I would like to setup email alerts for my storage nodes. It turns out the storage node already has a Prometheus endpoint. It is running on the debug endpoint /metrics. If you haven’t set the debug endpoint please visit Guide to debug my storage node, uplink, s3 gateway, satellite
I have already a Prometheus instance running and Grafana inclusive email alerts. Here are my configs:
docker-compose.yaml
version: "3.3"
services:
prometheus:
restart: unless-stopped
user: 993:991
ports:
- 9090:9090/tcp
image: prom/prometheus
volumes:
- /mnt/ssd/eth/prometheus:/prometheus
command:
- --storage.tsdb.retention.time=31d
- --config.file=/prometheus/prometheus.yaml
grafana:
restart: unless-stopped
user: 993:991
ports:
- 3000:3000/tcp
image: grafana/grafana
volumes:
- /mnt/ssd/eth/grafana:/var/lib/grafana
command:
- -config=/var/lib/grafana/grafana.ini
prometheus-exporter:
restart: unless-stopped
user: 993:991
ports:
- 9100:9100/tcp
image: quay.io/prometheus/node-exporter
volumes:
- /:/host:ro,rslave
command:
- --path.rootfs=/host
prometheus.yaml
global:
scrape_interval: 15s # By default, scrape targets every 15 seconds.
scrape_timeout: 10s
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
- job_name: 'prometheus-exporter'
static_configs:
- targets: ['prometheus-exporter:9100']
- job_name: 'storagenodetest'
metrics_path: /metrics
static_configs:
- targets: ['localhost:12019']
- job_name: 'storagenode1'
metrics_path: /metrics
static_configs:
- targets: ['localhost:13019']
- job_name: 'storagenode2'
metrics_path: /metrics
static_configs:
- targets: ['localhost:13029']
grafana.ini
[smtp]
enabled = true
host = smtp.gmail.com:587
user = <my gmail address>
password = <create new google app passwords>
;cert_file =
;key_file =
skip_verify = true
from_address = <my gmail address>
from_name = Grafana
# EHLO identity in SMTP dialog (defaults to instance_name)
;ehlo_identity = dashboard.example.com
[server]
root_url = http://localhost:3000
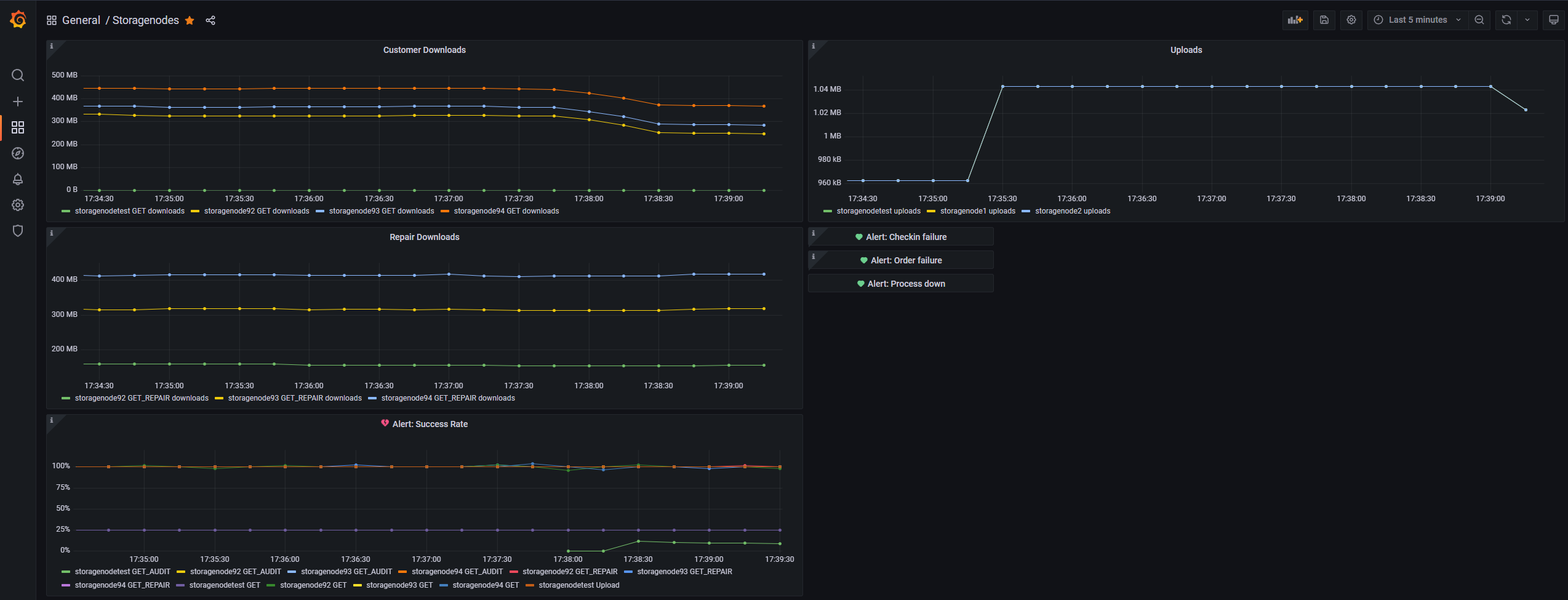
Up next we need a Grafana dashboard with email alerts. Let’s start with a first MVP. I am running multiple storage nodes and I want the email alert to tell me which node I need to fix. The trigger for the email alert doesn’t matter for this first MVP.
In a second step I would like to brainstrom with all of you which email alerts we need. For each email alert we also have to specify which data we need.
More than 5% audit failures (GET_AUDIT failed vs sucess)
More than 2 pending audits (GET_AUDIT started vs success + failed)
Audit score lower than 1
Suspension score lower than 1
Node process not running
Please write down which email alerts you want to see
The third step will be to expose the data we need for these email alerts. To be honest I will not have the time to make all the code changes myself. Instead my intension is to demonstrate how to do it and hopefully it is easy enough so that you can continue to keep the ball rolling. Ideally we have a living Grafana dashboard at the end that gets improved by the community over time.