I wonder why people using dedicated disk with hashstore? Wasn’t the reason to use it avoiding walking millions of files for space calculation? This problem doesn’t exist anymore with hashstore.
Hashstore is really just kicking the can down the road. Instead of deleting it all when it’s expired, it tries to limit io by deleting in small chunks, in the process, hanging onto large amounts of expired data.
I see that compaction triggers like every day all satellites in different time
1 Like
UPDATE: after 6h ago i made junction to free up space, during night I got additional 100gb free, so if HDD hot full, we can use this method.
Also I added hashstore.compaction.alive-fraction: 0.60 for bigger compaction.
I continued the node with --hashstore.compaction.alive-fraction=0.45 for a week, then 250GB difference is still remaining. However, because the compaction time was reduced (approx. 45 min per run, and once per day for the largest satellite) and there is 420GB free space in the multinode dashboard (+250GB in the singlenode), the ingress recovered.
My nodes have substantial ingress but also equivalent removal. Optimisation of the filesystem or optimisation of the opitions for the current bandwidth, this could be a new headache for us…
TBH, Still I don’t understand what is the exact issue.
In case we have discrepancies between real / reported space usage:
What would help me is the storage related metrics from the /metrics endpoint + the local data usage with du -sh.
We use the dedicated disk based space calculation, and didn’t notice any issue (yet).
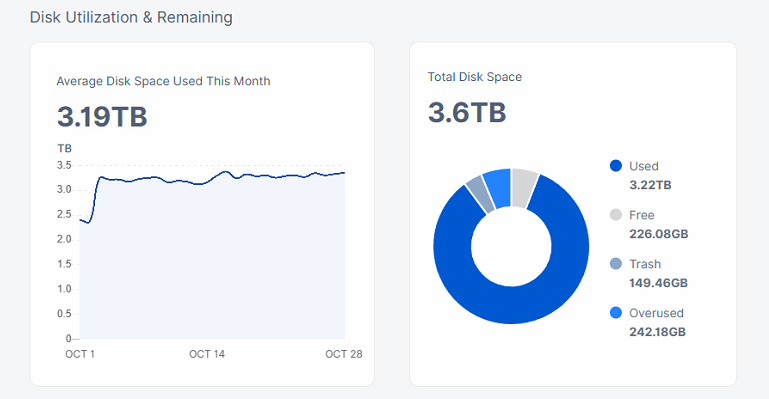
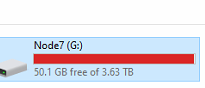
It hapened than on that node debug is active, I sended to support mail text file with metrics
node is 1.139.6 version
Only storj used, blobs folder is free, not trash in trash folder, no any temperate files.
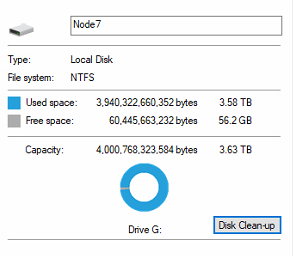
Elek, the issue is something like this:
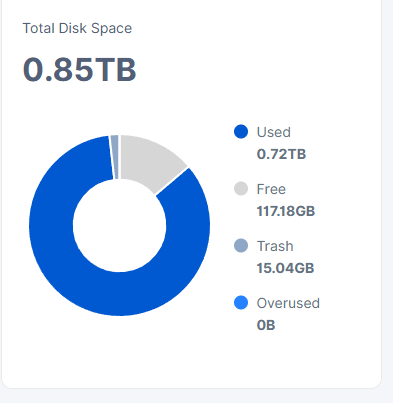
With this usage situation, I saw only 1-2GB ingress / day as the node is practically full. On the other hand the drive had around 70GB free space according to Windows. Similar to this:

If I restart the node, it shows around 24GB overused space and need to wait 2-3 days to get rid of it. (with the standard settings)
I tried the earlier mentioned options:
hashstore.compaction.alive-fraction: 0.75
hashstore.compaction.rewrite-multiple: 30
Maybe it was a mistake, as now I see a lot of compaction lines in the log, but some with errors:
2025-10-28T15:37:41+01:00 INFO hashstore compact once started {"satellite": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "store": "s0", "today": 20389}
2025-10-28T15:37:41+01:00 INFO hashstore compaction computed details {"satellite": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "store": "s0", "nset": 33992, "nexist": 33992, "modifications": false, "curr logSlots": 17, "next logSlots": 17, "candidates": [14, 1, 10, 5, 16], "rewrite": [1], "duration": "19.9222ms"}
2025-10-28T15:40:03+01:00 INFO hashstore records rewritten {"satellite": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "store": "s1", "records": 4871, "bytes": "0.8 GiB", "duration": "3m28.6145626s"}
2025-10-28T15:40:32+01:00 INFO hashstore hashtbl rewritten {"satellite": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "store": "s1", "duration": "29.0995351s", "total records": 397891, "total bytes": "67.9 GiB", "rewritten records": 4871, "rewritten bytes": "0.8 GiB", "trashed records": 0, "trashed bytes": "0 B", "restored records": 0, "restored bytes": "0 B", "expired records": 0, "expired bytes": "0 B", "reclaimed logs": 1, "reclaimed bytes": "1.0 GiB"}
2025-10-28T15:40:32+01:00 INFO hashstore compact once finished {"satellite": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "store": "s1", "duration": "3m57.9045989s", "completed": true}
2025-10-28T15:40:32+01:00 INFO hashstore finished compaction {"satellite": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "store": "s1", "duration": "1h36m5.8051463s", "stats": {"NumLogs":75,"LenLogs":"68.8 GiB","NumLogsTTL":8,"LenLogsTTL":"1.9 GiB","SetPercent":0.9868490186068709,"TrashPercent":0.03702630975619617,"TTLPercent":0.009398350939936344,"Compacting":false,"Compactions":0,"Today":20389,"LastCompact":20389,"LogsRewritten":77,"DataRewritten":"58.7 GiB","DataReclaimed":"76.2 GiB","DataReclaimable":"0.9 GiB","Table":{"NumSet":397891,"LenSet":"67.9 GiB","AvgSet":183273.68987989172,"NumTrash":32774,"LenTrash":"2.5 GiB","AvgTrash":83482.31939952401,"NumTTL":638,"LenTTL":"662.3 MiB","AvgTTL":1088540.2821316614,"NumSlots":1048576,"TableSize":"64.0 MiB","Load":0.3794584274291992,"Created":20389,"Kind":0},"Compaction":{"Elapsed":0,"Remaining":0,"TotalRecords":0,"ProcessedRecords":0}}}
2025-10-28T15:40:49+01:00 INFO hashstore records rewritten {"satellite": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "store": "s0", "records": 2286, "bytes": "0.7 GiB", "duration": "3m7.6728498s"}
2025-10-28T15:40:50+01:00 INFO hashstore hashtbl rewritten {"satellite": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "store": "s0", "duration": "1.335013s", "total records": 33992, "total bytes": "10.3 GiB", "rewritten records": 2286, "rewritten bytes": "0.7 GiB", "trashed records": 0, "trashed bytes": "0 B", "restored records": 0, "restored bytes": "0 B", "expired records": 0, "expired bytes": "0 B", "reclaimed logs": 1, "reclaimed bytes": "1.0 GiB"}
2025-10-28T15:40:50+01:00 INFO hashstore compact once finished {"satellite": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "store": "s0", "duration": "3m9.0517159s", "completed": false}
2025-10-28T15:40:50+01:00 INFO hashstore compact once started {"satellite": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "store": "s0", "today": 20389}
2025-10-28T15:40:50+01:00 INFO hashstore compaction computed details {"satellite": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "store": "s0", "nset": 33992, "nexist": 33992, "modifications": false, "curr logSlots": 17, "next logSlots": 17, "candidates": [54, 10, 5, 16, 14], "rewrite": [5], "duration": "6.5789ms"}
2025-10-28T15:43:00+01:00 INFO hashstore records rewritten {"satellite": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "store": "s0", "records": 2598, "bytes": "0.7 GiB", "duration": "2m9.5629425s"}
2025-10-28T15:43:00+01:00 INFO hashstore hashtbl rewritten {"satellite": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "store": "s0", "duration": "512.0783ms", "total records": 33992, "total bytes": "10.3 GiB", "rewritten records": 2598, "rewritten bytes": "0.7 GiB", "trashed records": 0, "trashed bytes": "0 B", "restored records": 0, "restored bytes": "0 B", "expired records": 0, "expired bytes": "0 B", "reclaimed logs": 1, "reclaimed bytes": "1.0 GiB"}
2025-10-28T15:43:00+01:00 INFO hashstore compact once finished {"satellite": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "store": "s0", "duration": "2m10.0912568s", "completed": false}
2025-10-28T15:43:00+01:00 INFO hashstore compact once started {"satellite": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "store": "s0", "today": 20389}
2025-10-28T15:43:00+01:00 INFO hashstore compaction computed details {"satellite": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "store": "s0", "nset": 33992, "nexist": 33992, "modifications": false, "curr logSlots": 17, "next logSlots": 17, "candidates": [10, 16, 14], "rewrite": [10], "duration": "18.9478ms"}
2025-10-28T15:43:58+01:00 INFO hashstore compact once finished {"satellite": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "store": "s0", "duration": "57.5310182s", "completed": false, "error": "hashstore: writing into compacted log: write E:\\hashstore\\121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6\\s0\\50\\log-0000000000000050-00000000: There is not enough space on the disk.", "errorVerbose": "hashstore: writing into compacted log: write E:\\hashstore\\121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6\\s0\\50\\log-0000000000000050-00000000: There is not enough space on the disk.\n\tstorj.io/storj/storagenode/hashstore.(*Store).rewriteRecord:1247\n\tstorj.io/storj/storagenode/hashstore.(*Store).compactOnce.func8:989\n\tstorj.io/storj/storagenode/hashstore.(*Store).compactOnce:1003\n\tstorj.io/storj/storagenode/hashstore.(*Store).Compact:707\n\tstorj.io/storj/storagenode/hashstore.(*DB).performPassiveCompaction:528"}
2025-10-28T15:43:58+01:00 INFO hashstore finished compaction {"satellite": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "store": "s0", "duration": "29m32.6103655s", "error": "hashstore: writing into compacted log: write E:\\hashstore\\121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6\\s0\\50\\log-0000000000000050-00000000: There is not enough space on the disk.", "errorVerbose": "hashstore: writing into compacted log: write E:\\hashstore\\121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6\\s0\\50\\log-0000000000000050-00000000: There is not enough space on the disk.\n\tstorj.io/storj/storagenode/hashstore.(*Store).rewriteRecord:1247\n\tstorj.io/storj/storagenode/hashstore.(*Store).compactOnce.func8:989\n\tstorj.io/storj/storagenode/hashstore.(*Store).compactOnce:1003\n\tstorj.io/storj/storagenode/hashstore.(*Store).Compact:707\n\tstorj.io/storj/storagenode/hashstore.(*DB).performPassiveCompaction:528", "stats": {"NumLogs":18,"LenLogs":"11.7 GiB","NumLogsTTL":6,"LenLogsTTL":"39.0 MiB","SetPercent":0.8813558354732052,"TrashPercent":0.01744189025099635,"TTLPercent":0.007737684648756158,"Compacting":false,"Compactions":0,"Today":20389,"LastCompact":20389,"LogsRewritten":13,"DataRewritten":"7.0 GiB","DataReclaimed":"10.0 GiB","DataReclaimable":"1.4 GiB","Table":{"NumSet":33992,"LenSet":"10.3 GiB","AvgSet":326818.6434455166,"NumTrash":495,"LenTrash":"209.7 MiB","AvgTrash":444140.73535353533,"NumTTL":116,"LenTTL":"93.0 MiB","AvgTTL":840785.6551724138,"NumSlots":131072,"TableSize":"8.0 MiB","Load":0.25933837890625,"Created":20389,"Kind":0},"Compaction":{"Elapsed":0,"Remaining":0,"TotalRecords":0,"ProcessedRecords":0}}}
2025-10-28T15:43:58+01:00 ERROR hashstore compaction failed {"satellite": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "error": "hashstore: writing into compacted log: write E:\\hashstore\\121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6\\s0\\50\\log-0000000000000050-00000000: There is not enough space on the disk.", "errorVerbose": "hashstore: writing into compacted log: write E:\\hashstore\\121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6\\s0\\50\\log-0000000000000050-00000000: There is not enough space on the disk.\n\tstorj.io/storj/storagenode/hashstore.(*Store).rewriteRecord:1247\n\tstorj.io/storj/storagenode/hashstore.(*Store).compactOnce.func8:989\n\tstorj.io/storj/storagenode/hashstore.(*Store).compactOnce:1003\n\tstorj.io/storj/storagenode/hashstore.(*Store).Compact:707\n\tstorj.io/storj/storagenode/hashstore.(*DB).performPassiveCompaction:528"}
On the other hand, it used up all the available space on the disk, but still reporting 112 GB available space in the dashboard:

curl -s 127.0.0.1:14002/api/sno/ | jq .diskSpace
{
"used": 1818825588614,
curl -s 127.0.0.1:5999/metrics | grep used_space | grep recent
used_space{scope="storj_io_storj_storagenode_monitor",field="recent"} 2.214514168582e+12
If this shall represent the same value then this looks like a discrepancy to me.
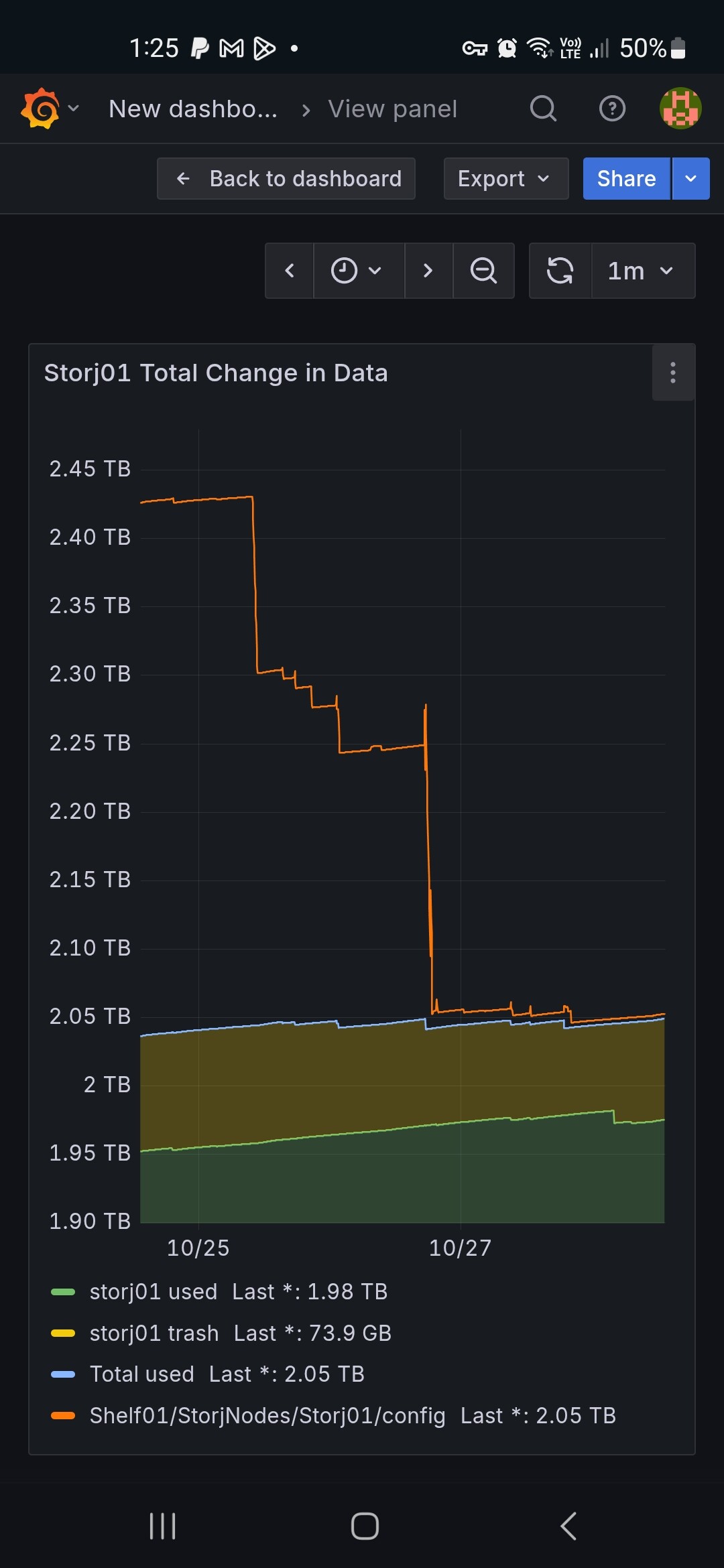
Disk usage reported by Storj API vs Used space reported by OS.
Large drops in OS Used Space are after changing
hashstore.compaction.alive-fraction
hashstore.compaction.rewrite-multiple
The issue has been discussed in this thread as well:
after update to 1.139.6 nodes more showing like useful data only, not all file sizes together like it should be, so all overhead is hidden. I gone to this conclusion because most of my 100+ nodes show used space and used space reported by satellite almost the same, but we don’t live in the ideal world. it like in you video that shown file sizes and real useful size inside. Nodes looks like show useful size inside of files combined together. Also after I made restart to all servers, my used space added almost 10tb.
Can someone explain me why, my node rise, while it show me 0 ingress, but it consuming space on HDD.
Yesterday I made a junction for 1 satellite folder to free up space. it is 75GB.
In morning i see that now there is 108 GB free. Ok I left it to make more compaction, but now there is only 8.8GB free. Stats show that there was 0 ingress in last 2-3 days. so HOW? unfortunately i have warn level there, so no logs about ingress or egress.
Hashstore popcorn effect. ![]()
I was enthusiastic about hashstore. But I’m seeing a lot of free-space/full-HDD problems. And things like power-loss seem way more likely to cause serious/fatal issues compared to piecestore (where typically you’d just lose a couple .sj1 files and still be fine)
I’m sure they’ll work out the problems eventually. But I also kinda hope I’m last-on-the-list for the forced active migration ![]()
Is this space included in the amount of space used?
Maybe the ingress is not registered in the database due to some errors like “database is locked”?
It’s also possible that you are experiencing compaction, which by default creates up to 10 files of 1 GB each simultaneously for each satellite until the compaction is complete.
You may also try to check the ingress usage on the debug port or via storagenode API.
Perhaps it’s better to enable a dedicated disk feature:
Do you see any compaction error lines in the log?
Like this:
2025-10-28T15:43:58+01:00 INFO hashstore compact once finished {"satellite": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "store": "s0", "duration": "57.5310182s", "completed": false, "error": "hashstore: writing into compacted log: write E:\\hashstore\\121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6\\s0\\50\\log-0000000000000050-00000000: There is not enough space on the disk.", "errorVerbose": "hashstore: writing into compacted log: write E:\\hashstore\\121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6\\s0\\50\\log-0000000000000050-00000000: There is not enough space on the disk.\n\tstorj.io/storj/storagenode/hashstore.(*Store).rewriteRecord:1247\n\tstorj.io/storj/storagenode/hashstore.(*Store).compactOnce.func8:989\n\tstorj.io/storj/storagenode/hashstore.(*Store).compactOnce:1003\n\tstorj.io/storj/storagenode/hashstore.(*Store).Compact:707\n\tstorj.io/storj/storagenode/hashstore.(*DB).performPassiveCompaction:528"}
I ask it, becouse I see that when the compaction finished with this error, the space reservation (files mentioned by Alexey) is created but not deleted due to the error. So my drive became full as well.
I changed back my settings to default and my drive’s free space increased back as soon as one single compaction completed sucessfully, even though it did not reclaimed any space. So I guess that the “cleanup” process happens only when the compaction finished successfully.
Yes i fount that compaction is out of space, I cant imagen why compaction process need 90gb of TMP space for 4tb HDD?
That is strange, becouse my drive had only 7GB free space and that single compaction was able to run and finish sucessfully. But it wanted to compact only a single log file. Maybe your compaction wanted to do more log files at once and the 90GB space was not enough for that…
Based on Elek’s video, maybe if you change the setting to hashstore.compaction.rewrite-multiple: 1
it will use the least amount of space for compaction and delete all the unfinished files as well, so you can have back the lost space…
1 Like