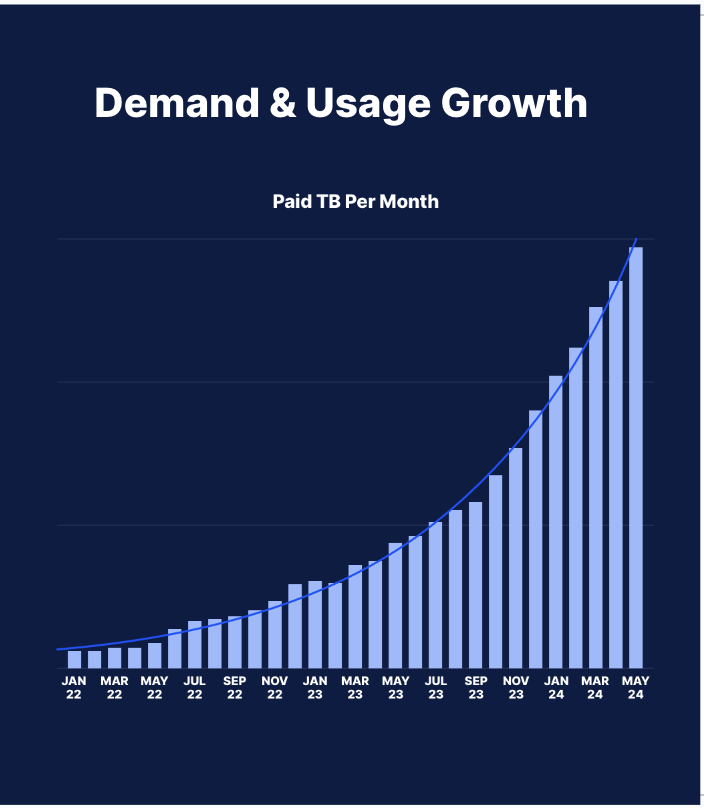
The Storj network is experiencing a pivotal transition from an innovative concept to a thriving platform, with paid storage growing at ~12%+ monthly and multiple 10+ PB prospects in active testing. This growth necessitates strategic expansion of our network capacity, performance, and geographic distribution.
To address these needs, we’re implementing changes to incentivize proactive capacity expansion. These modifications aim to increase our total node count, enhance node connectivity and performance, and optimize geographic distribution across the network.
This document outlines our Storj Network Growth Plan, detailing these strategic changes and seeking community feedback. Our goal is to build a robust network capable of meeting evolving customer demands while providing enhanced opportunities for node operators. Your input is crucial as we collaboratively shape the future of Storj.
Approach
Our strategy builds on historic success using synthetic data to encourage node growth and involves a multi-faceted approach. We’ll focus on regional capacity targets, a process for ongoing data upload and management, and targeted incentivisation to drive growth in areas where it’s needed most.
Important aspects:
- Churned, suspended, delinquent, etc. customers will have their data and account deleted on an ongoing basis according to our internal policies and procedures for doing so, but not held for node incentivisation purposes (as has been done in the past).
- Synthetic data will continue to be uploaded with the SLC satellite only.
- The amount of synthetic data maintained on the network will be triangulated per region by a combination of the following: 2-3 months worth of projected growth targets, 2-3 months of historical growth, and growth required to support the network in a new region with sufficient capacity and number of nodes to be performant and durable.
- Since network performance has a material impact on success with customers, we have improved our upload algorithms to better incentivize fast nodes by placing them in direct competition with other nodes with the losers having the upload canceled. We intend to eventually provide this data in order to inform operators about the performance of their node enabling them to better optimize their setup.
- Synthetic data will use a time-to-live (TTL). The data in the network will be uploaded continuously and will be adjusted by changing the upload rate, the time the data is retained, the size of the data, etc. to better match expected customer onboarding and storage patterns.
- Because of the continual uploading and TTLing of the data synthetic data will continuously be deleted, and nodes will no longer be able to store synthetic data for the long term in an archive-like fashion. Only customer use cases will be long term storage. This will mean that our fastest nodes don’t just fill up and stay full with synthetic data. And that in order to be successful nodes will need to stay performant and “win races” with other nodes to avoid long tail cancelation
- The switch to TTL synthetic data will also allow us to remove synthetic data without having to go through the garbage collection process, improving efficiency of the network as well as node economics.
- To create “regional” incentives, we will upload synthetic data using specific placements (geographic or other) to encourage node growth based on sales projections, prospects, or company strategy.
- We are updating the minimum requirements for a storage node to more accurately reflect the profile of a successful node on the network. This update will be based on actual customer use cases and usage patterns such that the aggregate network performance meets customer needs.
Expected outcomes
- Sufficient capacity and resources in place to handle anticipated growth in paid customer data
- Nodes ready and incentivized according to appropriate customer use cases
- Greater network performance across different regions
- Increased participation and contribution from node operators in high-demand regions
- Improved ability to meet the diverse needs of our global customer base
Capacity targets
As of June 25, 2024. Targeted amount of synthetic data.
| Placement | Current | Target | Reasoning |
|---|---|---|---|
| Global | 11 PB | 20 PB | Large expected deals |
| U.S. | 0 PB | 5 PB | 3 month growth target |
| Europe | 0 PB | 2 PB | 3 month growth target |
| South America | 0 PB | 1 PB | Bootstrapping network |
| APAC | 0 PB | 1 PB | Bootstrapping network |
| India | 0 PB | 1 PB | Bootstrapping network |
Conclusion
By implementing this Storj Network Growth Plan, we aim to proactively address anticipated growth in paid customer data, ensure optimal network performance, and strengthen our position as a leading distributed storage solution provider. Our targeted approach to capacity allocation, combined with strategic incentivization and continuous monitoring, will enable us to meet the evolving needs of our customers and strengthen our partnerships with storage providers/node operators while fostering sustainable growth across the Storj network.
Please see the FAQs below, but let us know if there are additional questions, concerns, or feedback.
- The Storj Team
FAQ
- Does this apply to the commercial operator program?
- No. That network has other options available to incentivize growth, but might adopt its own form of synthetic load for testing and vetting purposes.
- Won’t uploading test data by using IP based geolocation only incentivize operators to leverage VPNs to get the data rather than encouraging real growth in those regions?
- We won’t know until we try it, but yes, we believe that initially a lot of nodes will try this approach. Because data is constantly replaced, the nodes have to continue to win races against each other, with nodes actually located in the area having an advantage over VPN’d nodes. Over time the data should concentrate on those serving the area best which should be local nodes. We can add additional checks or adapt this strategy over time as we learn more.