionally, because the data are uploaded in 52MB chunks, and when the data are encrypted by HB and/or compressed and/or versioning is turned on, I would think HB will need to download some pieces of previous versions or compressed pieces it does not have on file locally, so it can encrypt or compress the old files and new together back to the chunk and upload it again. But I’m not completely sure if it works like this.
Turning on Logging may help here, on the Settings card.
feel free to use free Synology Hyper Backup Explorer on any PC to browse/restore HB backups even if you get rid of all Syno NASes
I guess it needs to clean up thousands of chunks it created to be uploaded to backup target, whereas the process is running with very low priority, to leave user’s processes more power.
Did that happen to you? From my experience, when connection between source and target got interrupted or power outage happened on the target side, it waited for some time and then went to Suspend mode. When I switched it on again, it caught up and started where it left off. Haven’t seen any corruption.
I am using Hyper Backup and have noticed that when rotation (Smart Recycle) is enabled and a version is deleted, files are somehow downloaded and uploaded. I have no idea what exactly is happening and why. This has nothing to do with Storj or buckets, just the logic behind Hyper Backup.
Not helpful. You’ll have to abandon your version history.
It’s phenomenal the mental gymnastics people are willing to engage in to protect their sunk cost and to avoid admitting that it’s synology marketing that is very good, nothing else.
Yes, multiple times. I ran backup in a loop and randomly interrupts network few times a minute. Corruption occurs 100% within few hours. I’ve reported this bug (along of many other bugs) to synology and while they workaround a few other bugs (never actually fixed) this one remained unfixed up until I abandoned synology altogether and stopped tracking. I bet you it’s still broken.
You see, you are basing your expectations and perspective on the state of affairs 10 years ago. Then SYnology was a very different company. It was engineering company that was innovative and eager to fix issues. I played along and helped them triage and fix a bunch. Today the picture is different. It’s a marketing money making machine where engineering is treated as a collateral damage. And code quality plummeted further, even though nobody believed that was possible.
Exactly my motivation to have tried synology. I too fell victim of their marketing department and empty promises. Turned out, babysitting it was taking way too much time, and I was becoming a “synology expert” on various forums. The opposite I wanted to acomplish. And then, alternative “just worked”…
IN fact, you are here discussing issues with Synology… soo… That’s quite a lot of effort for “set it an and forget it” appliance. But it’s not your fault, their marketing team is VERY good.
This is marketing speak. IT’s meaningless. NAS is a NAS. How can any software be “optimized” for it? It’s an oxymoron.
You can continue using hyper backup to backup system state. But not your data. Because you shall not trust synology software skills. Because see my posts above.
Oh my. No comments here. You are wrong on every point here. See my posts above.
I spent 2-3 years with synology, Then I threw in a towel and DYI the nas, and haven’t touched it since.
Granted, if you only use the one usecase marketing material describes don’t deviate anywhere, and don’t use 99% of functionality – it will probably work. Because otherwise they would not be able to sell it.
I’m actually telling you to change your storage appliance, let alone backup application. Yes, it’s that bad.
Again, I don’t blame you, but you should not believe marketing and especially when data integrity and reliability is concerned – you shall do what’s right, and not what marketing departments tell you. I have nothing to gain here – but I hate to see you lose data because you believed them and entrusted morons with your data

{kind=link}