Вот в логе заметил, что узел не пингуется и поэтому QUIC не включается:
2025-10-12T17:40:15Z WARN contact:service Your node is still considered to be online but encountered an error. {“Process”: “storagenode”, “Satellite ID”: “12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs”, “Error”: “contact: failed to ping storage node using QUIC, your node indicated error code: 0, rpc: quic: timeout: no recent network activity”}
Странно это. На этом же IP другой узел в Windows GUI - всё работает и пингуется.
Диск не такой уж и старый. 3 года ему всего. Причём торможение идёт, скорее всего, когда проверяется пинг (раз в час). Потом обновляется как обычно, а через час снова тормоза, и спустя какое-то время, опять всё резво.
Проверил на файлах чтение/запись: 150М/с - чтение, 100М/с - запись.
Если на QUIC внимание не обращать, и проверять дэшбоард как и раньше, раз в сутки/двое, то тогда всё “работает”.
А это не от возраста диска зависит, а от возраста узла. Чем больше данных, тем дольше занимают запросы. Еще зависит от качества кеширования и объема свободной памяти. Некоторые операционные системы могут кешировать довольно много данных, некоторые — почти совсем не умеют.
Пока я на своих узлах не заставил базы данных переместится на zfs special device, даже на 3-vdev of 4x-disk массиве дашбоард грузился несколько минут. А с ссд — пару секунд.
Диски отлично справляются с последовательным доступом. 150Мб/с маловато конечно но в переделах нормы.
Запросы в базы данных не последовательные. А произвольный доступ на механических дисках раз в 1000-10000 медленнее чем последовательный. Диск тратит больше времени мотая головками туда сюда чем читая данные. У ssd таких проблем нет, поэтому даже медленные ссд для произвольного доступа работают значительно лучше.
Умные файловые системы умеют располагать данные которые часто используются произвольно на ссд, а большие файлы которые читаются последовательно - на hdd.
Я имел в виду количество данных не на узле а в базах данных. Сравните размеры баз данных.
Оба узла на одном и том же компьютере?
Еще есть момент что если узел только что перезапустили, даже если обьем памяти для достаточен, там вначале вообще ничего не закешировано, и пока кеш постранично не всосет все данные, все будь медленно. Можно подождать и попробовать еще через пол часа. Если стало быстрее — то в этом причина. Если нет — то куча причин может быть -от stale data eviction до поведения файловой системы ОС.
Надо настроить в файреволе два правила - TCP и UDP на вход по номеру порта узла.
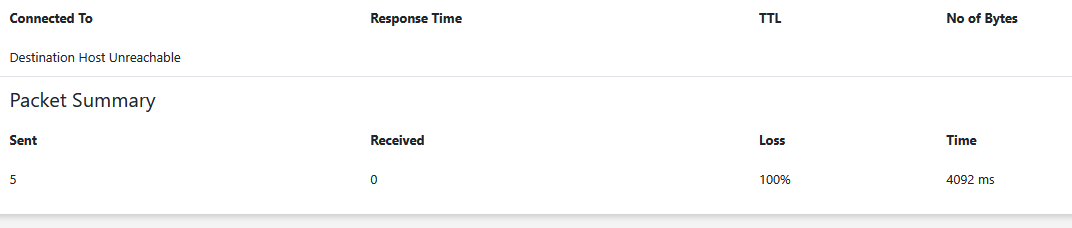
ICMP не используется сателлитами. У них PING это не ICMP ping, а сообщение DRPC.
Они должны работать сразу же. Вы можете попробовать указать IP адрес хоста в портах, иногда это помогает с QUIC, если у вас больше одной сетевой карты, т.е.
При указании явных параметров нода не запускается совсем.
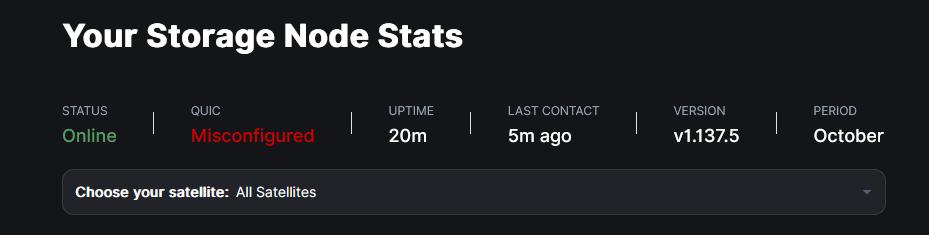
Что я смог пронаблюдать: раз в час идёт проверка по QUIC; длится она 10 минут (потому что пинг не проходит) и за это время узел практически не принимает и не отдаёт данные → падает аудит и онлайн, но пока не сильно.
Другими словами, узел не работает 10 минут каждый час.
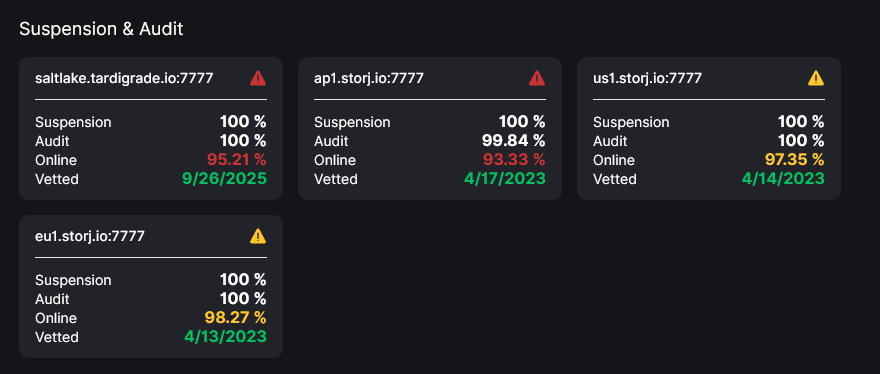
Audit не должен падать. Возможно, есть повреждённые данные или узел очень долго отвечает (там очень короткий таймаут после подтверждения, что запрос на аудит получен, потому что audit запрашивает килобайты кусочков, не весь кусочек). Так что, возможно, диск не успевает.
Online тоже падать не должен, если только узел не отвечает на запрос аудита совсем. Так что, возможно, есть ещё какие-то препятствия.
Что вы используете? Docker Desktop или что-то другое? Например, только последняя версия Rancher Desktop в состоянии работать с UDP, но это нестабильно. В podman сеть в принципе очень нестабильна и UDP там не работает точно.
И да, проверяется раз в час, потому что раз в час (по умолчанию) узел коннектится к сателлиту (check-in) и тот проверяет предоставленные данные, в частности - внешний адрес, пытаясь запросить по QUIC и если не вышло - по TCP.
Ищите проваленные GET_AUDIT, это 100% не QUIC.
Для online score эти скрипты:
Узнаете, когда ваш узел не ответил на запросы аудита, потом можно посмотреть логи всех устройств, роутера, брандмауэра, PiHole, узла и т.д. на эти даты и время, чтобы понять, что блокировало доступ.
Если у вас на роутере есть smart security или DDoS protection - выключите с концами, SOHO устройства не способны это делать правильно, не тот уровень.