I’m mostly using Prometheus to monitor stuff and was in need for storj exporter to monitor things like audit counts and uptimes per satellite, data as reported by storagenode etc..
So I made one:
I use metrics queries like storj_sat_audit_successCount{instance=~"$node.*"}
and if panel options are set as below it will generate a panel per node.
You could probably show per satellite graphs for multiple nodes on one graph as well using the query above so that it would plot 8 graphs for 2 nodes.
I am planning to support multiple nodes on the dashboard.
I added some missing metrics available in SN api and refactored some repeating code. Also aggregated most metrics by adding labels to metric group instead of having separate metric for each item.
I noticed 100+ downloads on docker hub so I’m going to keep both old metrics and new aggregated metrics until at least v1.0.0 release as this would break existing dashboards. Please switch to new metrics names/labels until then.
Working as expected, thanks a lot for putting this together! Hopefully Storj provides good documentation for the Storage Node API going forward to utilize for this. I tried enabling the debug port as per the town hall Q/A suggestion but the metrics being exposed are not in this type of format so were not really usable for ingestion into Prometheus, but this solves that problem.
I have a systemd service built for the standalone script and just making sure that it works properly then probably submit a PR if you want it. Pretty simple but saves some digging and testing for anyone wanting to use the standalone script.
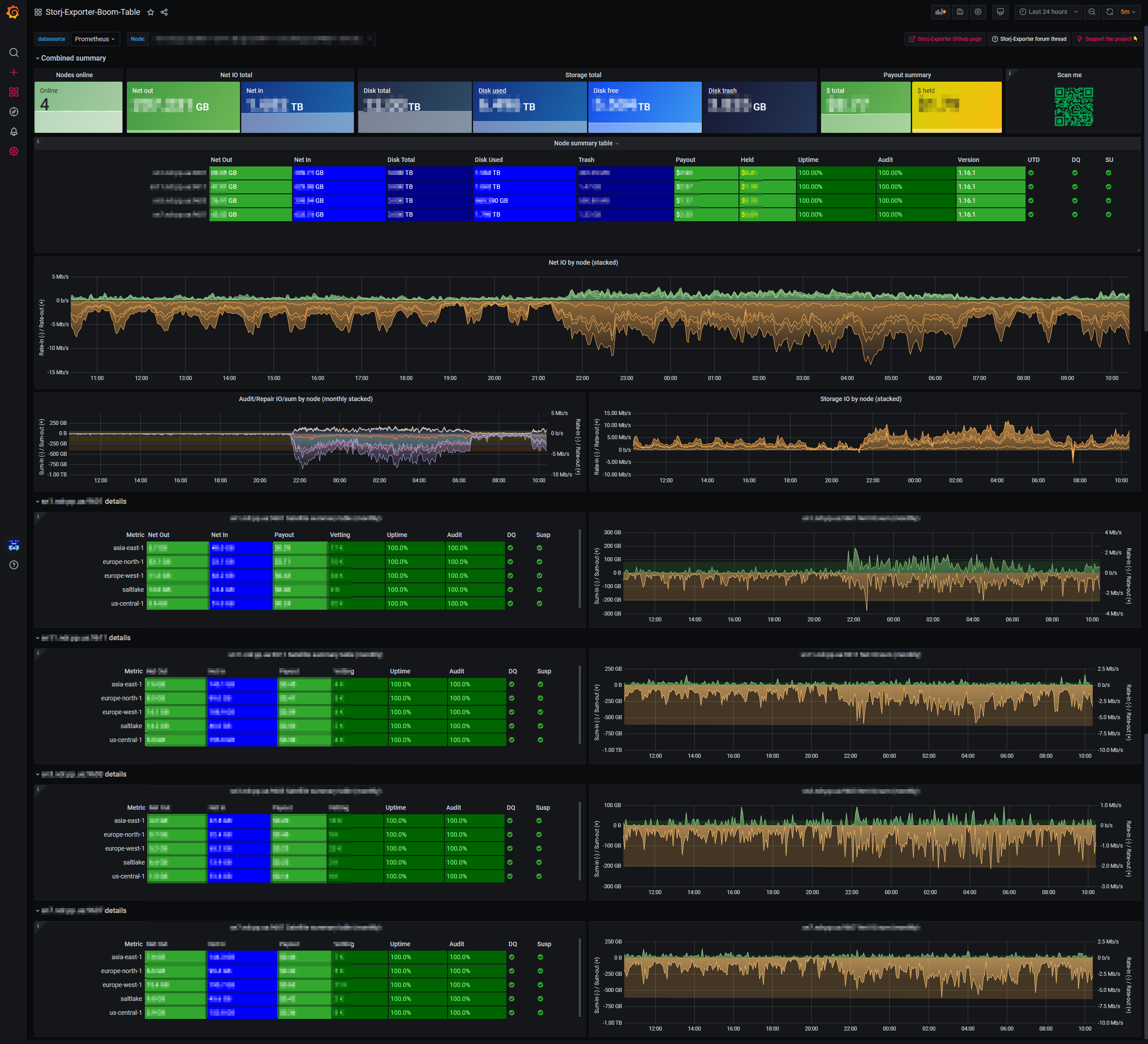
I just published Grafana Storj Exporter dashboard that I use with this exporter. It took a while to figure out the units and formulas for api numbers and some bits might still be off but most items seem accurate. Do not rely on Earnings tile much as I only got 1 payout so far will confirm on next round.
Storj-exporter Grafana dashboard to visualise Storj-Exporter metrics for multiple Storj storage nodes.
Also there’s a slight problem if you run multiple nodes on the same host (same ip, different ports) in the details view as those get combined to one node:
Thanks. Interestingly this only changed some graphs and even that not perfectly (10m scrape interval, 60m rate interval in graph):
Looks like I should change my scrape interval to 5 minutes and check again after a while.
Edit: With scrape interval 5 minutes it works correctly. With 10 minutes not even the graph in prometheus directly was smooth so maybe it has something to do with the exporter?
It seems prometheus treats metrics > 5m old as stale by default. For prometheus v2+ you can override this interval with --query.lookback-delta=5m commandline option. That should help with the graphs but will also delay the graph showing the node stopped reporting.
In general they recommend to keep scrape interval to < 2m with default lookback-delta=5m which probably means you want to set lookback-delta=25m with 10m scrapes… I didn’t test this though and not sure if this is a good idea.
For your other problem try to change $node variable regex to /.*/ instead of /([^:]+):.*/
This will render ports in $node variables and should fix your issue.
The reason I strip the port is because I’m using other node-exporter and cadvisor with this same dashboard and each exporter has a different port for the same host.
Oh that is interesting, thanks a lot, I didn’t think about that.
Scraping that often will make the database quite big if I want to keep my whole stats for a year… Have to check the links very carefully and think about how I want to set up my system…
For your other problem try to change $node variable regex to /.*/ instead of /([^:]+):.*/
This will render ports in $node variables and should fix your issue.

 so I’m going to keep both old metrics and new aggregated metrics until at least v1.0.0 release as this would break existing dashboards. Please switch to new metrics names/labels until then.
so I’m going to keep both old metrics and new aggregated metrics until at least v1.0.0 release as this would break existing dashboards. Please switch to new metrics names/labels until then. will confirm on next round.
will confirm on next round.




