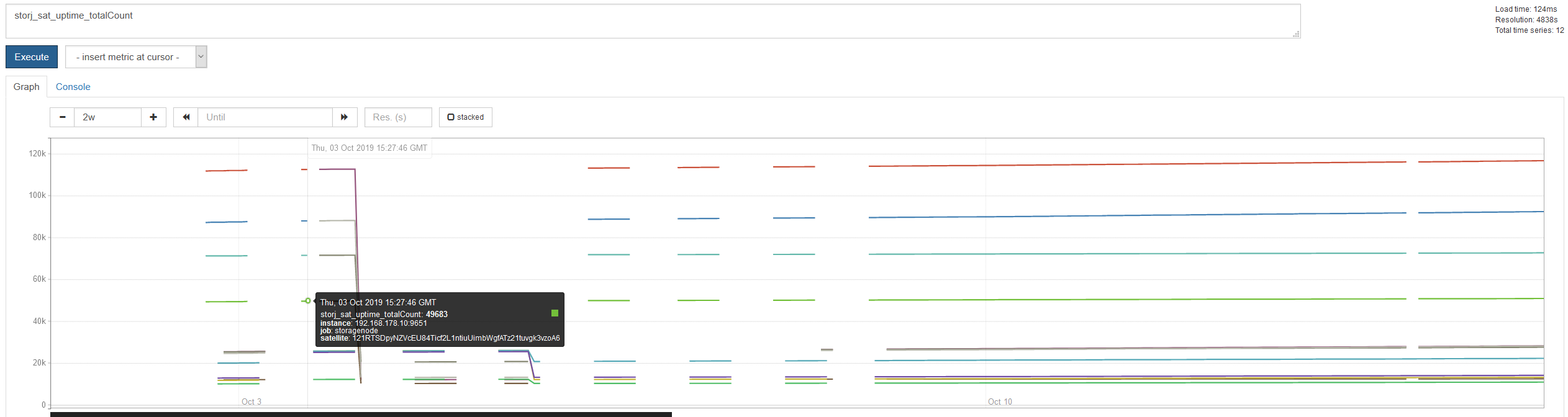
My node was offline for at most 15 minutes due to a server restart. After that the uptime reported by the satelites are not only differing a lot between the sattelites, they are also unreasonably low. I dropped from >99% to 93.6% on 121RT.
These are the stats of all 3 nodes saved to prometheus exported by the dashboard API:
How can it be that a node drops 4% uptime for a server restart that took at most 20 minutes but then recover almost all of that lost uptime score wtihin one day? Then the update hit and did cost me 2% uptime score again for what was a downtime of at most 10 minutes.
Even stranger when looking at the dashboard and seeing a different uptime score much lower than the API score of the prometheus exporter:
I can’t even find that uptime value in the API http://localhost:14002/api/satellite/118UWpMCHzs6CvSgWd9BfFVjw5K9pZbJjkfZJexMtSkmKxvvAW
Same goes for the audit score.
There are huge differences between the uptime and audit scores shown in the dashboard and the API
To make things even more interesting, the uptime score in the dashboard didn’t rise at all and is ridiculously low at 93.6% while the API uptime score is back to 99.9987%
The dashboard obviously uses the formula for calculating the uptime score:
uptime_score = successCount/totalCount
This however is wrong according to my knowledge and it should use the exposed score value of the API.
This is especially true since the successCount and totalCount do not even change at all:
The counts are lifetime counts so they won’t change much. The dashboard shows a lifetime percentage, which is a bit misleading. I agree that it should be switched to the score, but I believe there may already be some plans for that going by the design mockup posted here.
You are right, these are lifetime counts and therefore have very limited use.
My main concern here is the behaviour of the uptime score (which can only be obtained through the API) which falls heavily when just restarting a node and then recovers “quickly” (my nodes still haven’t recovered from one server restart and a node update a few days ago). Also the uptime score drop is heavily different between satelites and nodes which is a bit weird to me. One node drops 2% on one satellite, the next only 1%. The smallest and fastest node even didn’t drop noticeably at all. But since all 3 nodes run on the same host, they have the same downtimes.
It depends on how many uptime checks it actually failed during the downtime. These are kind of random right now. But this system is actually getting a rework anyway, so I wouldn’t worry too much about the uptime scores right now.