@Alexey
Have you renamed/deleted the log file before start of the storagenode service?
Yes, I’ve deleted the log while the services where disabled.
Could your Synology run a docker?
My unit (rs819) cannot do it natively.
Usually inability to stop the service meaning this host (VM?) have a hardware issues. In this case it could be too slow storage or problems with RAM.
I will investigate storageissues further. While I was unable to comment, I’ve moved the VM to another host with known good RAM dimms
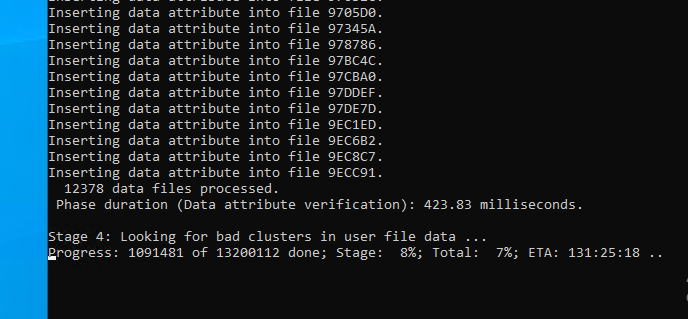
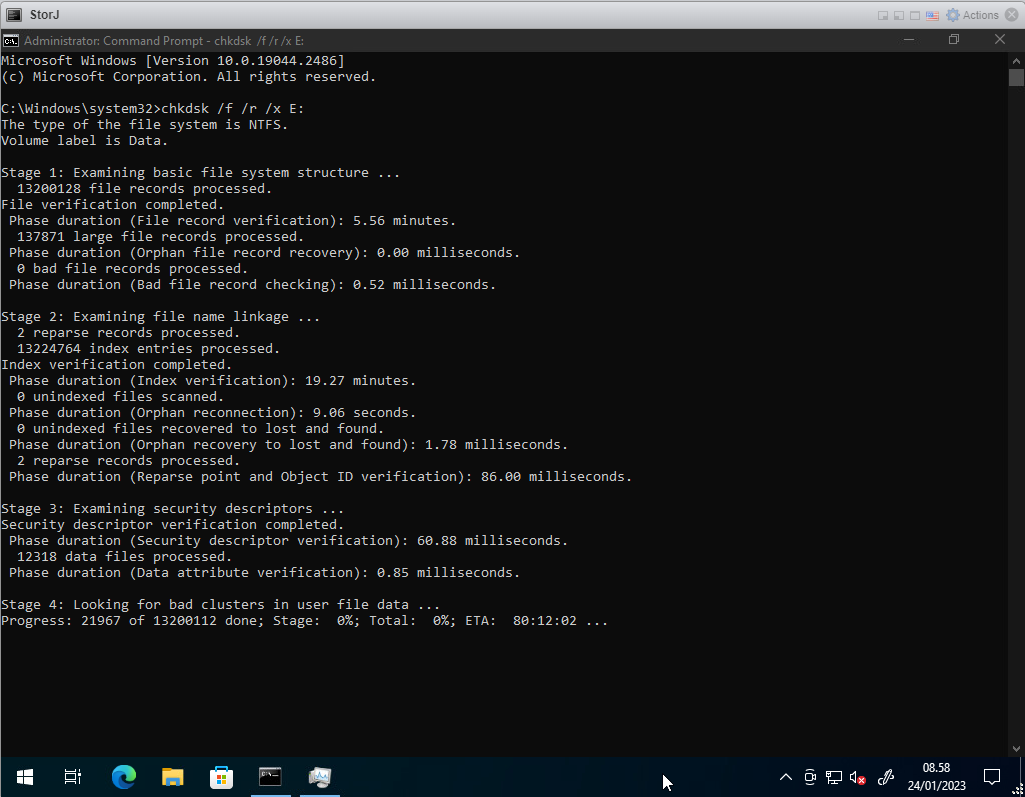
If you checked the filesystem from Windows and it fixed an issue, the service should start
normally and should be able to stop without any issues.
I will look into this, thanks
@vladro
2 gb of ram is enough when starting your node and during vetting period- so first 6-12 months. after this time its a good idea to add more ram, don’t forget that during some peak time synology will use more ram for native services- active backup, download station, btrfs optimization.
Will StorJ use the VMs RAM as cache, or the ISCSI target? Either way, the Synology is not at RAM capacity yet, and the VM has tonnes of RAM available.
my suggestion for your case - get bigger ram module (check your synology model- it should support 4 or 8 gb if its based on celeron/atom), be smart and don’t purchase original synology ram but a compatible one (it should cost u 10-15$)
Would love to - but I am on a ARM based synology. I plan on using local storage in the future, and not networked storage.
- are u using windows core as OS?
- still need to check windows event log- this error and behavior is related not to storj but to OS
- try stop storj service, delete original storegenode.exe and replace it with new one (for example 1.70) restart the service
No, regular old Win10. I will check up on the event log again - thanks. Good idea with the newer version - I can grab it from one of my other nodes. Will report back when I have additional findings