In this topic I hinted at a discrepancy between the total amount of piece data stored and B*h used as reported by satellites. Initially I thought it might be part of the same bug, but I later found out this predates the latest version and also shows up in my earnings calculator.
I didn’t want to throw out accusations without digging deeper first, so I mentioned there I would create a new topic after looking into this more. I have now collected the data required to make a more complete post around this issue and I personally can’t figure out what is causing this fairly significant difference. Here are my findings.
For this example node, the new disk space used graph shows the problem more clearly, so I will be using this updated node for most of the data.

This node is using 2.78TB of disk space, but reports only 1.98TB*d on the most recent day.
I’ve made some adjustments to my earnings calculator to add numbers to quantify the discrepancy. Let me start with some definitions.
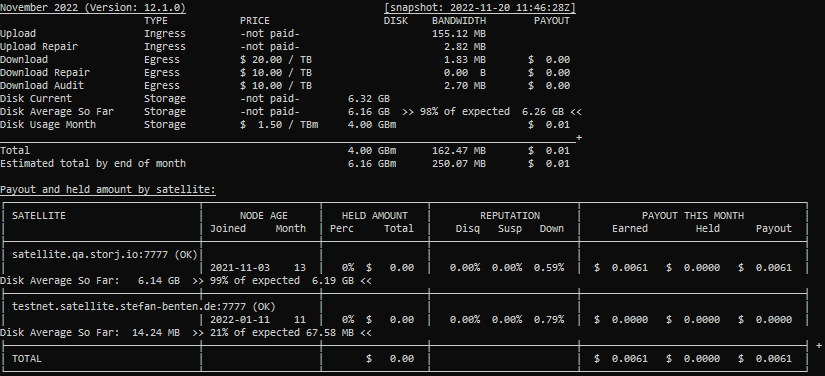
Disk Current: This is the sum of total in the piece_space_used table. It reflects the total amount of piece data stored on the node.
Disk Average So Far: This is the sum of at_rest_total (which is in B*h) from the storage_usage table, divided the number of hours passed in the current month. This reflects the average amount of data my node stored according to what the satellites have reported back.
expected: My own calculation of what the average should be based on Disk Current and ingress + deletes so far this month. Assuming roughly linear growth over the course of the month. The percentage shown displays how much of this expected storage the satellites actually report.
Here’s a screenshot from my adjusted calculator.

Only 68% of actual space used is accounted for by the satellites. Sometimes the reporting is a day behind, but at the moment that would only account for about at max 6% of missing data, not the 32% I’m missing here. And from the graph on the dashboard it is clear that all data for the 17th is already there and the 18th is about 8 hours old (UTC at time of screenshots).
I’ve looked into possible explanations, maybe trash is included, but that’s only 30GB, accounting for about 1% only. Possibly there is a difference between actual size of pieces and size on disk, because of sector size. But looking into that I see less than 0.5% difference there.

Note: I’ve blacked out parts of paths/commands that aren’t relevant
While the above node seems to be among the worst offenders, this is hitting other nodes as well. Some examples.



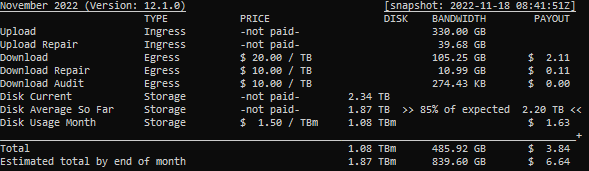
My largest node seems to be least impacted for now. Missing only about 7% which could probably partially be explained by satellite reporting running behind a little, though not entirely.
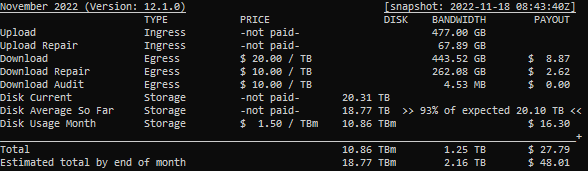
One last example. This node has been full for years and doesn’t really show the issue.

Note: I did not disable the file walker process and all nodes have been restarted due to updates in the past few days. So the total stored should be up to date.
If anyone from Storj Labs would like to look into this I can DM node ID’s, though it doesn’t seem isolated to specific nodes.