Hi
I have 5 nodes in the same subnet and they wont grows for about 1,5 years or so.
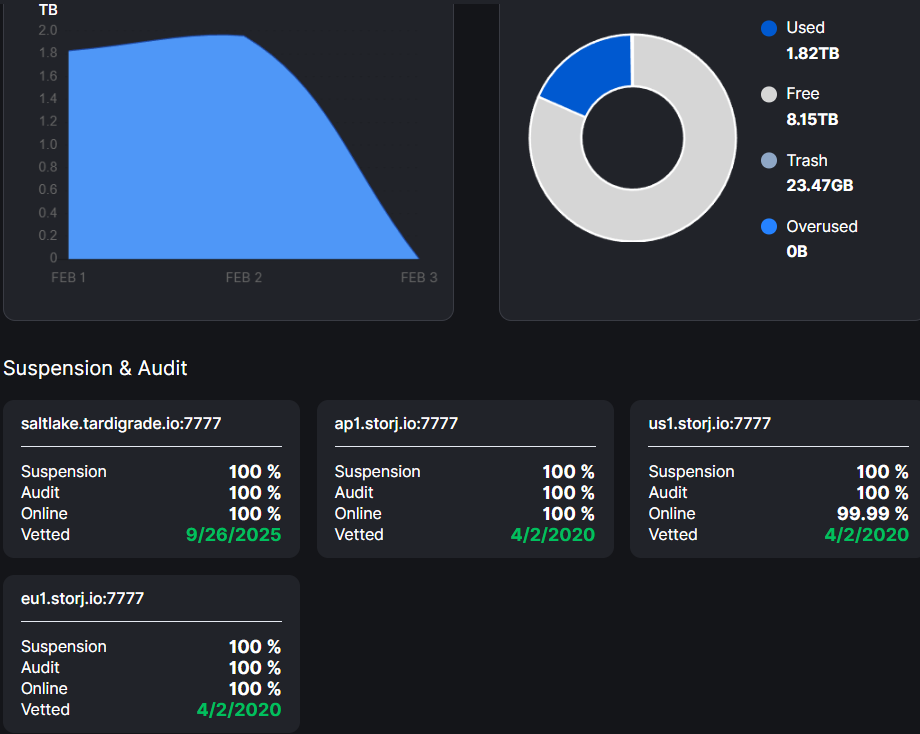
The disks itself about 12TB, the starting command includes -e STORAGE="10TB",
and in a config.yaml is storage.allocated-disk-space: 10.00 TB.
I had the bandwidth 200mbs from my ISP, but reduced to 100mbs cause it not get me any advantages in ingress.
3 or 4 of them had about 6-10TB of data, but when the Storj team deleted test data they become 2TB/each below and they’re not recovered till now.
Maybe I should check or add some extra settings?
No clues what should I do grew up.
Nothing unusual. Deletes balance out uploads at around 10TB node size.
Total volume of data being uploaded and deleted is dependent on customers of public network. You can’t control that.
Each node gets a fractional share of that, slightly skewed by node location. To get more of data – host more nodes on a diverse set of networks. Not really feasible for a casual operator with residential internet connection that issues one IP in a single subnet.
There are ways to get more – but they are on a spectrum of shadiness, so I won’t discuss them. There is plenty of evidence on this forum.
Therefore realistically you can only improve time to first byte, marginally improving the race wins. Node itself does not know if it wins or loses specific race, so the success rate script floating around here is of questionable use.
You can however enable debug logging and measure mean time it takes to process uploads and downloads, bucketize it into segment sizes, and see what is out of the ordinary or can be improved. For example, reducing latency to the first byte, or increasing bandwidth.
I noticed fixing bufferbload has dramatic effect on traffic – this is a secondary effect, measured over days – satellites today prefer faster nodes, apparently.
I’m not so much experienced user to dig that deep:)
I’ve spent a lot of time to migrate from Win to Linux earlier and have lack of skills to make a fine tune of the system - it’s been a great achievement for me to complete these journey with zero knowledge of the Linux system when I’ve started.
It’s too much expensive to hold the powerful dedicated server for Storj when there is no visible grows for a long period of time.
It will be more optimal to migrate the nodes to a lesser space disks and try to diverse to some new locations with different ISPs and with Raspberry carriers as a system as far I can see.
Then it makes no sense to run nodes: the idea behind the storj is to make use of already online but underused capacity.
Keeping server online just for storj cannot make sense — because otherwise storj could deploy nodes around the world on their own. They would not need operators.
So, if you have already online server — running nodes is a no-brainer, you help the planet and earn some money to offset some of the costs.
If you don’t need to run the server — then it’s a poor fit. Don’t run storagenodes.
It had sense in 2018-2021 when the capacity grows up.
And I had certain vision of the process - to elevate some skills also.
Now I’m stuck a little:)
It’s more easier and appropriate to get some Storj coins if you’re solid sure in a project, especially in these days, when Storj estimate 0,11$/coin. But looks like I’m not trying to find an easier way.
That was a highly subsidized stage to gain momentum. It could not have lasted forever.
This is real value for me too. I joined for this specific reason. Becuase my server just worked and I needed an adventure. And to help the earth. And to subsidize electricity cost of running it, which is out of hand $.50/kwh
Value of the token is not tied to success to a project in any way. Everything is in USD. Token is not a share in a company. It was used to bootstrap the company by creating capital out of thin air, but now it’s only a settlement instrument. I’m sure storj wants to get rid of it but can’t due to many technical and non technical reason.
If you want to gamble — you can buy tokens on the open market. No need to run nodes for that. But there are much better ways to gamble, where downside is bounded, unlike with the crypto token.
Yep, I’ve closed the mining and start a new more complicated adventure.
I had no infrastructure just a couple of nodes on Win machine, but it was fun and challenging to create an environment and elevate the server. But with time I’ve gathered too much unsolving tasks and get drained.
That way it no any reason to evolve the Storj as a platform not dealing with it as an operator.
It’s always should be a carrot for a donkey, to move donkey forward.
I’m practicing a different approaches. That is a path of samurai:)
All is above just a personal opinion of you and me.
It’s not about right or wrong, fool or wise, just to support the vision with some activity.
It’s not bitcoin; you’re not solving a mathematical find-the-needle-in-the-haystack problem in a speed competition.
It’s not chia; you’re not printing virtual lottery tickets on which future customer data might live.
It’s not Helium; you’re not putting up 5G networks that compete with visibility.
You’re storing real customer data, today, without any of the speculation. You get paid for all data in transit, in rest, and this “job security” is possible, because it’s a slow endeavor.
If you think of mining when you think of StorJ - then yes, I think you’d be much better off buying the coin and gamble. It is indeed on firesale right now
I’ve read about technology and I’m since of 2018 in Storj,
so thank you for trying to say something new.
Please try to read without trigger words.
The subject of a topic is about no grow of customer data in a long period of time.
I’ve tried to get some clue is that something my local problem or Storj settings that I can’t pass.
Have you tried searching the forum about this topic? We are getting these questions on a fairly regular basis, and the answers just don’t seem to be changing. Found three within 2 minutes: 1, 2, 3.
No, I have not search for an alternative topics on forum when I posted this.
I have seen the similar posts before and I have seen that some node operators got a couple of 6/8/10TB nodes as well.
So if I wouldn’t ask about a problem I will continue to overthink the problem and will waste a time to dig in a wrong way.
Growth comes and goes. Here’s a snapshot of my oldest node, where you can mostly ignore the spikes because of my fiddling around with the reporters. The most recent spike is from switching to hashstore and the space accounting now including the reclaimable space.
It’s the other way around — thats’s why you would dig: to gain such experience, and only if you are interested. Solving a specific optimization problem with constraints is the best (if not the only) way to learn about systems, regardless of a specific OS. And the payoff here is what gets discovered along the way, not a slightly better functioning node of course.
If you already knew what and how it would have been a boring job, not a learning opportunity.
If you are wondering about the graph on the left side, then perhaps your node didn’t get full reports from all satellites yet (you may check that when you switching between satellites).