does this mean dataloss?
No. Losing least profitable nodes won’t affect the network. The others will take over missing pieces and eventually compensate for the drop in available free space.
“Cheapest” and “most reliable” I think they refer to distinct nodes. ![]()
If you refer to cheapest runing costs, than yeah, you’re right, but not cheapest hardware.
Cheapest to run. Cheapest in terms of profitability.
And with “cheapest” and “most reliable” I meant that there are variables like “running cost (or profitability?)” and “reliability”. So then you can put a point for each node on a graph where axes are those variables. Then some area of it will be nodes that are going to outlive others.
(^ more or less, don’t want to think about it more at this point)
How can you be sure?
I am not 100%, but that’s how the network works. Some nodes go away, either gracefully or abruptly, then other nodes download/restore pieces stored on them. In order to lose any data the node drop rate would have to be huge. And even if it happens to be huge, it won’t be huge overnight. So no data loss unless you totally forget about it and Storj Labs nukes the project. But that would be something you should be notified about to have time to relocate your data safely. And for now we have no indication that things could go south out of the blue.
What giftcard was that? In Europe a €50 giftcard costs exactly €50 and it’s the same for most giftcards in the US. I only saw some giftcards where they add $0.20 or $0.25 per giftcard like BestBuy or Home Depot. Nowhere could I find any giftcard where you pay $5 more than the face value. Some giftcards even give you 1 or 3% rewards.
It works if the network is truely decentralized, but in fact when someone like this guy www.th3van.dk goes offline then…
So he’s running 107 nodes with 10TB each and he can afford them for 30 USD per month. He probably will have to shut them down soon. It’s going to be interesting, but if he does a graceful exit it shouldn’t hurt the network too much.
Y should he shut them down?
The more nodes, the more efficient i would assume.
Or… has negociated special payouts. Storj pays him more, and he runs a profesional data center long term. ![]()
This is just an asumption, don’t take it as a fact.
it also can be his own datacenter
It doesn’t matter. Even if these nodes disappeared over night, there would be no loss.
For the calculation I assumed ALL segments are at the repair threshold to get the worst case scenario. In reality they are spread out between 54 and 80 pieces, of which 29 need to be available to recover the segment.
But in order to make it show data at all, I had to drop the repair threshold in my example to 50.
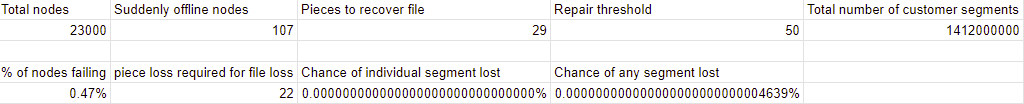
With 107 nodes disappearing at once in this scenario, there is a 0.000000000000000000000000004639% chance that ANY segment gets lost at all. Pretty good margin away from the 11 9’s of durability Storj promises.
Feel free to do your own calculations.
In addition to my above calculation. Storj monitors piece availability for each segment stored on the network. When it falls below the repair threshold, repair workers kick in to retrieve 29 healthy pieces, recreate the encrypted segment and generate enough new pieces to bring the total back up to 80. I believe the repair threshold is set to 54 at the moment. The lowest availability of segments on any customer satellite is 51.
Only healthy pieces are counted towards that availability. Pieces are marked as unhealthy when nodes go offline are suspended or disqualified. This is also why your node loses some data after being offline for a while. The unhealthy pieces for which the segment dropped below the repair threshold will be repaired and places on other nodes.
This system provides incredible reliability, even when large numbers of nodes go offline or disappears at the same time.
Since all of his nodes have different IPs couldn’t it be the case that he could hold all the pieces of some files. In this case a file would be lost forever.
That’s exactly the probability I calculated there. If that weren’t the case there would be no chance of file loss.
I guess technically I would need the number of subnets… but I don’t think we have those stats. Lets just lowball it and say it’s 3000 subnets.

Still well above the 11 9’s of durability.
I was going to do similar calc, but from the point of “what’s the probability of choosing at least 52 nodes of that single SNO on upload” (80 - 52 = 28 which is less than 29 needed to survive). So let’s say I don’t have to do that anymore ![]()
As Bright Silence has pointed out, if a segment is lost the error correction allows nodes to recreate the lost segment. It doesn’t need to find a copy of it to copy it somewhere else, it simply rebuilds it. You need to lose a lot of segments to make it so any one segment could not be rebuilt.
This is very true.
Even if a whole country is (temporarily, we hope) offline with 1000’ nodes lost, the network will cope.
thanks for this, very useful information