We much appreciate the members of the community that have been testing our US2 Beta. We wanted to reach out and define a specific use case that we would love to have further testing focused on.
S3 Backwards Compatibility
The US2 Beta has a hosted S3 compatible gateway and thus you should be able to use it with any service that can use S3. When using the hosted gateway the erasure coding occurs server side so a 1GB upload is only 1GB of edges from your computer and not 2.78GB when doing the erasure coding locally. This means you can upload to more services than before and at a much faster rate.
Please connect to services that are S3 compatible and report your findings. We are curious about any incompatibilities.
We’d also appreciate feedback on compatibility with the Amazon language bindings. If it’s S3 compatible, it should work with our gateway.
We’re really interested in early feedback. This has been a consistent request from customers and partners who haven’t wanted to run their own gateway. This new service will dramatically increase the number of use cases we can serve with the platform and will make it a lot easier to use.
Please let us know how it works for you and all feedback is wanted and welcome!
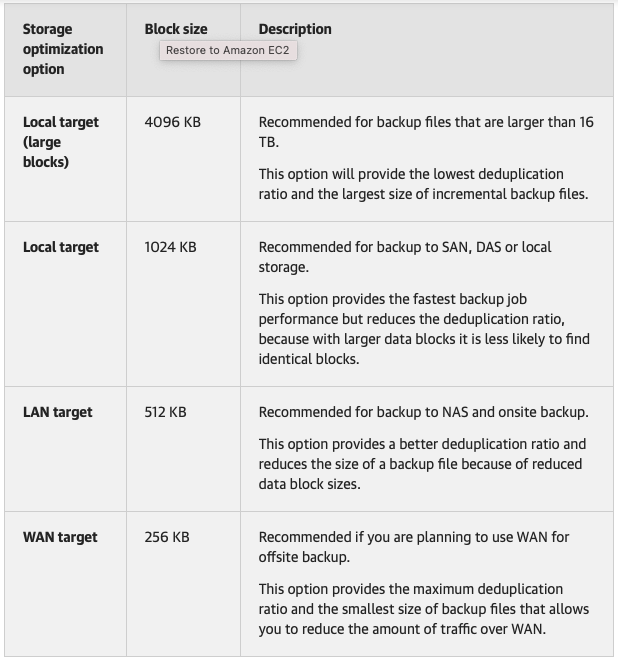
Fantastic, thank you so much for testing with Veeam. Do you know what block size you are using? Ideally use the largest size they offer (Local target (large blocks) 4096KB).
I tested a folder with large files (images) and a folder with many small files.
Large files (4 files, 8.66GB):
Uploaded: Capped my upload speed at 40Mbit/s.
Downloaded some files: Capped my download speed at 250Mbit/s.
Integration tests were done and worked fine. So no data loss or corruption. Delete versioning: This took far too long. Deleting 4 files (in chunks) took 18 min 45 sec. I have tested this 2 times with similar results.
Small files (8241 files, 218.1MB).
Uploaded: Capped my upload speed at 40Mbit/s.
Downloaded all files: Worked fine again.
Integration checks were done and worked fine. So no data loss or corruption.
Deletion of versioning: 1 minute 40 secs.
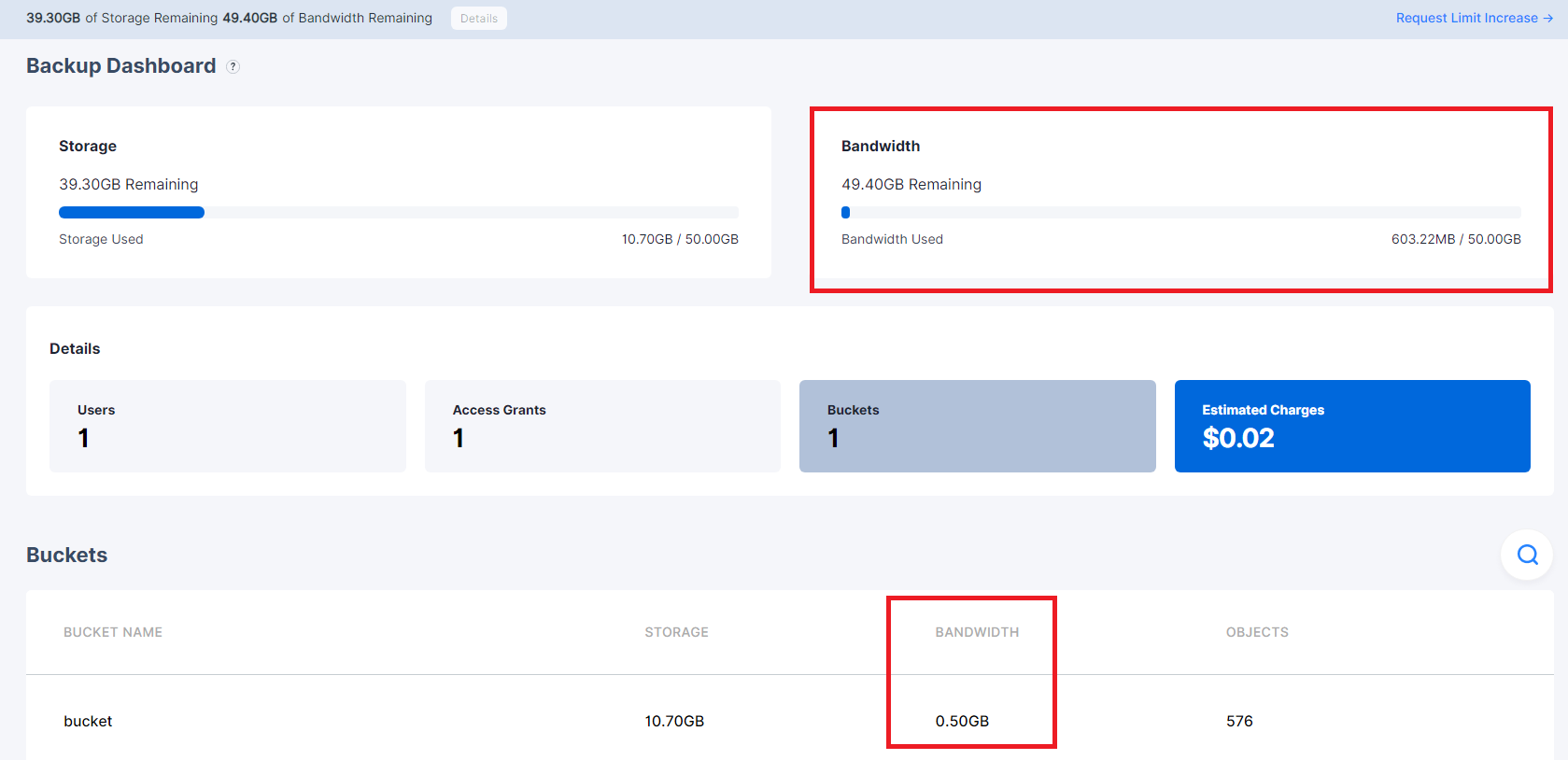
Bandwidth in the Dashboard:
I only have 1 bucket.
I left the Dashboard for about 15 minutes and did nothing.
The bandwidth of the project and bucket is not the same:
Currently uploading large dataset (around 4TV) with FileZilla Pro.
Large files, 30GB or larger.
Uploads are consistently saturating my upstream bandwidth and seem to be progressing well.
Will report back in a few days when I start the downloads but first impressions are very good with none of the bursty uploads I was seeing with the native Tardigrade integration.
Download bandwidth, also referred to as egress bandwidth, is priced per GB in increments of bytes downloaded. The calculation of download bandwidth price per byte is derived from the GB download bandwidth divided by the base 10 conversion of GB to bytes. The calculated number of bytes is then multiplied by the byte download bandwidth per byte price.
When an object is downloaded, there are a number of factors that can impact the actual amount of bandwidth used. The download process includes requests for pieces from more than the minimum number of storage nodes required. While only 29 pieces out of 80 are required to reconstitute an object, in order to avoid potential long-tail performance lag from a single storage node, an Uplink will try to retrieve an object from 39 storage nodes. The Uplink will terminate all incomplete downloads in process once 29 pieces are successfully downloaded and the object can be re-encoded. In addition, if a user terminates a download before completion, the amount of data that is transferred might exceed the amount of data that the customer’s application receives. This discrepancy can occur because a transfer termination request cannot be executed instantaneously, and some amount of data might be in transit pending execution of the termination request. This data that was transferred is billed as data download bandwidth.
Example
A user downloads one 1 TB file. Based on the long tail elimination, up to 1.3 TB of download bandwidth may be used. The 1.3 TB of download bandwidth is accounted for as 1,300,000,000 bytes. The price per GB is $0.045. The price per byte is $0.000000045. The total amount charged for the egress is $58.50.